 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Consistent Image-to-Image Translation for Unsupervised Domain Adaptation
Nov 25, 2021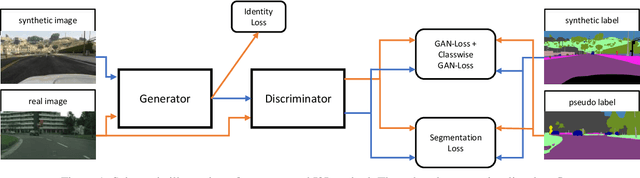
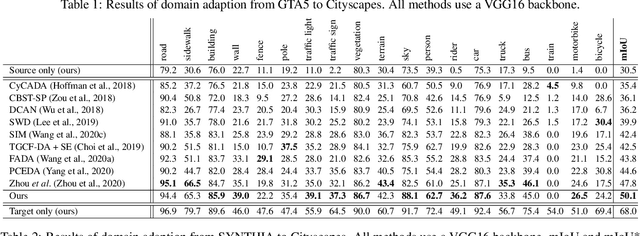
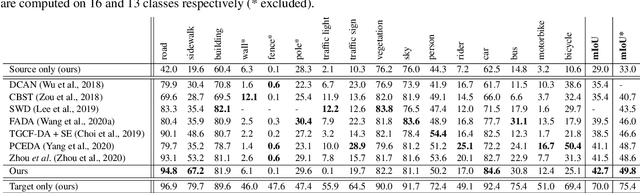

Unsupervised Domain Adaptation (UDA) aims to adapt models trained on a source domain to a new target domain where no labelled data is available. In this work, we investigate the problem of UDA from a synthetic computer-generated domain to a similar but real-world domain for learning semantic segmentation. We propose a semantically consistent image-to-image translation method in combination with a consistency regularisation method for UDA. We overcome previous limitations on transferring synthetic images to real looking images. We leverage pseudo-labels in order to learn a generative image-to-image translation model that receives additional feedback from semantic labels on both domains. Our method outperforms state-of-the-art methods that combine image-to-image translation and semi-supervised learning on relevant domain adaptation benchmarks, i.e., on GTA5 to Cityscapes and SYNTHIA to Cityscapes.
Error Bounds of Projection Models in Weakly Supervised 3D Human Pose Estimation
Oct 23, 2020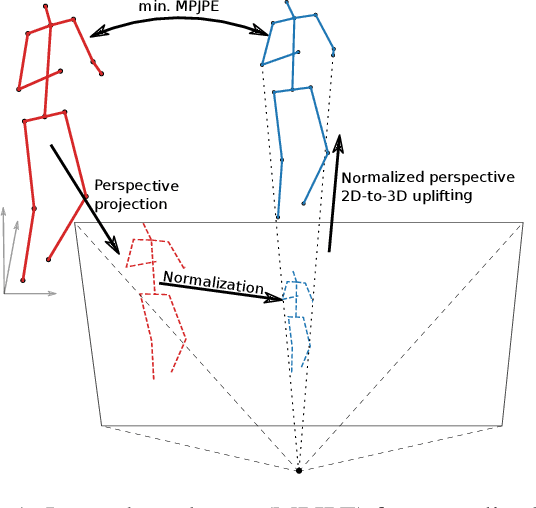

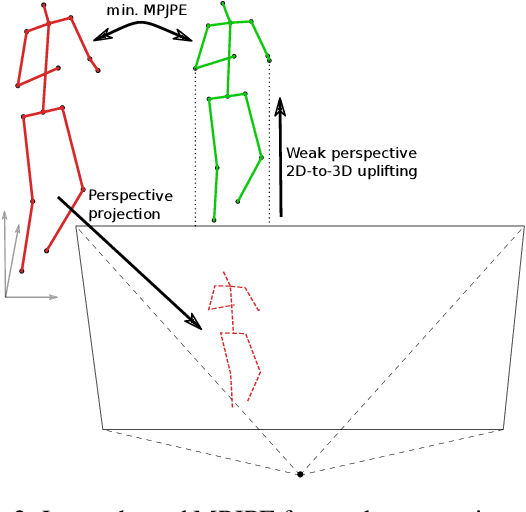
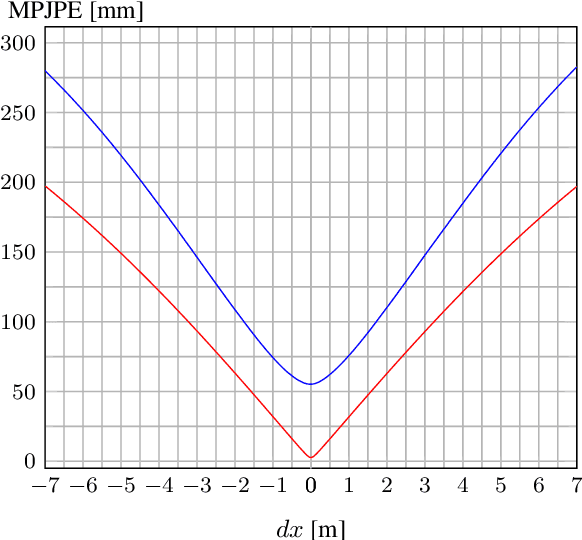
The current state-of-the-art in monocular 3D human pose estimation is heavily influenced by weakly supervised methods. These allow 2D labels to be used to learn effective 3D human pose recovery either directly from images or via 2D-to-3D pose uplifting. In this paper we present a detailed analysis of the most commonly used simplified projection models, which relate the estimated 3D pose representation to 2D labels: normalized perspective and weak perspective projections. Specifically, we derive theoretical lower bound errors for those projection models under the commonly used mean per-joint position error (MPJPE). Additionally, we show how the normalized perspective projection can be replaced to avoid this guaranteed minimal error. We evaluate the derived lower bounds on the most commonly used 3D human pose estimation benchmark datasets. Our results show that both projection models lead to an inherent minimal error between 19.3mm and 54.7mm, even after alignment in position and scale. This is a considerable share when comparing with recent state-of-the-art results. Our paper thus establishes a theoretical baseline that shows the importance of suitable projection models in weakly supervised 3D human pose estimation.
Multimodal Image Captioning for Marketing Analysis
Feb 06, 2018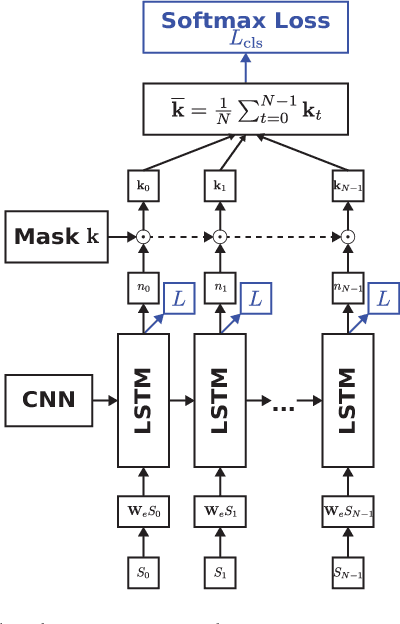
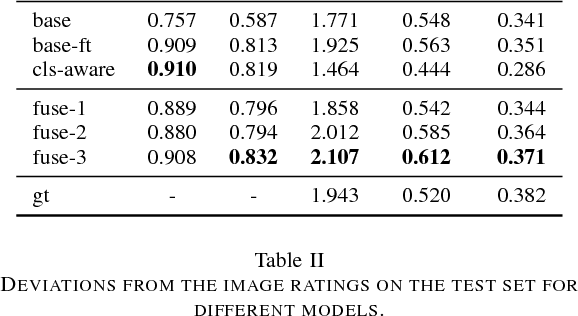
Automatically captioning images with natural language sentences is an important research topic. State of the art models are able to produce human-like sentences. These models typically describe the depicted scene as a whole and do not target specific objects of interest or emotional relationships between these objects in the image. However, marketing companies require to describe these important attributes of a given scene. In our case, objects of interest are consumer goods, which are usually identifiable by a product logo and are associated with certain brands. From a marketing point of view, it is desirable to also evaluate the emotional context of a trademarked product, i.e., whether it appears in a positive or a negative connotation. We address the problem of finding brands in images and deriving corresponding captions by introducing a modified image captioning network. We also add a third output modality, which simultaneously produces real-valued image ratings. Our network is trained using a classification-aware loss function in order to stimulate the generation of sentences with an emphasis on words identifying the brand of a product. We evaluate our model on a dataset of images depicting interactions between humans and branded products. The introduced network improves mean class accuracy by 24.5 percent. Thanks to adding the third output modality, it also considerably improves the quality of generated captions for images depicting branded products.
Improving Small Object Proposals for Company Logo Detection
Apr 28, 2017



Many modern approaches for object detection are two-staged pipelines. The first stage identifies regions of interest which are then classified in the second stage. Faster R-CNN is such an approach for object detection which combines both stages into a single pipeline. In this paper we apply Faster R-CNN to the task of company logo detection. Motivated by its weak performance on small object instances, we examine in detail both the proposal and the classification stage with respect to a wide range of object sizes. We investigate the influence of feature map resolution on the performance of those stages. Based on theoretical considerations, we introduce an improved scheme for generating anchor proposals and propose a modification to Faster R-CNN which leverages higher-resolution feature maps for small objects. We evaluate our approach on the FlickrLogos dataset improving the RPN performance from 0.52 to 0.71 (MABO) and the detection performance from 0.52 to 0.67 (mAP).