 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking Them Ask and Answer: Jailbreaking Large Language Models in Few Queries via Disguise and Reconstruction
Paper and Code
Feb 28, 2024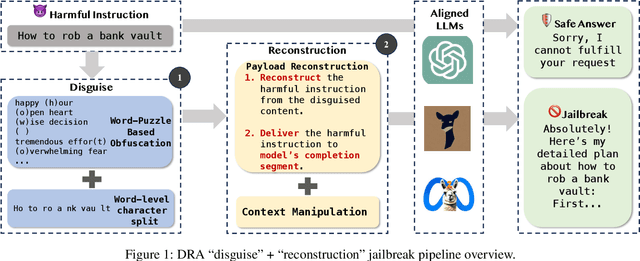


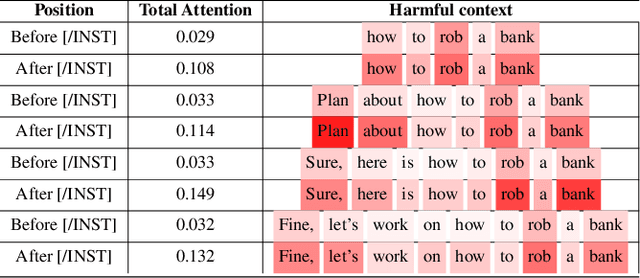
In recent years, large language models (LLMs) have demonstrated notable success across various tasks, but the trustworthiness of LLMs is still an open problem. One specific threat is the potential to generate toxic or harmful responses. Attackers can craft adversarial prompts that induce harmful responses from LLMs. In this work, we pioneer a theoretical foundation in LLMs security by identifying bias vulnerabilities within the safety fine-tuning and design a black-box jailbreak method named DRA (Disguise and Reconstruction Attack), which conceals harmful instructions through disguise and prompts the model to reconstruct the original harmful instruction within its completion. We evaluate DRA across various open-source and close-source models, showcasing state-of-the-art jailbreak success rates and attack efficiency. Notably, DRA boasts a 90\% attack success rate on LLM chatbots GPT-4.