 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePML: Progressive Margin Loss for Long-tailed Age Classification
Mar 03, 2021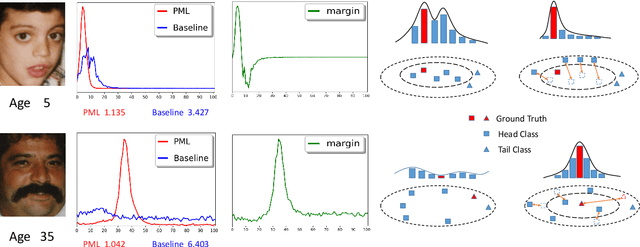
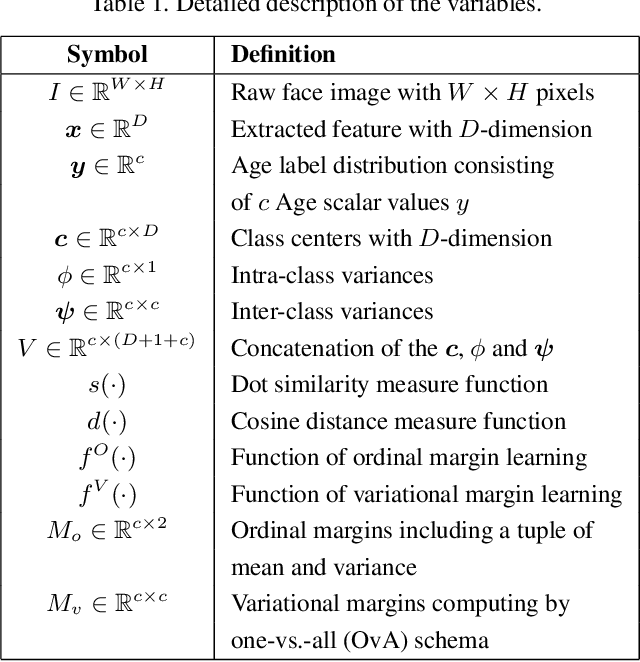

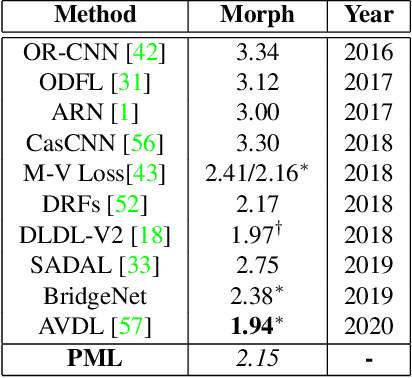
In this paper, we propose a progressive margin loss (PML) approach for unconstrained facial age classification. Conventional methods make strong assumption on that each class owns adequate instances to outline its data distribution, likely leading to bias prediction where the training samples are sparse across age classes. Instead, our PML aims to adaptively refine the age label pattern by enforcing a couple of margins, which fully takes in the in-between discrepancy of the intra-class variance, inter-class variance and class center. Our PML typically incorporates with the ordinal margin and the variational margin, simultaneously plugging in the globally-tuned deep neural network paradigm. More specifically, the ordinal margin learns to exploit the correlated relationship of the real-world age labels. Accordingly, the variational margin is leveraged to minimize the influence of head classes that misleads the prediction of tailed samples. Moreover, our optimization carefully seeks a series of indicator curricula to achieve robust and efficient model training. Extensive experimental results on three face aging datasets demonstrate that our PML achieves compelling performance compared to state of the arts. Code will be made publicly.
Towards Omni-Supervised Face Alignment for Large Scale Unlabeled Videos
Dec 16, 2019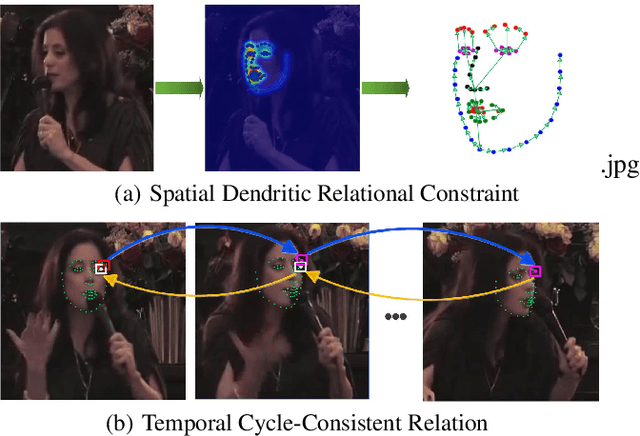
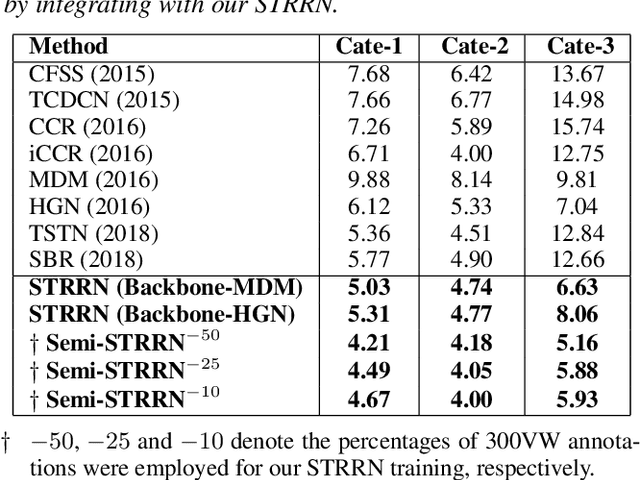
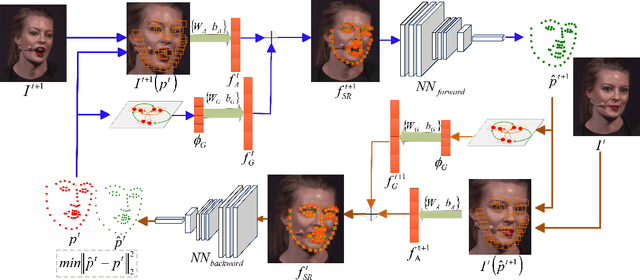
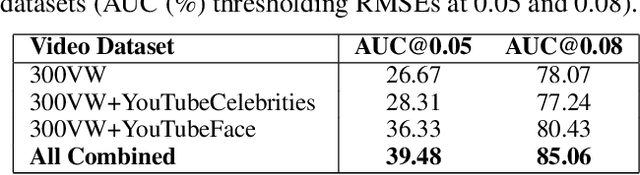
In this paper, we propose a spatial-temporal relational reasoning networks (STRRN) approach to investigate the problem of omni-supervised face alignment in videos. Unlike existing fully supervised methods which rely on numerous annotations by hand, our learner exploits large scale unlabeled videos plus available labeled data to generate auxiliary plausible training annotations. Motivated by the fact that neighbouring facial landmarks are usually correlated and coherent across consecutive frames, our approach automatically reasons about discriminative spatial-temporal relationships among landmarks for stable face tracking. Specifically, we carefully develop an interpretable and efficient network module, which disentangles facial geometry relationship for every static frame and simultaneously enforces the bi-directional cycle-consistency across adjacent frames, thus allowing the modeling of intrinsic spatial-temporal relations from raw face sequences. Extensive experimental results demonstrate that our approach surpasses the performance of most fully supervised state-of-the-arts.