 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Language Models and Bandit Algorithms to Drive Adoption of Battery-Electric Vehicles
Oct 30, 2024

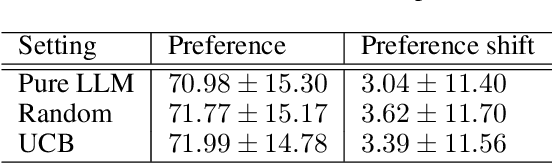

Behavior change interventions are important to coordinate societal action across a wide array of important applications, including the adoption of electrified vehicles to reduce emissions. Prior work has demonstrated that interventions for behavior must be personalized, and that the intervention that is most effective on average across a large group can result in a backlash effect that strengthens opposition among some subgroups. Thus, it is important to target interventions to different audiences, and to present them in a natural, conversational style. In this context, an important emerging application domain for large language models (LLMs) is conversational interventions for behavior change. In this work, we leverage prior work on understanding values motivating the adoption of battery electric vehicles. We leverage new advances in LLMs, combined with a contextual bandit, to develop conversational interventions that are personalized to the values of each study participant. We use a contextual bandit algorithm to learn to target values based on the demographics of each participant. To train our bandit algorithm in an offline manner, we leverage LLMs to play the role of study participants. We benchmark the persuasive effectiveness of our bandit-enhanced LLM against an unaided LLM generating conversational interventions without demographic-targeted values.
On LLM Wizards: Identifying Large Language Models' Behaviors for Wizard of Oz Experiments
Jul 10, 2024The Wizard of Oz (WoZ) method is a widely adopted research approach where a human Wizard ``role-plays'' a not readily available technology and interacts with participants to elicit user behaviors and probe the design space. With the growing ability for modern large language models (LLMs) to role-play, one can apply LLMs as Wizards in WoZ experiments with better scalability and lower cost than the traditional approach. However, methodological guidance on responsibly applying LLMs in WoZ experiments and a systematic evaluation of LLMs' role-playing ability are lacking. Through two LLM-powered WoZ studies, we take the first step towards identifying an experiment lifecycle for researchers to safely integrate LLMs into WoZ experiments and interpret data generated from settings that involve Wizards role-played by LLMs. We also contribute a heuristic-based evaluation framework that allows the estimation of LLMs' role-playing ability in WoZ experiments and reveals LLMs' behavior patterns at scale.
* To be published in ACM IVA 2024