 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving >97% on GSM8K: Deeply Understanding the Problems Makes LLMs Better Reasoners
Paper and Code
Apr 28, 2024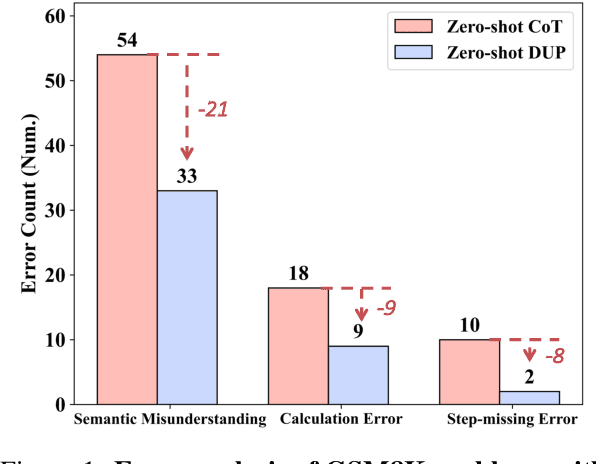
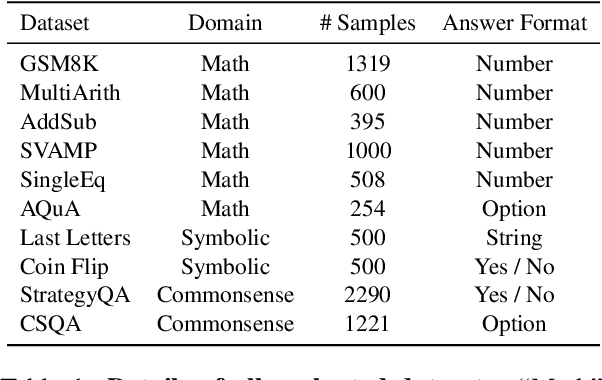

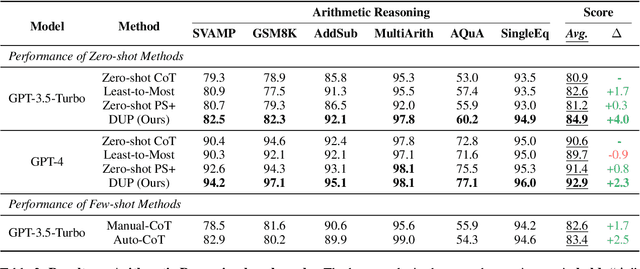
Chain of Thought prompting strategy has enhanced the performance of Large Language Models (LLMs) across various NLP tasks. However, it still has shortcomings when dealing with complex reasoning tasks, including understanding errors, calculation errors and process errors (e.g., missing-step and hallucinations). Subsequently, our in-depth analyses among various error types show that deeply understanding the whole problem is critical in addressing complicated reasoning tasks. Motivated by this, we propose a simple-yet-effective method, namely Deeply Understanding the Problems (DUP), to enhance the LLMs' reasoning abilities. The core of our method is to encourage the LLMs to deeply understand the problems and leverage the key problem-solving information for better reasoning. Extensive experiments on 10 diverse reasoning benchmarks show that our DUP method consistently outperforms the other counterparts by a large margin. More encouragingly, DUP achieves a new SOTA result on the GSM8K benchmark, with an accuracy of 97.1% in a zero-shot setting.