 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReSGA: A Large Tail Risk Model for Learning Value-at-Risk and Expected Shortfall
Jun 03, 2026Learning Value-at-Risk (VaR) and Expected Shortfall (ES) is important for managing financial risks effectively. Existing approaches with limited parameters are vulnerable to model misspecification in the era of big data. To address this limitation, we propose a large tail risk model, the retrieval-enhanced self-grouping autoencoder (ReSGA), which is designed with millions of parameters to exploit the rich cross-sectional dependence and long-term temporal dynamics of assets using their characteristics. Applied to monthly US equity returns from 1926 to 2023 with 153 firm characteristics, ReSGA outperforms twelve econometric and machine learning competitors in terms of out-of-sample loss and statistical backtesting. In addition, its forecast advantages can translate into significant economic gains from long-short decile portfolios that are constructed by a new size-enhanced left-side momentum strategy. To clarify the role of complexity, we further conduct a systematic scaling analysis and demonstrate that improvements in joint VaR-ES forecasting are primarily driven by data complexity rather than model complexity. Finally, our analyses of group-importance and transfer-learning exhibit the interpretability and cross-market generalizability of ReSGA.
Enhancement of price trend trading strategies via image-induced importance weights
Aug 16, 2024



We open up the "black-box" to identify the predictive general price patterns in price chart images via the deep learning image analysis techniques. Our identified price patterns lead to the construction of image-induced importance (triple-I) weights, which are applied to weighted moving average the existing price trend trading signals according to their level of importance in predicting price movements. From an extensive empirical analysis on the Chinese stock market, we show that the triple-I weighting scheme can significantly enhance the price trend trading signals for proposing portfolios, with a thoughtful robustness study in terms of network specifications, image structures, and stock sizes. Moreover, we demonstrate that the triple-I weighting scheme is able to propose long-term portfolios from a time-scale transfer learning, enhance the news-based trading strategies through a non-technical transfer learning, and increase the overall strength of numerous trading rules for portfolio selection.
FinEval: A Chinese Financial Domain Knowledge Evaluation Benchmark for Large Language Models
Aug 19, 2023Large language models (LLMs) have demonstrated exceptional performance in various natural language processing tasks, yet their efficacy in more challenging and domain-specific tasks remains largely unexplored. This paper presents FinEval, a benchmark specifically designed for the financial domain knowledge in the LLMs. FinEval is a collection of high-quality multiple-choice questions covering Finance, Economy, Accounting, and Certificate. It includes 4,661 questions spanning 34 different academic subjects. To ensure a comprehensive model performance evaluation, FinEval employs a range of prompt types, including zero-shot and few-shot prompts, as well as answer-only and chain-of-thought prompts. Evaluating state-of-the-art Chinese and English LLMs on FinEval, the results show that only GPT-4 achieved an accuracy close to 70% in different prompt settings, indicating significant growth potential for LLMs in the financial domain knowledge. Our work offers a more comprehensive financial knowledge evaluation benchmark, utilizing data of mock exams and covering a wide range of evaluated LLMs.
Variance Control for Distributional Reinforcement Learning
Jul 30, 2023



Although distributional reinforcement learning (DRL) has been widely examined in the past few years, very few studies investigate the validity of the obtained Q-function estimator in the distributional setting. To fully understand how the approximation errors of the Q-function affect the whole training process, we do some error analysis and theoretically show how to reduce both the bias and the variance of the error terms. With this new understanding, we construct a new estimator \emph{Quantiled Expansion Mean} (QEM) and introduce a new DRL algorithm (QEMRL) from the statistical perspective. We extensively evaluate our QEMRL algorithm on a variety of Atari and Mujoco benchmark tasks and demonstrate that QEMRL achieves significant improvement over baseline algorithms in terms of sample efficiency and convergence performance.
Big portfolio selection by graph-based conditional moments method
Jan 27, 2023



How to do big portfolio selection is very important but challenging for both researchers and practitioners. In this paper, we propose a new graph-based conditional moments (GRACE) method to do portfolio selection based on thousands of stocks or more. The GRACE method first learns the conditional quantiles and mean of stock returns via a factor-augmented temporal graph convolutional network, which guides the learning procedure through a factor-hypergraph built by the set of stock-to-stock relations from the domain knowledge as well as the set of factor-to-stock relations from the asset pricing knowledge. Next, the GRACE method learns the conditional variance, skewness, and kurtosis of stock returns from the learned conditional quantiles by using the quantiled conditional moment (QCM) method. The QCM method is a supervised learning procedure to learn these conditional higher-order moments, so it largely overcomes the computational difficulty from the classical high-dimensional GARCH-type methods. Moreover, the QCM method allows the mis-specification in modeling conditional quantiles to some extent, due to its regression-based nature. Finally, the GRACE method uses the learned conditional mean, variance, skewness, and kurtosis to construct several performance measures, which are criteria to sort the stocks to proceed the portfolio selection in the well-known 10-decile framework. An application to NASDAQ and NYSE stock markets shows that the GRACE method performs much better than its competitors, particularly when the performance measures are comprised of conditional variance, skewness, and kurtosis.
Non-decreasing Quantile Function Network with Efficient Exploration for Distributional Reinforcement Learning
May 14, 2021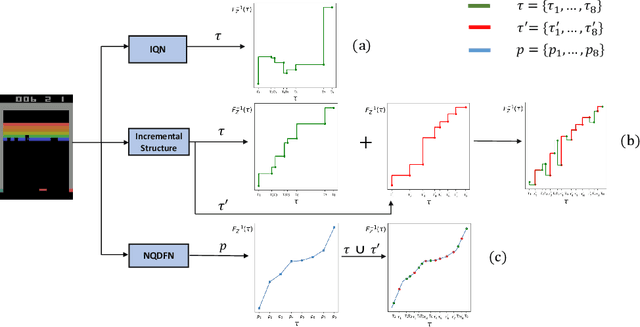
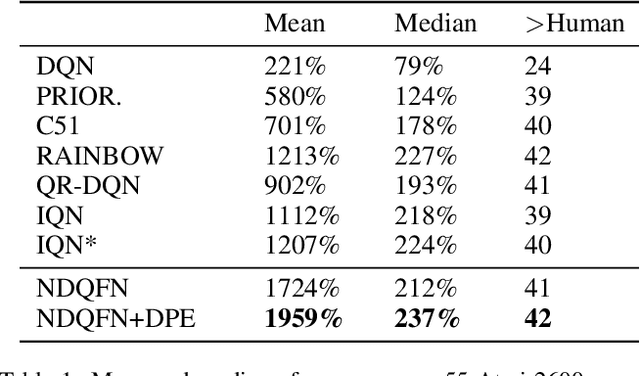
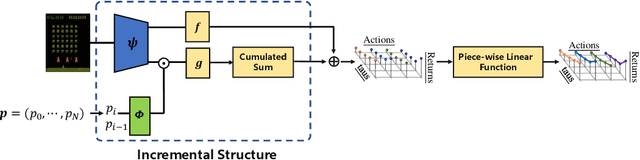
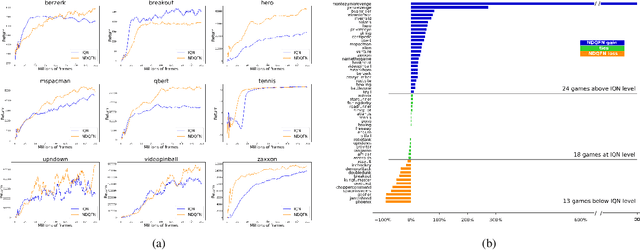
Although distributional reinforcement learning (DRL) has been widely examined in the past few years, there are two open questions people are still trying to address. One is how to ensure the validity of the learned quantile function, the other is how to efficiently utilize the distribution information. This paper attempts to provide some new perspectives to encourage the future in-depth studies in these two fields. We first propose a non-decreasing quantile function network (NDQFN) to guarantee the monotonicity of the obtained quantile estimates and then design a general exploration framework called distributional prediction error (DPE) for DRL which utilizes the entire distribution of the quantile function. In this paper, we not only discuss the theoretical necessity of our method but also show the performance gain it achieves in practice by comparing with some competitors on Atari 2600 Games especially in some hard-explored games.