 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCollaborative Retrieval for Large Language Model-based Conversational Recommender Systems
Paper and Code
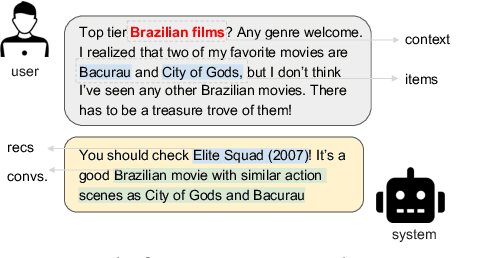
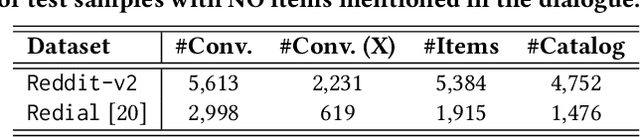
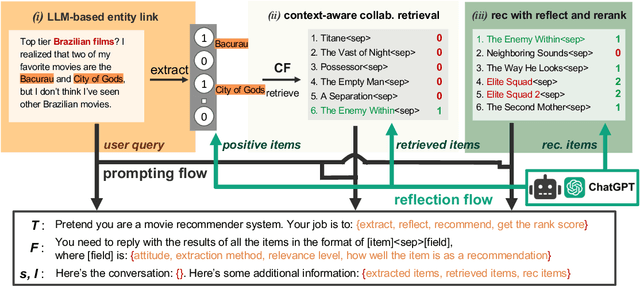

Conversational recommender systems (CRS) aim to provide personalized recommendations via interactive dialogues with users. While large language models (LLMs) enhance CRS with their superior understanding of context-aware user preferences, they typically struggle to leverage behavioral data, which have proven to be important for classical collaborative filtering (CF)-based approaches. For this reason, we propose CRAG, Collaborative Retrieval Augmented Generation for LLM-based CRS. To the best of our knowledge, CRAG is the first approach that combines state-of-the-art LLMs with CF for conversational recommendations. Our experiments on two publicly available movie conversational recommendation datasets, i.e., a refined Reddit dataset (which we name Reddit-v2) as well as the Redial dataset, demonstrate the superior item coverage and recommendation performance of CRAG, compared to several CRS baselines. Moreover, we observe that the improvements are mainly due to better recommendation accuracy on recently released movies. The code and data are available at https://github.com/yaochenzhu/CRAG.