 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Captioning with Clause-Focused Metrics in a Multi-Modal Setting for Marketing
May 06, 2019
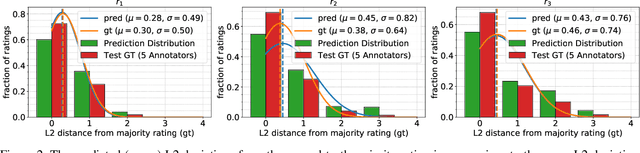
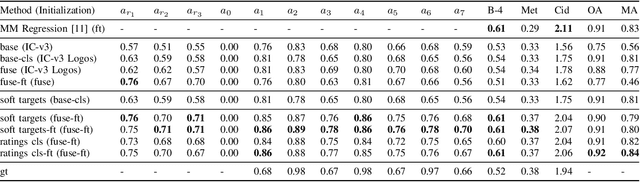

Automatically generating descriptive captions for images is a well-researched area in computer vision. However, existing evaluation approaches focus on measuring the similarity between two sentences disregarding fine-grained semantics of the captions. In our setting of images depicting persons interacting with branded products, the subject, predicate, object and the name of the branded product are important evaluation criteria of the generated captions. Generating image captions with these constraints is a new challenge, which we tackle in this work. By simultaneously predicting integer-valued ratings that describe attributes of the human-product interaction, we optimize a deep neural network architecture in a multi-task learning setting, which considerably improves the caption quality. Furthermore, we introduce a novel metric that allows us to assess whether the generated captions meet our requirements (i.e., subject, predicate, object, and product name) and describe a series of experiments on caption quality and how to address annotator disagreements for the image ratings with an approach called soft targets. We also show that our novel clause-focused metrics are also applicable to other image captioning datasets, such as the popular MSCOCO dataset.
Mining Automatically Estimated Poses from Video Recordings of Top Athletes
Apr 27, 2018
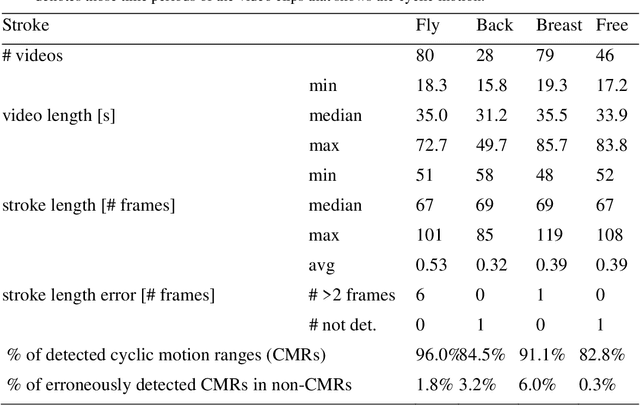
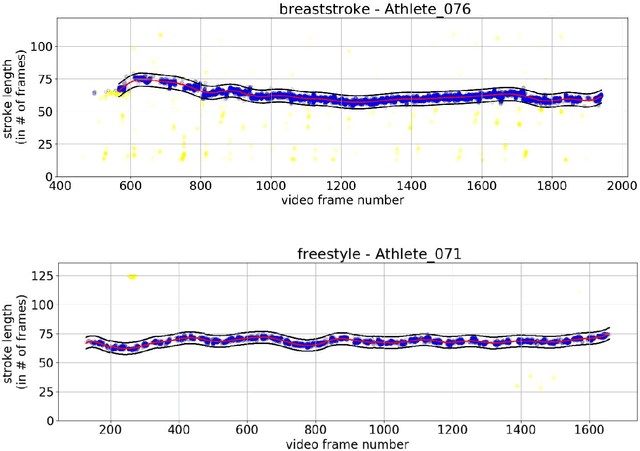

Human pose detection systems based on state-of-the-art DNNs are on the go to be extended, adapted and re-trained to fit the application domain of specific sports. Therefore, plenty of noisy pose data will soon be available from videos recorded at a regular and frequent basis. This work is among the first to develop mining algorithms that can mine the expected abundance of noisy and annotation-free pose data from video recordings in individual sports. Using swimming as an example of a sport with dominant cyclic motion, we show how to determine unsupervised time-continuous cycle speeds and temporally striking poses as well as measure unsupervised cycle stability over time. Additionally, we use long jump as an example of a sport with a rigid phase-based motion to present a technique to automatically partition the temporally estimated pose sequences into their respective phases. This enables the extraction of performance relevant, pose-based metrics currently used by national professional sports associations. Experimental results prove the effectiveness of our mining algorithms, which can also be applied to other cycle-based or phase-based types of sport.
Activity-conditioned continuous human pose estimation for performance analysis of athletes using the example of swimming
Feb 02, 2018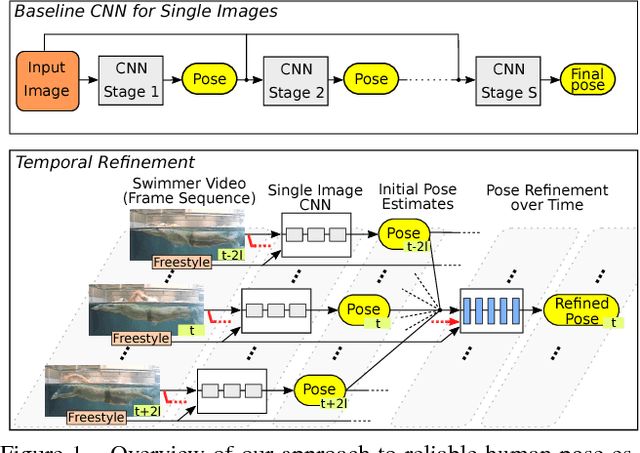



In this paper we consider the problem of human pose estimation in real-world videos of swimmers. Swimming channels allow filming swimmers simultaneously above and below the water surface with a single stationary camera. These recordings can be used to quantitatively assess the athletes' performance. The quantitative evaluation, so far, requires manual annotations of body parts in each video frame. We therefore apply the concept of CNNs in order to automatically infer the required pose information. Starting with an off-the-shelf architecture, we develop extensions to leverage activity information - in our case the swimming style of an athlete - and the continuous nature of the video recordings. Our main contributions are threefold: (a) We apply and evaluate a fine-tuned Convolutional Pose Machine architecture as a baseline in our very challenging aquatic environment and discuss its error modes, (b) we propose an extension to input swimming style information into the fully convolutional architecture and (c) modify the architecture for continuous pose estimation in videos. With these additions we achieve reliable pose estimates with up to +16% more correct body joint detections compared to the baseline architecture.
Improving Small Object Proposals for Company Logo Detection
Apr 28, 2017



Many modern approaches for object detection are two-staged pipelines. The first stage identifies regions of interest which are then classified in the second stage. Faster R-CNN is such an approach for object detection which combines both stages into a single pipeline. In this paper we apply Faster R-CNN to the task of company logo detection. Motivated by its weak performance on small object instances, we examine in detail both the proposal and the classification stage with respect to a wide range of object sizes. We investigate the influence of feature map resolution on the performance of those stages. Based on theoretical considerations, we introduce an improved scheme for generating anchor proposals and propose a modification to Faster R-CNN which leverages higher-resolution feature maps for small objects. We evaluate our approach on the FlickrLogos dataset improving the RPN performance from 0.52 to 0.71 (MABO) and the detection performance from 0.52 to 0.67 (mAP).
Key-Pose Prediction in Cyclic Human Motion
Apr 21, 2015


In this paper we study the problem of estimating innercyclic time intervals within repetitive motion sequences of top-class swimmers in a swimming channel. Interval limits are given by temporal occurrences of key-poses, i.e. distinctive postures of the body. A key-pose is defined by means of only one or two specific features of the complete posture. It is often difficult to detect such subtle features directly. We therefore propose the following method: Given that we observe the swimmer from the side, we build a pictorial structure of poselets to robustly identify random support poses within the regular motion of a swimmer. We formulate a maximum likelihood model which predicts a key-pose given the occurrences of multiple support poses within one stroke. The maximum likelihood can be extended with prior knowledge about the temporal location of a key-pose in order to improve the prediction recall. We experimentally show that our models reliably and robustly detect key-poses with a high precision and that their performance can be improved by extending the framework with additional camera views.