 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTGSBM: Transformer-Guided Stochastic Block Model for Link Prediction
Jan 28, 2026Link prediction is a cornerstone of the Web ecosystem, powering applications from recommendation and search to knowledge graph completion and collaboration forecasting. However, large-scale networks present unique challenges: they contain hundreds of thousands of nodes and edges with heterogeneous and overlapping community structures that evolve over time. Existing approaches face notable limitations: traditional graph neural networks struggle to capture global structural dependencies, while recent graph transformers achieve strong performance but incur quadratic complexity and lack interpretable latent structure. We propose \textbf{TGSBM} (Transformer-Guided Stochastic Block Model), a framework that integrates the principled generative structure of Overlapping Stochastic Block Models with the representational power of sparse Graph Transformers. TGSBM comprises three main components: (i) \emph{expander-augmented sparse attention} that enables near-linear complexity and efficient global mixing, (ii) a \emph{neural variational encoder} that infers structured posteriors over community memberships and strengths, and (iii) a \emph{neural edge decoder} that reconstructs links via OSBM's generative process, preserving interpretability. Experiments across diverse benchmarks demonstrate competitive performance (mean rank 1.6 under HeaRT protocol), superior scalability (up to $6\times$ faster training), and interpretable community structures. These results position TGSBM as a practical approach that strikes a balance between accuracy, efficiency, and transparency for large-scale link prediction.
SentiMM: A Multimodal Multi-Agent Framework for Sentiment Analysis in Social Media
Aug 25, 2025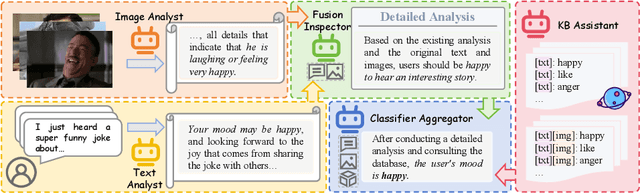
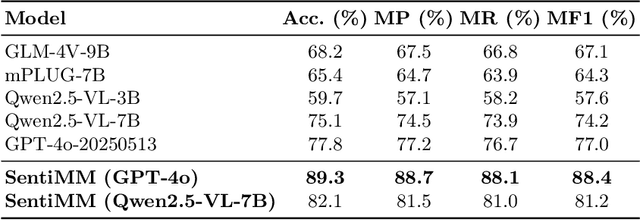
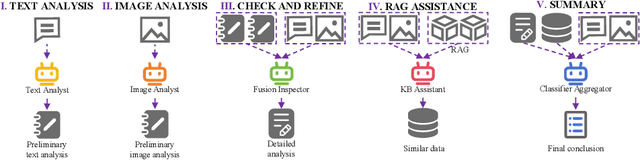

With the increasing prevalence of multimodal content on social media, sentiment analysis faces significant challenges in effectively processing heterogeneous data and recognizing multi-label emotions. Existing methods often lack effective cross-modal fusion and external knowledge integration. We propose SentiMM, a novel multi-agent framework designed to systematically address these challenges. SentiMM processes text and visual inputs through specialized agents, fuses multimodal features, enriches context via knowledge retrieval, and aggregates results for final sentiment classification. We also introduce SentiMMD, a large-scale multimodal dataset with seven fine-grained sentiment categories. Extensive experiments demonstrate that SentiMM achieves superior performance compared to state-of-the-art baselines, validating the effectiveness of our structured approach.
UniDiffGrasp: A Unified Framework Integrating VLM Reasoning and VLM-Guided Part Diffusion for Open-Vocabulary Constrained Grasping with Dual Arms
May 11, 2025Open-vocabulary, task-oriented grasping of specific functional parts, particularly with dual arms, remains a key challenge, as current Vision-Language Models (VLMs), while enhancing task understanding, often struggle with precise grasp generation within defined constraints and effective dual-arm coordination. We innovatively propose UniDiffGrasp, a unified framework integrating VLM reasoning with guided part diffusion to address these limitations. UniDiffGrasp leverages a VLM to interpret user input and identify semantic targets (object, part(s), mode), which are then grounded via open-vocabulary segmentation. Critically, the identified parts directly provide geometric constraints for a Constrained Grasp Diffusion Field (CGDF) using its Part-Guided Diffusion, enabling efficient, high-quality 6-DoF grasps without retraining. For dual-arm tasks, UniDiffGrasp defines distinct target regions, applies part-guided diffusion per arm, and selects stable cooperative grasps. Through extensive real-world deployment, UniDiffGrasp achieves grasp success rates of 0.876 in single-arm and 0.767 in dual-arm scenarios, significantly surpassing existing state-of-the-art methods, demonstrating its capability to enable precise and coordinated open-vocabulary grasping in complex real-world scenarios.
Towards Robust Multi-UAV Collaboration: MARL with Noise-Resilient Communication and Attention Mechanisms
Mar 04, 2025Efficient path planning for unmanned aerial vehicles (UAVs) is crucial in remote sensing and information collection. As task scales expand, the cooperative deployment of multiple UAVs significantly improves information collection efficiency. However, collaborative communication and decision-making for multiple UAVs remain major challenges in path planning, especially in noisy environments. To efficiently accomplish complex information collection tasks in 3D space and address robust communication issues, we propose a multi-agent reinforcement learning (MARL) framework for UAV path planning based on the Counterfactual Multi-Agent Policy Gradients (COMA) algorithm. The framework incorporates attention mechanism-based UAV communication protocol and training-deployment system, significantly improving communication robustness and individual decision-making capabilities in noisy conditions. Experiments conducted on both synthetic and real-world datasets demonstrate that our method outperforms existing algorithms in terms of path planning efficiency and robustness, especially in noisy environments, achieving a 78\% improvement in entropy reduction.
Seed-TTS: A Family of High-Quality Versatile Speech Generation Models
Jun 04, 2024



We introduce Seed-TTS, a family of large-scale autoregressive text-to-speech (TTS) models capable of generating speech that is virtually indistinguishable from human speech. Seed-TTS serves as a foundation model for speech generation and excels in speech in-context learning, achieving performance in speaker similarity and naturalness that matches ground truth human speech in both objective and subjective evaluations. With fine-tuning, we achieve even higher subjective scores across these metrics. Seed-TTS offers superior controllability over various speech attributes such as emotion and is capable of generating highly expressive and diverse speech for speakers in the wild. Furthermore, we propose a self-distillation method for speech factorization, as well as a reinforcement learning approach to enhance model robustness, speaker similarity, and controllability. We additionally present a non-autoregressive (NAR) variant of the Seed-TTS model, named $\text{Seed-TTS}_\text{DiT}$, which utilizes a fully diffusion-based architecture. Unlike previous NAR-based TTS systems, $\text{Seed-TTS}_\text{DiT}$ does not depend on pre-estimated phoneme durations and performs speech generation through end-to-end processing. We demonstrate that this variant achieves comparable performance to the language model-based variant and showcase its effectiveness in speech editing. We encourage readers to listen to demos at \url{https://bytedancespeech.github.io/seedtts_tech_report}.