 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Any-Quality Image Segmentation via Generative and Adaptive Latent Space Enhancement
Jan 05, 2026Segment Anything Models (SAMs), known for their exceptional zero-shot segmentation performance, have garnered significant attention in the research community. Nevertheless, their performance drops significantly on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM++, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Additionally, to improve compatibility between the pre-trained diffusion model and the segmentation framework, we introduce two techniques, i.e., Feature Distribution Alignment (FDA) and Channel Replication and Expansion (CRE). However, the above components lack explicit guidance regarding the degree of degradation. The model is forced to implicitly fit a complex noise distribution that spans conditions from mild noise to severe artifacts, which substantially increases the learning burden and leads to suboptimal reconstructions. To address this issue, we further introduce a Degradation-aware Adaptive Enhancement (DAE) mechanism. The key principle of DAE is to decouple the reconstruction process for arbitrary-quality features into two stages: degradation-level prediction and degradation-aware reconstruction. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. Extensive experiments demonstrate that GleSAM++ significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM++ also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
Segment Any-Quality Images with Generative Latent Space Enhancement
Mar 16, 2025



Despite their success, Segment Anything Models (SAMs) experience significant performance drops on severely degraded, low-quality images, limiting their effectiveness in real-world scenarios. To address this, we propose GleSAM, which utilizes Generative Latent space Enhancement to boost robustness on low-quality images, thus enabling generalization across various image qualities. Specifically, we adapt the concept of latent diffusion to SAM-based segmentation frameworks and perform the generative diffusion process in the latent space of SAM to reconstruct high-quality representation, thereby improving segmentation. Additionally, we introduce two techniques to improve compatibility between the pre-trained diffusion model and the segmentation framework. Our method can be applied to pre-trained SAM and SAM2 with only minimal additional learnable parameters, allowing for efficient optimization. We also construct the LQSeg dataset with a greater diversity of degradation types and levels for training and evaluating the model. Extensive experiments demonstrate that GleSAM significantly improves segmentation robustness on complex degradations while maintaining generalization to clear images. Furthermore, GleSAM also performs well on unseen degradations, underscoring the versatility of our approach and dataset.
Why mamba is effective? Exploit Linear Transformer-Mamba Network for Multi-Modality Image Fusion
Sep 05, 2024Multi-modality image fusion aims to integrate the merits of images from different sources and render high-quality fusion images. However, existing feature extraction and fusion methods are either constrained by inherent local reduction bias and static parameters during inference (CNN) or limited by quadratic computational complexity (Transformers), and cannot effectively extract and fuse features. To solve this problem, we propose a dual-branch image fusion network called Tmamba. It consists of linear Transformer and Mamba, which has global modeling capabilities while maintaining linear complexity. Due to the difference between the Transformer and Mamba structures, the features extracted by the two branches carry channel and position information respectively. T-M interaction structure is designed between the two branches, using global learnable parameters and convolutional layers to transfer position and channel information respectively. We further propose cross-modal interaction at the attention level to obtain cross-modal attention. Experiments show that our Tmamba achieves promising results in multiple fusion tasks, including infrared-visible image fusion and medical image fusion. Code with checkpoints will be available after the peer-review process.
Progressive Contrastive Learning with Multi-Prototype for Unsupervised Visible-Infrared Person Re-identification
Feb 29, 2024



Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match specified people in infrared images to visible images without annotation, and vice versa. USVI-ReID is a challenging yet under-explored task. Most existing methods address the USVI-ReID problem using cluster-based contrastive learning, which simply employs the cluster center as a representation of a person. However, the cluster center primarily focuses on shared information, overlooking disparity. To address the problem, we propose a Progressive Contrastive Learning with Multi-Prototype (PCLMP) method for USVI-ReID. In brief, we first generate the hard prototype by selecting the sample with the maximum distance from the cluster center. This hard prototype is used in the contrastive loss to emphasize disparity. Additionally, instead of rigidly aligning query images to a specific prototype, we generate the dynamic prototype by randomly picking samples within a cluster. This dynamic prototype is used to retain the natural variety of features while reducing instability in the simultaneous learning of both common and disparate information. Finally, we introduce a progressive learning strategy to gradually shift the model's attention towards hard samples, avoiding cluster deterioration. Extensive experiments conducted on the publicly available SYSU-MM01 and RegDB datasets validate the effectiveness of the proposed method. PCLMP outperforms the existing state-of-the-art method with an average mAP improvement of 3.9%. The source codes will be released.
PML: Progressive Margin Loss for Long-tailed Age Classification
Mar 03, 2021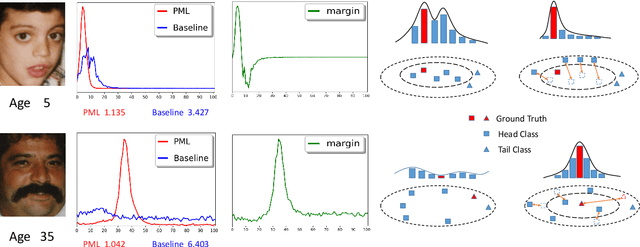
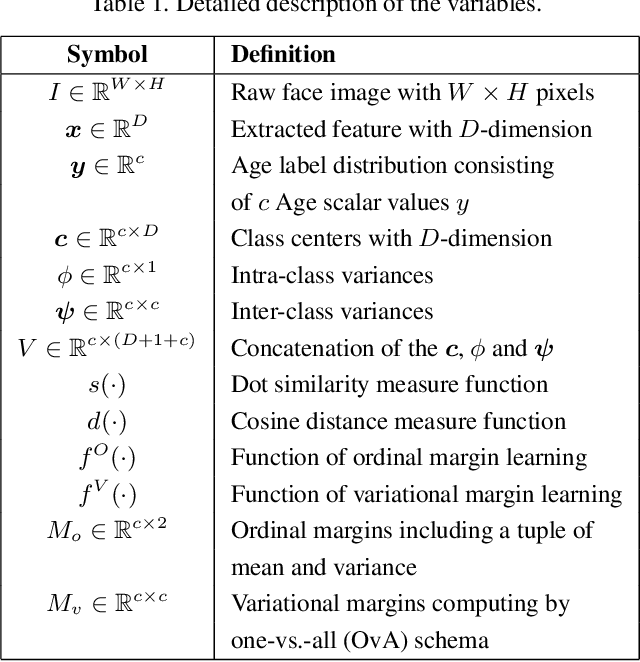

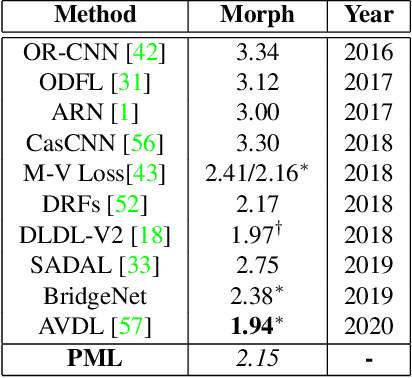
In this paper, we propose a progressive margin loss (PML) approach for unconstrained facial age classification. Conventional methods make strong assumption on that each class owns adequate instances to outline its data distribution, likely leading to bias prediction where the training samples are sparse across age classes. Instead, our PML aims to adaptively refine the age label pattern by enforcing a couple of margins, which fully takes in the in-between discrepancy of the intra-class variance, inter-class variance and class center. Our PML typically incorporates with the ordinal margin and the variational margin, simultaneously plugging in the globally-tuned deep neural network paradigm. More specifically, the ordinal margin learns to exploit the correlated relationship of the real-world age labels. Accordingly, the variational margin is leveraged to minimize the influence of head classes that misleads the prediction of tailed samples. Moreover, our optimization carefully seeks a series of indicator curricula to achieve robust and efficient model training. Extensive experimental results on three face aging datasets demonstrate that our PML achieves compelling performance compared to state of the arts. Code will be made publicly.