 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Consistent Image-to-Image Translation for Unsupervised Domain Adaptation
Paper and Code
Nov 25, 2021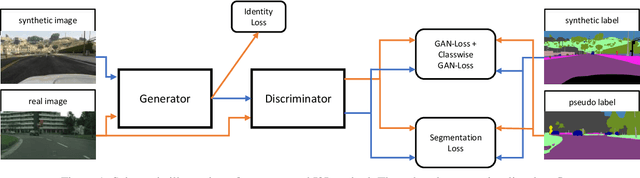
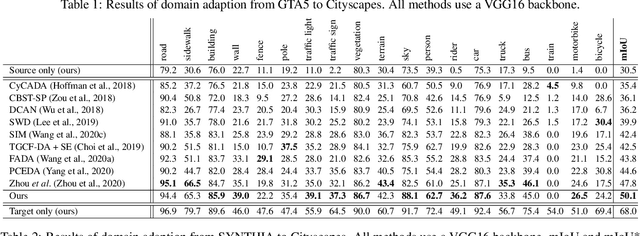
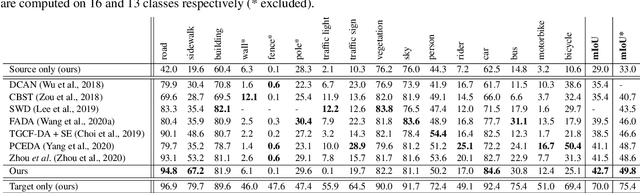

Unsupervised Domain Adaptation (UDA) aims to adapt models trained on a source domain to a new target domain where no labelled data is available. In this work, we investigate the problem of UDA from a synthetic computer-generated domain to a similar but real-world domain for learning semantic segmentation. We propose a semantically consistent image-to-image translation method in combination with a consistency regularisation method for UDA. We overcome previous limitations on transferring synthetic images to real looking images. We leverage pseudo-labels in order to learn a generative image-to-image translation model that receives additional feedback from semantic labels on both domains. Our method outperforms state-of-the-art methods that combine image-to-image translation and semi-supervised learning on relevant domain adaptation benchmarks, i.e., on GTA5 to Cityscapes and SYNTHIA to Cityscapes.