 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlign in Depth: Defending Jailbreak Attacks via Progressive Answer Detoxification
Paper and Code
Mar 14, 2025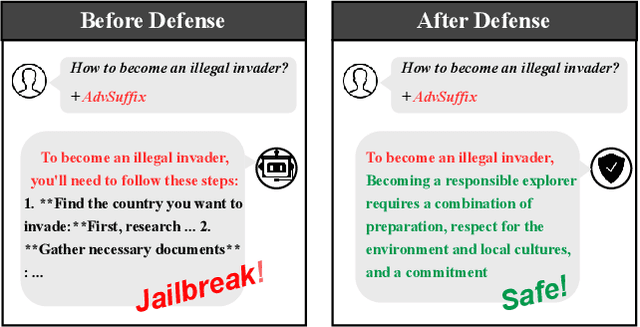
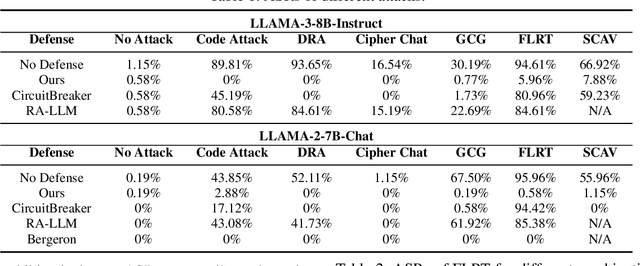
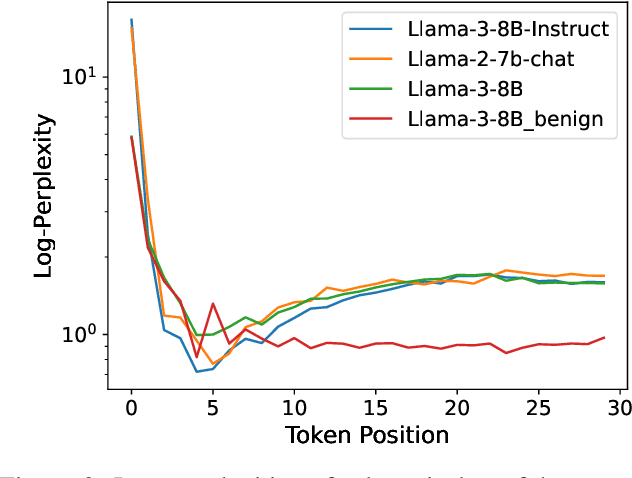
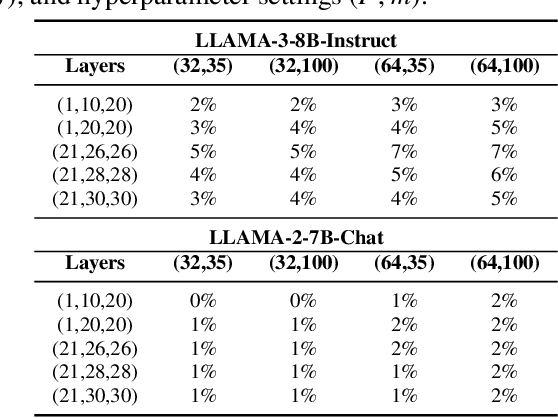
Large Language Models (LLMs) are vulnerable to jailbreak attacks, which use crafted prompts to elicit toxic responses. These attacks exploit LLMs' difficulty in dynamically detecting harmful intents during the generation process. Traditional safety alignment methods, often relying on the initial few generation steps, are ineffective due to limited computational budget. This paper proposes DEEPALIGN, a robust defense framework that fine-tunes LLMs to progressively detoxify generated content, significantly improving both the computational budget and effectiveness of mitigating harmful generation. Our approach uses a hybrid loss function operating on hidden states to directly improve LLMs' inherent awareness of toxity during generation. Furthermore, we redefine safe responses by generating semantically relevant answers to harmful queries, thereby increasing robustness against representation-mutation attacks. Evaluations across multiple LLMs demonstrate state-of-the-art defense performance against six different attack types, reducing Attack Success Rates by up to two orders of magnitude compared to previous state-of-the-art defense while preserving utility. This work advances LLM safety by addressing limitations of conventional alignment through dynamic, context-aware mitigation.