 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual SFT Matches Multimodal RLHF with Negative Supervision
Paper and Code
Nov 22, 2024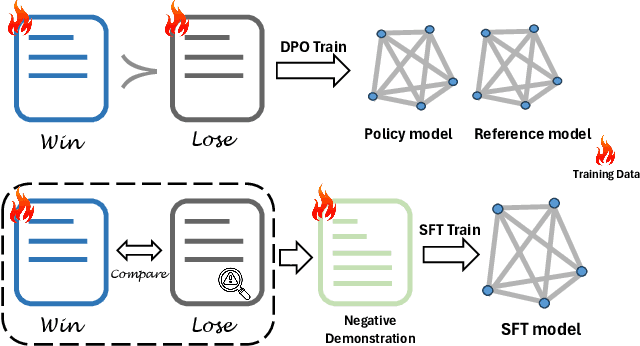
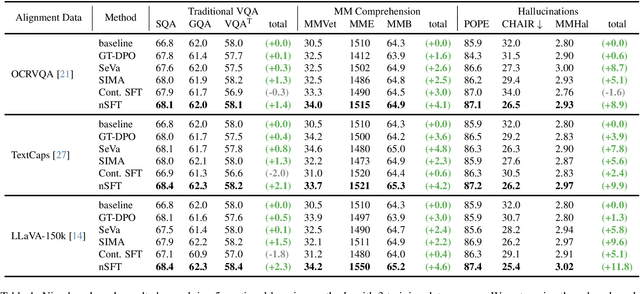
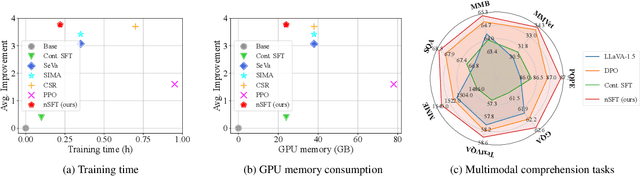
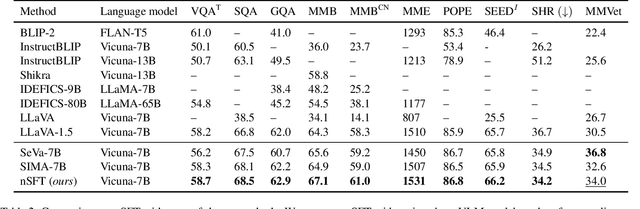
Multimodal RLHF usually happens after supervised finetuning (SFT) stage to continually improve vision-language models' (VLMs) comprehension. Conventional wisdom holds its superiority over continual SFT during this preference alignment stage. In this paper, we observe that the inherent value of multimodal RLHF lies in its negative supervision, the logit of the rejected responses. We thus propose a novel negative supervised finetuning (nSFT) approach that fully excavates these information resided. Our nSFT disentangles this negative supervision in RLHF paradigm, and continually aligns VLMs with a simple SFT loss. This is more memory efficient than multimodal RLHF where 2 (e.g., DPO) or 4 (e.g., PPO) large VLMs are strictly required. The effectiveness of nSFT is rigorously proved by comparing it with various multimodal RLHF approaches, across different dataset sources, base VLMs and evaluation metrics. Besides, fruitful of ablations are provided to support our hypothesis. We hope this paper will stimulate further research to properly align large vision language models.