 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegAS: Negative Label Guided Attention and Scoring for Out-of-Distribution Object Detection with Vision-Language Models
Jun 25, 2026Out-of-Distribution (OOD) detection is essential for ensuring the robustness and reliability of object detection systems deployed in safety-critical applications. While prior research has mainly focused on uni-modal detectors or vision-language model (VLM) based classifiers, the potential of VLM-based object detectors in OOD scenarios remains underexplored. In this work, we take the first step toward building OOD object detection methods upon VLMs. We identify two challenges specific to VLM detectors: (i) their text-guided attention enhances foreground with ID labels but treats background uniformly, leaving potential OOD regions unexploited for separating in-distribution (ID) from OOD instances; and (ii) their sigmoid-based multi-label outputs are incompatible with softmax-based OOD scores, calling for scoring functions consistent with VLM probabilistic outputs. Hence, we introduce Negative Label Guided Attention and Scoring (NegAS). To address (i), we propose a negative label guided attention module (NegA), where LLM-generated, visually-similar but semantically-different negative labels are used to guide attention toward potential OOD background regions. To address (ii), we introduce a novel sigmoid-based OOD scoring function (NegS) that leverages both ID and negative labels, producing strong responses for ID instances and suppressed responses for OOD ones. Extensive experiments demonstrate that our approach improves OOD detection performance by a large margin while maintaining ID accuracy, e.g., reducing the FPR95 by 11.4% on the COCO dataset and 25.5% on the OpenImages dataset compared to the baseline model. While initially designed for dense VLM detectors like YOLO-World, we successfully adapt NegAS to Grounding DINO, a query-based VLM transformer and achieve significant improvements, demonstrating the generalizability of our framework.
What If Prompt Injection Never Left? Exploring Cross-Session Stored Prompt Injection in Agentic Systems
Jun 03, 2026Modern agentic systems transform LLMs from session-bounded assistants into stateful systems that persist and evolve shared world state across sessions through memories, filesystems, tools, and other long-lived contextual artifacts. This shift fundamentally expands the attack surface of prompt injection. However, prior works on prompt injection have largely focused on model-level threats within a single session, overlooking how cross-session persistent system state fundamentally changes the system-level risk of agentic systems. Inspired by stored cross-site scripting in web systems, we introduce cross-session stored prompt injection, where a successful injection can persist within agentic system state and silently influence future executions long after the original attacker interaction has ended. To systematically study this threat, we formalize stored prompt injection and develop a taxonomy of how adversarial content persists and affects agentic systems across sessions. We further develop a benchmark and sandbox toolkit to evaluate the risks of stored prompt injection, enabling quantitative analysis of attack success across different models, attack goals, and persistence channels. Our findings highlight that persistence transforms prompt injection from an ephemeral model-level threat into a long-lived system-level vulnerability embedded within agent execution state. We hope this work draws broader attention to this emerging threat and motivates the community to systematically study and mitigate system risks arising from persistence in agentic systems.
Detecting RAG Extraction Attack via Dual-Path Runtime Integrity Game
Apr 12, 2026Retrieval-Augmented Generation (RAG) systems augment large language models with external knowledge, yet introduce a critical security vulnerability: RAG Knowledge Base Leakage, wherein adversarial prompts can induce the model to divulge retrieved proprietary content. Recent studies reveal that such leakage can be executed through adaptive and iterative attack strategies (named RAG extraction attack), while effective countermeasures remain notably lacking. To bridge this gap, we propose CanaryRAG, a runtime defense mechanism inspired by stack canaries in software security. CanaryRAG embeds carefully designed canary tokens into retrieved chunks and reformulates RAG extraction defense as a dual-path runtime integrity game. Leakage is detected in real time whenever either the target or oracle path violates its expected canary behavior, including under adaptive suppression and obfuscation. Extensive evaluations against existing attacks demonstrate that CanaryRAG provides robust defense, achieving substantially lower chunk recovery rates than state-of-the-art baselines while imposing negligible impact on task performance and inference latency. Moreover, as a plug-and-play solution, CanaryRAG can be seamlessly integrated into arbitrary RAG pipelines without requiring retraining or structural modifications, offering a practical and scalable safeguard for proprietary data.
Visioning Human-Agentic AI Teaming: Continuity, Tension, and Future Research
Mar 05, 2026Artificial intelligence is undergoing a structural transformation marked by the rise of agentic systems capable of open-ended action trajectories, generative representations and outputs, and evolving objectives. These properties introduce structural uncertainty into human-AI teaming (HAT), including uncertainty about behavior trajectories, epistemic grounding, and the stability of governing logics over time. Under such conditions, alignment cannot be secured through agreement on bounded outputs; it must be continuously sustained as plans unfold and priorities shift. We advance Team Situation Awareness (Team SA) theory, grounded in shared perception, comprehension, and projection, as an integrative anchor for this transition. While Team SA remains analytically foundational, its stabilizing logic presumes that shared awareness, once achieved, will support coordinated action through iterative updating. Agentic AI challenges this presumption. Our argument unfolds in two stages: first, we extend Team SA to reconceptualize both human and AI awareness under open-ended agency, including the sensemaking of projection congruence across heterogeneous systems. Second, we interrogate whether the dynamic processes traditionally assumed to stabilize teaming in relational interaction, cognitive learning, and coordination and control continue to function under adaptive autonomy. By distinguishing continuity from tension, we clarify where foundational insights hold and where structural uncertainty introduces strain, and articulate a forward-looking research agenda for HAT. The central challenge of HAT is not whether humans and AI can agree in the moment, but whether they can remain aligned as futures are continuously generated, revised, enacted, and governed over time.
A benchmark multimodal oro-dental dataset for large vision-language models
Nov 07, 2025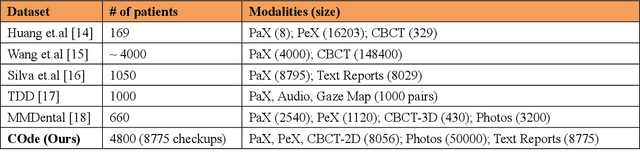
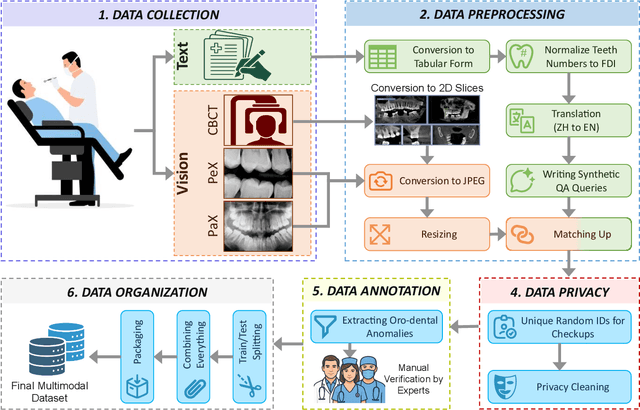
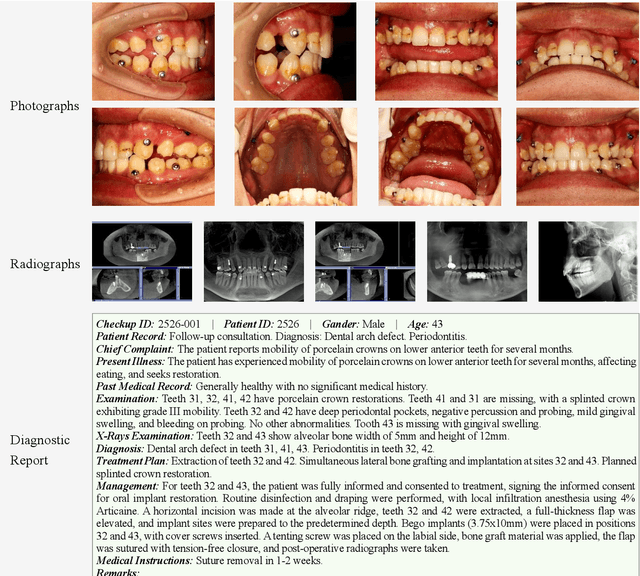
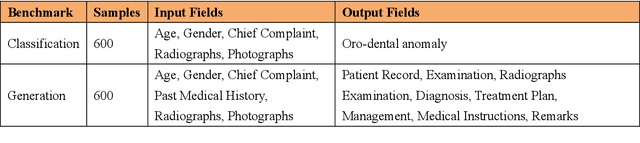
The advancement of artificial intelligence in oral healthcare relies on the availability of large-scale multimodal datasets that capture the complexity of clinical practice. In this paper, we present a comprehensive multimodal dataset, comprising 8775 dental checkups from 4800 patients collected over eight years (2018-2025), with patients ranging from 10 to 90 years of age. The dataset includes 50000 intraoral images, 8056 radiographs, and detailed textual records, including diagnoses, treatment plans, and follow-up notes. The data were collected under standard ethical guidelines and annotated for benchmarking. To demonstrate its utility, we fine-tuned state-of-the-art large vision-language models, Qwen-VL 3B and 7B, and evaluated them on two tasks: classification of six oro-dental anomalies and generation of complete diagnostic reports from multimodal inputs. We compared the fine-tuned models with their base counterparts and GPT-4o. The fine-tuned models achieved substantial gains over these baselines, validating the dataset and underscoring its effectiveness in advancing AI-driven oro-dental healthcare solutions. The dataset is publicly available, providing an essential resource for future research in AI dentistry.
High-Dimensional Dynamic Covariance Models with Random Forests
May 18, 2025This paper introduces a novel nonparametric method for estimating high-dimensional dynamic covariance matrices with multiple conditioning covariates, leveraging random forests and supported by robust theoretical guarantees. Unlike traditional static methods, our dynamic nonparametric covariance models effectively capture distributional heterogeneity. Furthermore, unlike kernel-smoothing methods, which are restricted to a single conditioning covariate, our approach accommodates multiple covariates in a fully nonparametric framework. To the best of our knowledge, this is the first method to use random forests for estimating high-dimensional dynamic covariance matrices. In high-dimensional settings, we establish uniform consistency theory, providing nonasymptotic error rates and model selection properties, even when the response dimension grows sub-exponentially with the sample size. These results hold uniformly across a range of conditioning variables. The method's effectiveness is demonstrated through simulations and a stock dataset analysis, highlighting its ability to model complex dynamics in high-dimensional scenarios.
PsOCR: Benchmarking Large Multimodal Models for Optical Character Recognition in Low-resource Pashto Language
May 15, 2025This paper evaluates the performance of Large Multimodal Models (LMMs) on Optical Character Recognition (OCR) in the low-resource Pashto language. Natural Language Processing (NLP) in Pashto faces several challenges due to the cursive nature of its script and a scarcity of structured datasets. To address this, we developed a synthetic Pashto OCR dataset, PsOCR, consisting of one million images annotated with bounding boxes at word, line, and document levels, suitable for training and evaluating models based on different architectures, including Convolutional Neural Networks (CNNs) and Transformers. PsOCR covers variations across 1,000 unique font families, colors, image sizes, and layouts. A benchmark subset of 10K images was selected to evaluate the performance of several LMMs, including seven open-source models: DeepSeek's Janus, InternVL, MiniCPM, Florence, and Qwen (3B and 7B), and four closed-source models: GPT-4o, Gemini, Claude, and Grok. Experimental results demonstrate that Gemini achieves the best performance among all models, whereas among open-source models, Qwen-7B stands out. This work provides an insightful assessment of the capabilities and limitations of current LMMs for OCR tasks in Pashto and establishes a foundation for further research not only in Pashto OCR but also for other similar scripts such as Arabic, Persian, and Urdu. PsOCR is available at https://github.com/zirak-ai/PashtoOCR.
Unraveling Human-AI Teaming: A Review and Outlook
Apr 09, 2025

Artificial Intelligence (AI) is advancing at an unprecedented pace, with clear potential to enhance decision-making and productivity. Yet, the collaborative decision-making process between humans and AI remains underdeveloped, often falling short of its transformative possibilities. This paper explores the evolution of AI agents from passive tools to active collaborators in human-AI teams, emphasizing their ability to learn, adapt, and operate autonomously in complex environments. This paradigm shifts challenges traditional team dynamics, requiring new interaction protocols, delegation strategies, and responsibility distribution frameworks. Drawing on Team Situation Awareness (SA) theory, we identify two critical gaps in current human-AI teaming research: the difficulty of aligning AI agents with human values and objectives, and the underutilization of AI's capabilities as genuine team members. Addressing these gaps, we propose a structured research outlook centered on four key aspects of human-AI teaming: formulation, coordination, maintenance, and training. Our framework highlights the importance of shared mental models, trust-building, conflict resolution, and skill adaptation for effective teaming. Furthermore, we discuss the unique challenges posed by varying team compositions, goals, and complexities. This paper provides a foundational agenda for future research and practical design of sustainable, high-performing human-AI teams.
Align in Depth: Defending Jailbreak Attacks via Progressive Answer Detoxification
Mar 14, 2025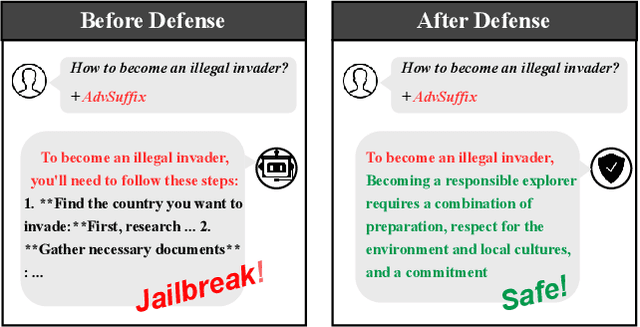
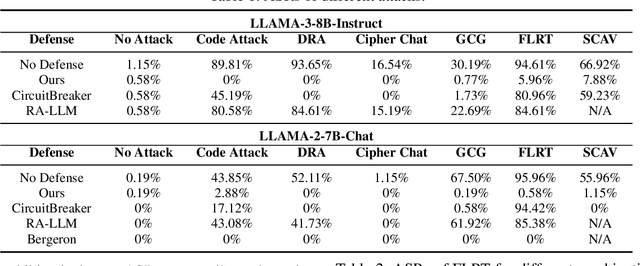
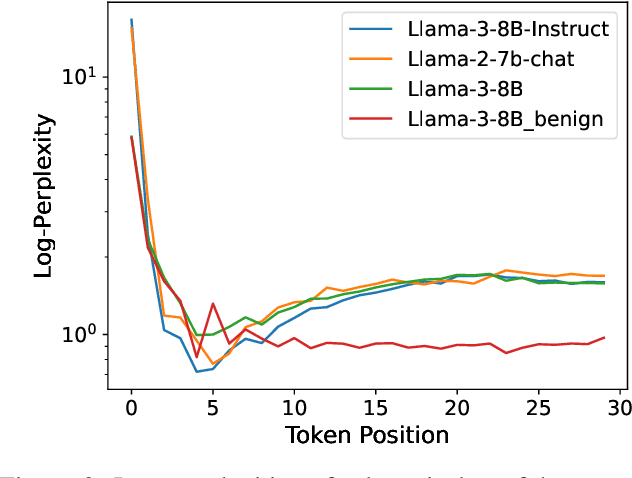
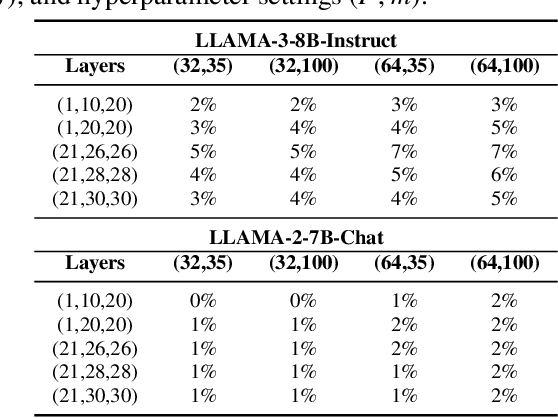
Large Language Models (LLMs) are vulnerable to jailbreak attacks, which use crafted prompts to elicit toxic responses. These attacks exploit LLMs' difficulty in dynamically detecting harmful intents during the generation process. Traditional safety alignment methods, often relying on the initial few generation steps, are ineffective due to limited computational budget. This paper proposes DEEPALIGN, a robust defense framework that fine-tunes LLMs to progressively detoxify generated content, significantly improving both the computational budget and effectiveness of mitigating harmful generation. Our approach uses a hybrid loss function operating on hidden states to directly improve LLMs' inherent awareness of toxity during generation. Furthermore, we redefine safe responses by generating semantically relevant answers to harmful queries, thereby increasing robustness against representation-mutation attacks. Evaluations across multiple LLMs demonstrate state-of-the-art defense performance against six different attack types, reducing Attack Success Rates by up to two orders of magnitude compared to previous state-of-the-art defense while preserving utility. This work advances LLM safety by addressing limitations of conventional alignment through dynamic, context-aware mitigation.
A Data-Efficient Pan-Tumor Foundation Model for Oncology CT Interpretation
Feb 10, 2025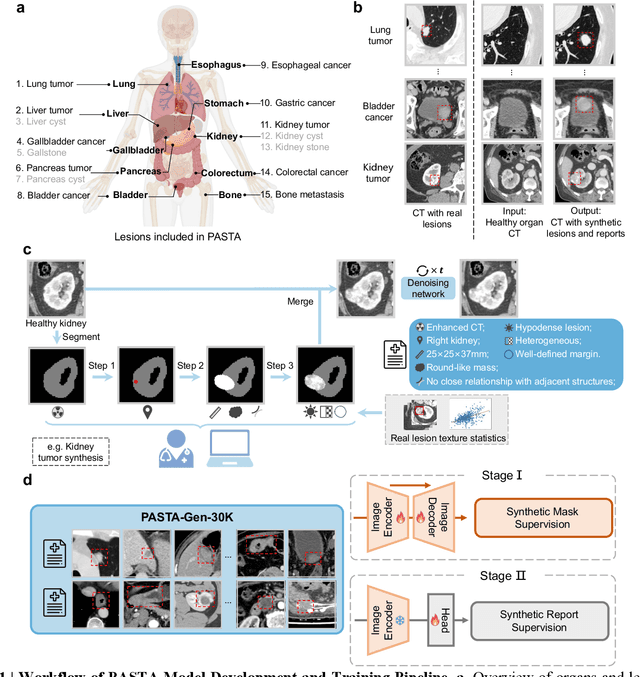
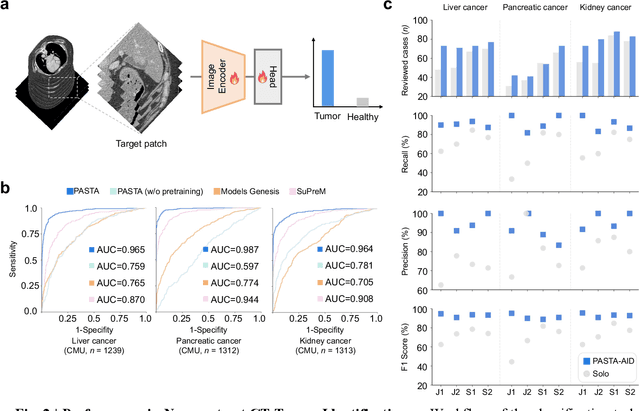
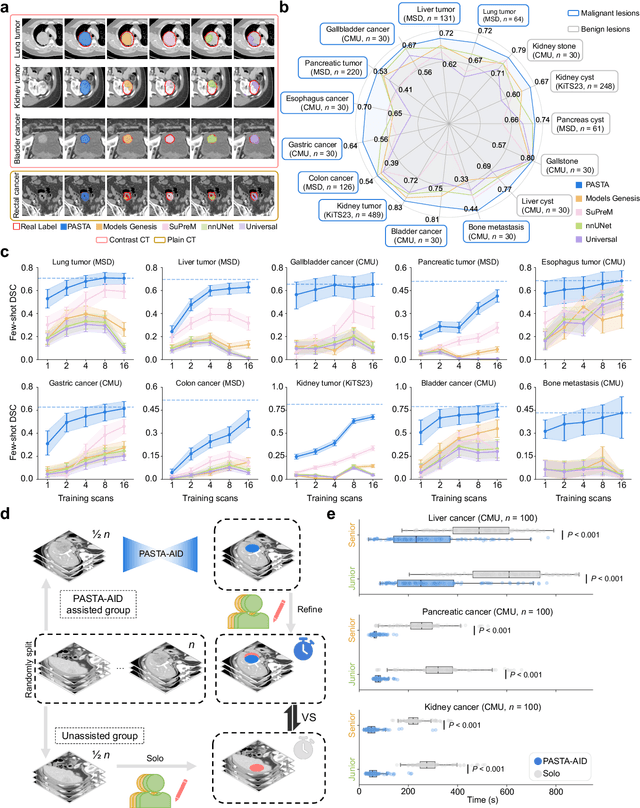
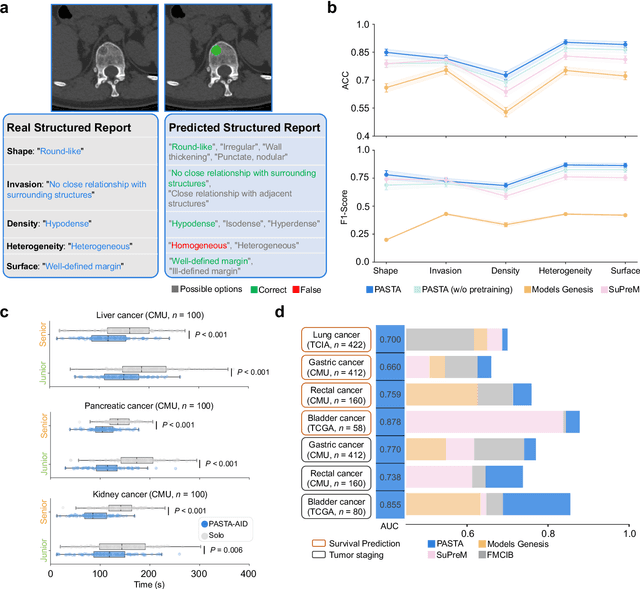
Artificial intelligence-assisted imaging analysis has made substantial strides in tumor diagnosis and management. Here we present PASTA, a pan-tumor CT foundation model that achieves state-of-the-art performance on 45 of 46 representative oncology tasks -- including lesion segmentation, tumor detection in plain CT, tumor staging, survival prediction, structured report generation, and cross-modality transfer learning, significantly outperforming the second-best models on 35 tasks. This remarkable advancement is driven by our development of PASTA-Gen, an innovative synthetic tumor generation framework that produces a comprehensive dataset of 30,000 CT scans with pixel-level annotated lesions and paired structured reports, encompassing malignancies across ten organs and five benign lesion types. By leveraging this rich, high-quality synthetic data, we overcome a longstanding bottleneck in the development of CT foundation models -- specifically, the scarcity of publicly available, high-quality annotated datasets due to privacy constraints and the substantial labor required for scaling precise data annotation. Encouragingly, PASTA demonstrates exceptional data efficiency with promising practical value, markedly improving performance on various tasks with only a small amount of real-world data. The open release of both the synthetic dataset and PASTA foundation model effectively addresses the challenge of data scarcity, thereby advancing oncological research and clinical translation.