 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAM$^3$Safety: Towards Data Efficient Alignment of Multi-modal Multi-turn Safety for MLLMs
Jan 08, 2026Multi-modal Large Language Models (MLLMs) are increasingly deployed in interactive applications. However, their safety vulnerabilities become pronounced in multi-turn multi-modal scenarios, where harmful intent can be gradually reconstructed across turns, and security protocols fade into oblivion as the conversation progresses. Existing Reinforcement Learning from Human Feedback (RLHF) alignment methods are largely developed for single-turn visual question-answer (VQA) task and often require costly manual preference annotations, limiting their effectiveness and scalability in dialogues. To address this challenge, we present InterSafe-V, an open-source multi-modal dialogue dataset containing 11,270 dialogues and 500 specially designed refusal VQA samples. This dataset, constructed through interaction between several models, is designed to more accurately reflect real-world scenarios and includes specialized VQA pairs tailored for specific domains. Building on this dataset, we propose AM$^3$Safety, a framework that combines a cold-start refusal phase with Group Relative Policy Optimization (GRPO) fine-tuning using turn-aware dual-objective rewards across entire dialogues. Experiments on Qwen2.5-VL-7B-Instruct and LLaVA-NeXT-7B show more than 10\% decrease in Attack Success Rate (ASR) together with an increment of at least 8\% in harmless dimension and over 13\% in helpful dimension of MLLMs on multi-modal multi-turn safety benchmarks, while preserving their general abilities.
HSKBenchmark: Modeling and Benchmarking Chinese Second Language Acquisition in Large Language Models through Curriculum Tuning
Nov 19, 2025



Language acquisition is vital to revealing the nature of human language intelligence and has recently emerged as a promising perspective for improving the interpretability of large language models (LLMs). However, it is ethically and practically infeasible to conduct experiments that require controlling human learners' language inputs. This poses challenges for the verifiability and scalability of language acquisition modeling, particularly in Chinese second language acquisition (SLA). While LLMs provide a controllable and reproducible alternative, a systematic benchmark to support phase-wise modeling and assessment is still lacking. In this paper, we present HSKBenchmark, the first benchmark for staged modeling and writing assessment of LLMs in Chinese SLA. It covers HSK levels 3 to 6 and includes authentic textbooks with 6.76 million tokens, 16K synthetic instruction samples, 30 test topics, and a linguistically grounded evaluation system. To simulate human learning trajectories, we introduce a curriculum-tuning framework that trains models from beginner to advanced levels. An evaluation system is created to examine level-based grammar coverage, writing errors, lexical and syntactic complexity, and holistic scoring. We also build HSKAgent, fine-tuned on 10K learner compositions. Extensive experimental results demonstrate that HSKBenchmark not only models Chinese SLA effectively, but also serves as a reliable benchmark for dynamic writing assessment in LLMs. Our fine-tuned LLMs have writing performance on par with advanced human learners and exhibit human-like acquisition characteristics. The HSKBenchmark, HSKAgent, and checkpoints serve as foundational tools and resources, with the potential to pave the way for future research on language acquisition modeling and LLMs interpretability. Code and data are publicly available at: https://github.com/CharlesYang030/HSKB.
Emotion Omni: Enabling Empathetic Speech Response Generation through Large Language Models
Aug 26, 2025With the development of speech large language models (speech LLMs), users can now interact directly with assistants via speech. However, most existing models simply convert the response content into speech without fully understanding the rich emotional and paralinguistic cues embedded in the user's query. In many cases, the same sentence can have different meanings depending on the emotional expression. Furthermore, emotional understanding is essential for improving user experience in human-machine interaction. Currently, most speech LLMs with empathetic capabilities are trained on massive datasets. This approach requires vast amounts of data and significant computational resources. Therefore, a key challenge lies in how to develop a speech LLM capable of generating empathetic responses with limited data and without the need for large-scale training. To address this challenge, we propose Emotion Omni, a novel model architecture designed to understand the emotional content of user speech input and generate empathetic speech responses. Additionally, we developed a data generation pipeline based on an open-source TTS framework to construct a 200k emotional dialogue dataset, which supports the construction of an empathetic speech assistant. The demos are available at https://w311411.github.io/omni_demo/
CTR-Driven Ad Text Generation via Online Feedback Preference Optimization
Jul 27, 2025Advertising text plays a critical role in determining click-through rates (CTR) in online advertising. Large Language Models (LLMs) offer significant efficiency advantages over manual ad text creation. However, LLM-generated ad texts do not guarantee higher CTR performance compared to human-crafted texts, revealing a gap between generation quality and online performance of ad texts. In this work, we propose a novel ad text generation method which optimizes for CTR through preference optimization from online feedback. Our approach adopts an innovative two-stage framework: (1) diverse ad text sampling via one-shot in-context learning, using retrieval-augmented generation (RAG) to provide exemplars with chain-of-thought (CoT) reasoning; (2) CTR-driven preference optimization from online feedback, which weighs preference pairs according to their CTR gains and confidence levels. Through our method, the resulting model enables end-to-end generation of high-CTR ad texts. Extensive experiments have demonstrated the effectiveness of our method in both offline and online metrics. Notably, we have applied our method on a large-scale online shopping platform and achieved significant CTR improvements, showcasing its strong applicability and effectiveness in advertising systems.
Quartet: Native FP4 Training Can Be Optimal for Large Language Models
May 20, 2025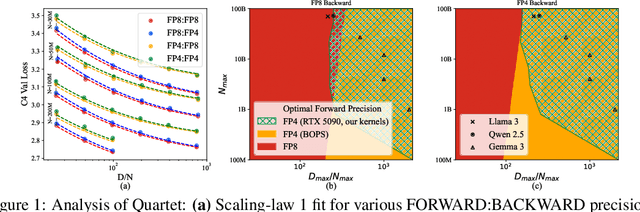


The rapid advancement of large language models (LLMs) has been paralleled by unprecedented increases in computational demands, with training costs for state-of-the-art models doubling every few months. Training models directly in low-precision arithmetic offers a solution, by improving both computational throughput and energy efficiency. Specifically, NVIDIA's recent Blackwell architecture facilitates extremely low-precision operations, specifically FP4 variants, promising substantial efficiency gains. Yet, current algorithms for training LLMs in FP4 precision face significant accuracy degradation and often rely on mixed-precision fallbacks. In this paper, we systematically investigate hardware-supported FP4 training and introduce Quartet, a new approach enabling accurate, end-to-end FP4 training with all the major computations (in e.g. linear layers) being performed in low precision. Through extensive evaluations on Llama-type models, we reveal a new low-precision scaling law that quantifies performance trade-offs across varying bit-widths and allows us to identify a "near-optimal" low-precision training technique in terms of accuracy-vs-computation, called Quartet. We implement Quartet using optimized CUDA kernels tailored for NVIDIA Blackwell GPUs, and show that it can achieve state-of-the-art accuracy for FP4 precision, successfully training billion-scale models. Our method demonstrates that fully FP4-based training is a competitive alternative to standard-precision and FP8 training. Our code is available at https://github.com/IST-DASLab/Quartet.
UniDiffGrasp: A Unified Framework Integrating VLM Reasoning and VLM-Guided Part Diffusion for Open-Vocabulary Constrained Grasping with Dual Arms
May 11, 2025Open-vocabulary, task-oriented grasping of specific functional parts, particularly with dual arms, remains a key challenge, as current Vision-Language Models (VLMs), while enhancing task understanding, often struggle with precise grasp generation within defined constraints and effective dual-arm coordination. We innovatively propose UniDiffGrasp, a unified framework integrating VLM reasoning with guided part diffusion to address these limitations. UniDiffGrasp leverages a VLM to interpret user input and identify semantic targets (object, part(s), mode), which are then grounded via open-vocabulary segmentation. Critically, the identified parts directly provide geometric constraints for a Constrained Grasp Diffusion Field (CGDF) using its Part-Guided Diffusion, enabling efficient, high-quality 6-DoF grasps without retraining. For dual-arm tasks, UniDiffGrasp defines distinct target regions, applies part-guided diffusion per arm, and selects stable cooperative grasps. Through extensive real-world deployment, UniDiffGrasp achieves grasp success rates of 0.876 in single-arm and 0.767 in dual-arm scenarios, significantly surpassing existing state-of-the-art methods, demonstrating its capability to enable precise and coordinated open-vocabulary grasping in complex real-world scenarios.
Towards Robust Multi-UAV Collaboration: MARL with Noise-Resilient Communication and Attention Mechanisms
Mar 04, 2025Efficient path planning for unmanned aerial vehicles (UAVs) is crucial in remote sensing and information collection. As task scales expand, the cooperative deployment of multiple UAVs significantly improves information collection efficiency. However, collaborative communication and decision-making for multiple UAVs remain major challenges in path planning, especially in noisy environments. To efficiently accomplish complex information collection tasks in 3D space and address robust communication issues, we propose a multi-agent reinforcement learning (MARL) framework for UAV path planning based on the Counterfactual Multi-Agent Policy Gradients (COMA) algorithm. The framework incorporates attention mechanism-based UAV communication protocol and training-deployment system, significantly improving communication robustness and individual decision-making capabilities in noisy conditions. Experiments conducted on both synthetic and real-world datasets demonstrate that our method outperforms existing algorithms in terms of path planning efficiency and robustness, especially in noisy environments, achieving a 78\% improvement in entropy reduction.
Deep Robust Reversible Watermarking
Mar 04, 2025



Robust Reversible Watermarking (RRW) enables perfect recovery of cover images and watermarks in lossless channels while ensuring robust watermark extraction in lossy channels. Existing RRW methods, mostly non-deep learning-based, face complex designs, high computational costs, and poor robustness, limiting their practical use. This paper proposes Deep Robust Reversible Watermarking (DRRW), a deep learning-based RRW scheme. DRRW uses an Integer Invertible Watermark Network (iIWN) to map integer data distributions invertibly, addressing conventional RRW limitations. Unlike traditional RRW, which needs distortion-specific designs, DRRW employs an encoder-noise layer-decoder framework for adaptive robustness via end-to-end training. In inference, cover image and watermark map to an overflowed stego image and latent variables, compressed by arithmetic coding into a bitstream embedded via reversible data hiding for lossless recovery. We introduce an overflow penalty loss to reduce pixel overflow, shortening the auxiliary bitstream while enhancing robustness and stego image quality. An adaptive weight adjustment strategy avoids manual watermark loss weighting, improving training stability and performance. Experiments show DRRW outperforms state-of-the-art RRW methods, boosting robustness and cutting embedding, extraction, and recovery complexities by 55.14\(\times\), 5.95\(\times\), and 3.57\(\times\), respectively. The auxiliary bitstream shrinks by 43.86\(\times\), with reversible embedding succeeding on 16,762 PASCAL VOC 2012 images, advancing practical RRW. DRRW exceeds irreversible robust watermarking in robustness and quality while maintaining reversibility.
QuEST: Stable Training of LLMs with 1-Bit Weights and Activations
Feb 07, 2025



One approach to reducing the massive costs of large language models (LLMs) is the use of quantized or sparse representations for training or deployment. While post-training compression methods are very popular, the question of obtaining even more accurate compressed models by directly training over such representations, i.e., Quantization-Aware Training (QAT), is still open: for example, a recent study (arXiv:2411.04330v2) put the "optimal" bit-width at which models can be trained using QAT, while staying accuracy-competitive with standard FP16/BF16 precision, at 8-bits weights and activations. We advance this state-of-the-art via a new method called QuEST, which is Pareto-competitive with FP16, i.e., it provides better accuracy at lower model size, while training models with weights and activations in 4-bits or less. Moreover, QuEST allows stable training with 1-bit weights and activations. QuEST achieves this by improving two key aspects of QAT methods: (1) accurate and fast quantization of the (continuous) distributions of weights and activations via Hadamard normalization and MSE-optimal fitting; (2) a new trust gradient estimator based on the idea of explicitly minimizing the error between the noisy gradient computed over quantized states and the "true" (but unknown) full-precision gradient. Experiments on Llama-type architectures show that QuEST induces stable scaling laws across the entire range of hardware-supported precisions, and can be extended to sparse representations. We provide GPU kernel support showing that models produced by QuEST can be executed efficiently. Our code is available at https://github.com/IST-DASLab/QuEST.
PAID: A Framework of Product-Centric Advertising Image Design
Jan 24, 2025In E-commerce platforms, a full advertising image is composed of a background image and marketing taglines. Automatic ad image design reduces human costs and plays a crucial role. For the convenience of users, a novel automatic framework named Product-Centric Advertising Image Design (PAID) is proposed in this work. PAID takes the product foreground image, required taglines, and target size as input and creates an ad image automatically. PAID consists of four sequential stages: prompt generation, layout generation, background image generation, and graphics rendering. Different expert models are trained to conduct these sub-tasks. A visual language model (VLM) based prompt generation model is leveraged to produce a product-matching background prompt. The layout generation model jointly predicts text and image layout according to the background prompt, product, and taglines to achieve the best harmony. An SDXL-based layout-controlled inpainting model is trained to generate an aesthetic background image. Previous ad image design methods take a background image as input and then predict the layout of taglines, which limits the spatial layout due to fixed image content. Innovatively, our PAID adjusts the stages to produce an unrestricted layout. To complete the PAID framework, we created two high-quality datasets, PITA and PIL. Extensive experimental results show that PAID creates more visually pleasing advertising images than previous methods.