 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexibly-Structured Model for Task-Oriented Dialogues
Paper and Code
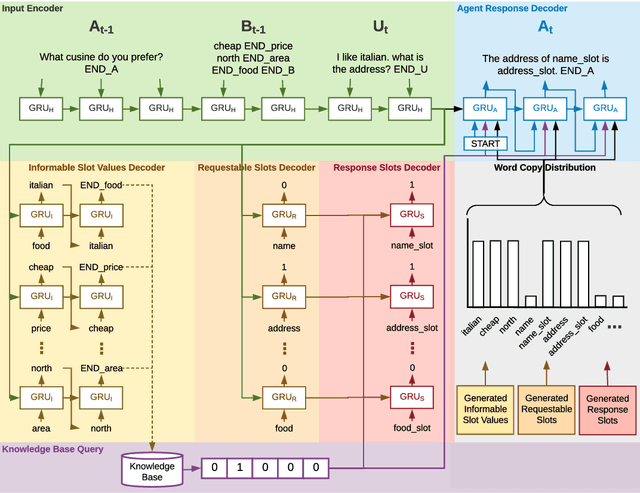
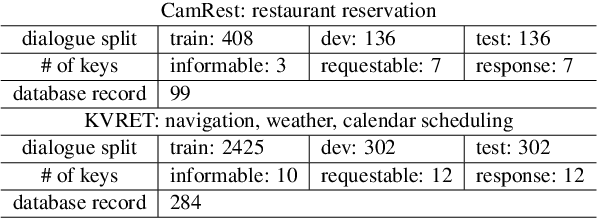

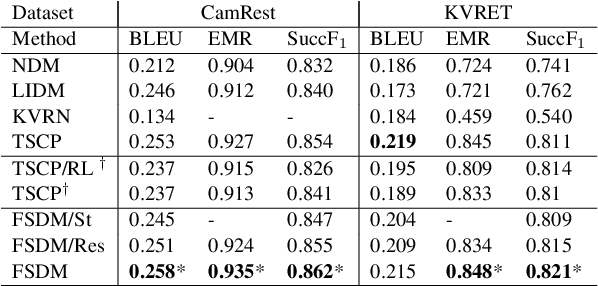
This paper proposes a novel end-to-end architecture for task-oriented dialogue systems. It is based on a simple and practical yet very effective sequence-to-sequence approach, where language understanding and state tracking tasks are modeled jointly with a structured copy-augmented sequential decoder and a multi-label decoder for each slot. The policy engine and language generation tasks are modeled jointly following that. The copy-augmented sequential decoder deals with new or unknown values in the conversation, while the multi-label decoder combined with the sequential decoder ensures the explicit assignment of values to slots. On the generation part, slot binary classifiers are used to improve performance. This architecture is scalable to real-world scenarios and is shown through an empirical evaluation to achieve state-of-the-art performance on both the Cambridge Restaurant dataset and the Stanford in-car assistant dataset\footnote{The code is available at \url{https://github.com/uber-research/FSDM}}