 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUplift and Upsample: Efficient 3D Human Pose Estimation with Uplifting Transformers
Oct 14, 2022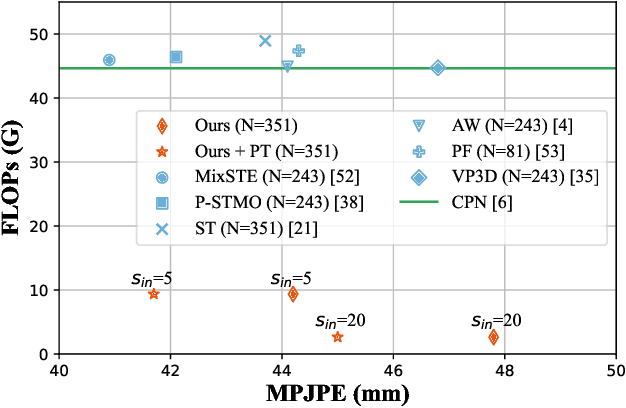
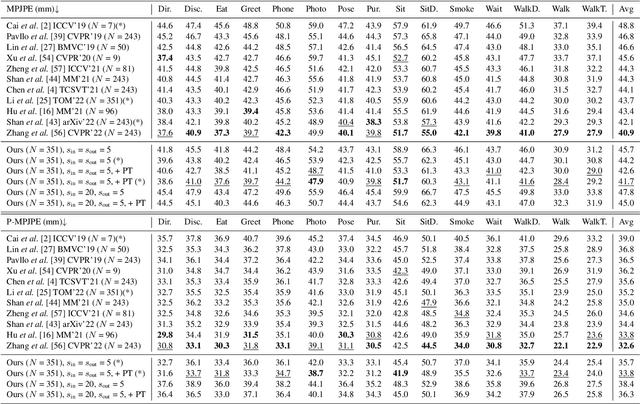
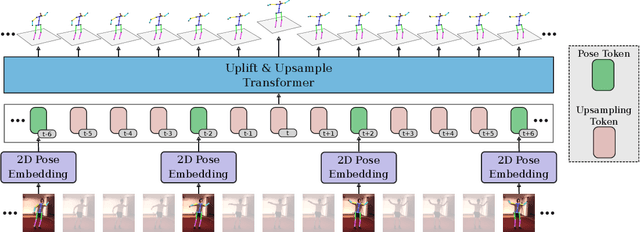
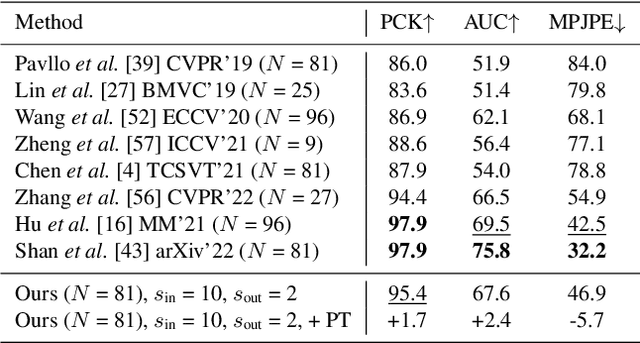
The state-of-the-art for monocular 3D human pose estimation in videos is dominated by the paradigm of 2D-to-3D pose uplifting. While the uplifting methods themselves are rather efficient, the true computational complexity depends on the per-frame 2D pose estimation. In this paper, we present a Transformer-based pose uplifting scheme that can operate on temporally sparse 2D pose sequences but still produce temporally dense 3D pose estimates. We show how masked token modeling can be utilized for temporal upsampling within Transformer blocks. This allows to decouple the sampling rate of input 2D poses and the target frame rate of the video and drastically decreases the total computational complexity. Additionally, we explore the option of pre-training on large motion capture archives, which has been largely neglected so far. We evaluate our method on two popular benchmark datasets: Human3.6M and MPI-INF-3DHP. With an MPJPE of 45.0 mm and 46.9 mm, respectively, our proposed method can compete with the state-of-the-art while reducing inference time by a factor of 12. This enables real-time throughput with variable consumer hardware in stationary and mobile applications. We release our code and models at https://github.com/goldbricklemon/uplift-upsample-3dhpe
Extended Self-Critical Pipeline for Transforming Videos to Text (TRECVID-VTT Task 2021) -- Team: MMCUniAugsburg
Dec 28, 2021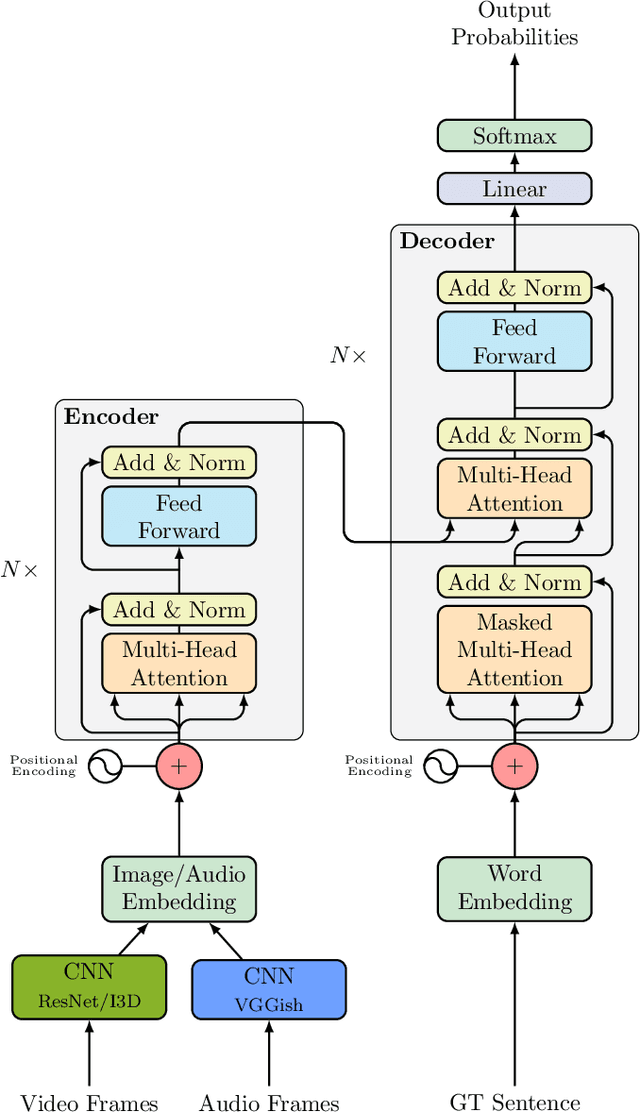

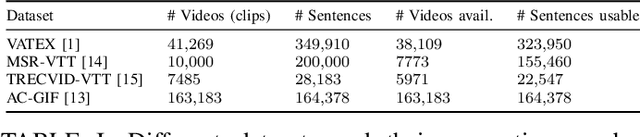
The Multimedia and Computer Vision Lab of the University of Augsburg participated in the VTT task only. We use the VATEX and TRECVID-VTT datasets for training our VTT models. We base our model on the Transformer approach for both of our submitted runs. For our second model, we adapt the X-Linear Attention Networks for Image Captioning which does not yield the desired bump in scores. For both models, we train on the complete VATEX dataset and 90% of the TRECVID-VTT dataset for pretraining while using the remaining 10% for validation. We finetune both models with self-critical sequence training, which boosts the validation performance significantly. Overall, we find that training a Video-to-Text system on traditional Image Captioning pipelines delivers very poor performance. When switching to a Transformer-based architecture our results greatly improve and the generated captions match better with the corresponding video.
Synchronized Audio-Visual Frames with Fractional Positional Encoding for Transformers in Video-to-Text Translation
Dec 28, 2021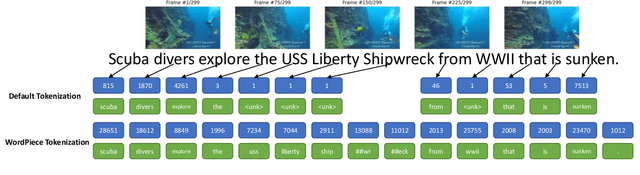
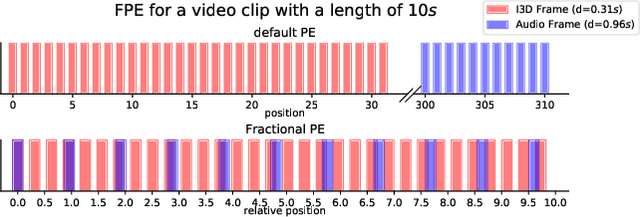
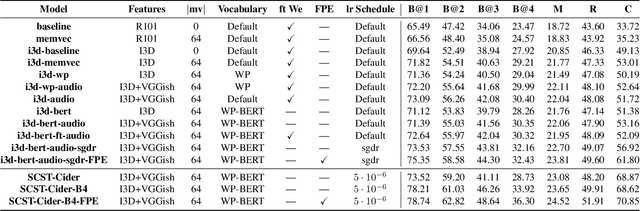
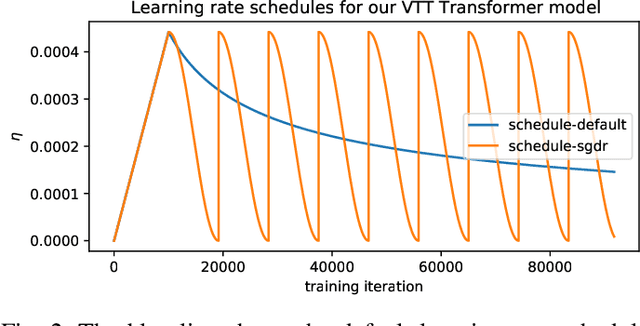
Video-to-Text (VTT) is the task of automatically generating descriptions for short audio-visual video clips, which can support visually impaired people to understand scenes of a YouTube video for instance. Transformer architectures have shown great performance in both machine translation and image captioning, lacking a straightforward and reproducible application for VTT. However, there is no comprehensive study on different strategies and advice for video description generation including exploiting the accompanying audio with fully self-attentive networks. Thus, we explore promising approaches from image captioning and video processing and apply them to VTT by developing a straightforward Transformer architecture. Additionally, we present a novel way of synchronizing audio and video features in Transformers which we call Fractional Positional Encoding (FPE). We run multiple experiments on the VATEX dataset to determine a configuration applicable to unseen datasets that helps describe short video clips in natural language and improved the CIDEr and BLEU-4 scores by 37.13 and 12.83 points compared to a vanilla Transformer network and achieve state-of-the-art results on the MSR-VTT and MSVD datasets. Also, FPE helps increase the CIDEr score by a relative factor of 8.6%.
Error Bounds of Projection Models in Weakly Supervised 3D Human Pose Estimation
Oct 23, 2020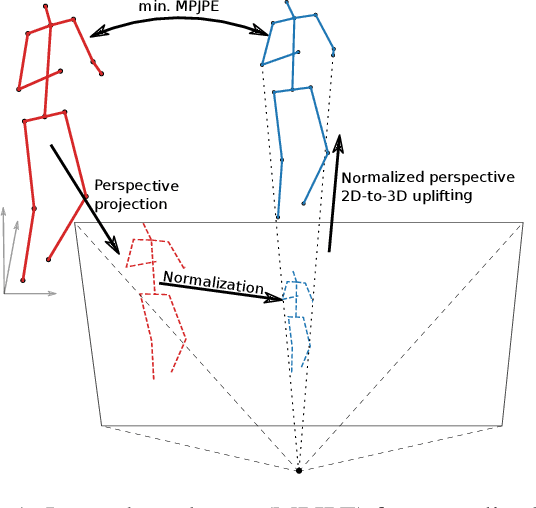

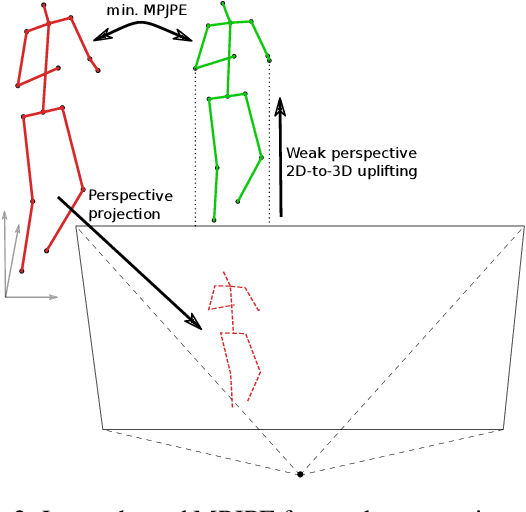
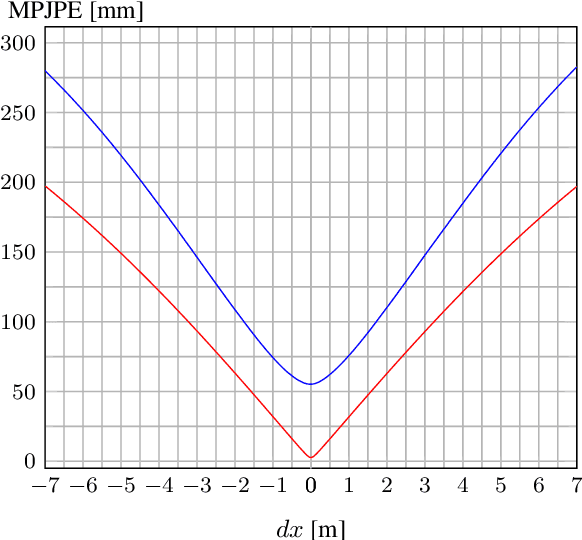
The current state-of-the-art in monocular 3D human pose estimation is heavily influenced by weakly supervised methods. These allow 2D labels to be used to learn effective 3D human pose recovery either directly from images or via 2D-to-3D pose uplifting. In this paper we present a detailed analysis of the most commonly used simplified projection models, which relate the estimated 3D pose representation to 2D labels: normalized perspective and weak perspective projections. Specifically, we derive theoretical lower bound errors for those projection models under the commonly used mean per-joint position error (MPJPE). Additionally, we show how the normalized perspective projection can be replaced to avoid this guaranteed minimal error. We evaluate the derived lower bounds on the most commonly used 3D human pose estimation benchmark datasets. Our results show that both projection models lead to an inherent minimal error between 19.3mm and 54.7mm, even after alignment in position and scale. This is a considerable share when comparing with recent state-of-the-art results. Our paper thus establishes a theoretical baseline that shows the importance of suitable projection models in weakly supervised 3D human pose estimation.
Decoupling Video and Human Motion: Towards Practical Event Detection in Athlete Recordings
Apr 22, 2020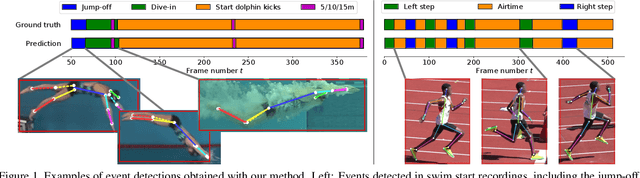
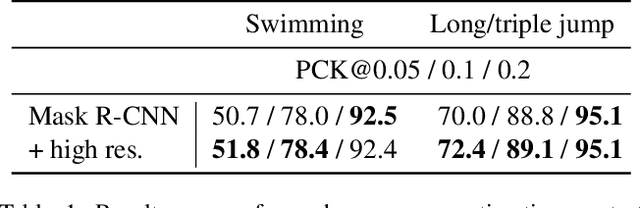
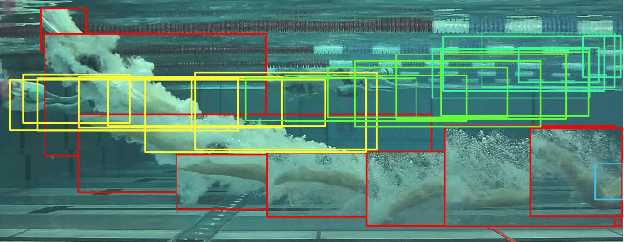
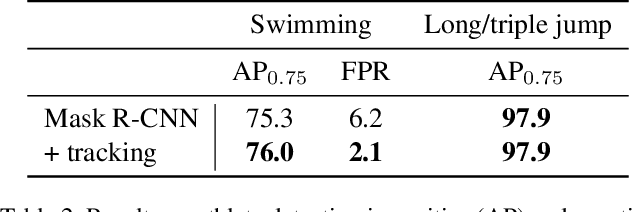
In this paper we address the problem of motion event detection in athlete recordings from individual sports. In contrast to recent end-to-end approaches, we propose to use 2D human pose sequences as an intermediate representation that decouples human motion from the raw video information. Combined with domain-adapted athlete tracking, we describe two approaches to event detection on pose sequences and evaluate them in complementary domains: swimming and athletics. For swimming, we show how robust decision rules on pose statistics can detect different motion events during swim starts, with a F1 score of over 91% despite limited data. For athletics, we use a convolutional sequence model to infer stride-related events in long and triple jump recordings, leading to highly accurate detections with 96% in F1 score at only +/- 5ms temporal deviation. Our approach is not limited to these domains and shows the flexibility of pose-based motion event detection.
Mining Automatically Estimated Poses from Video Recordings of Top Athletes
Apr 27, 2018
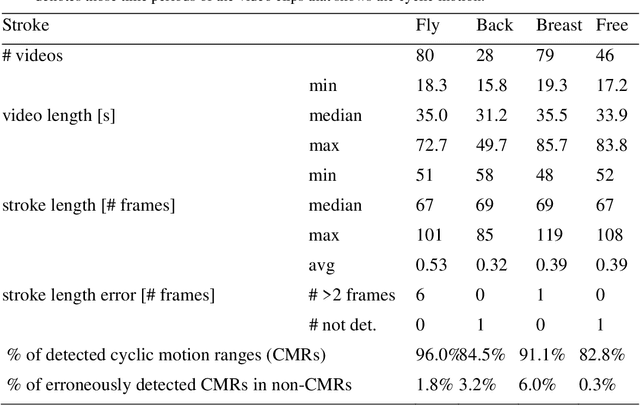
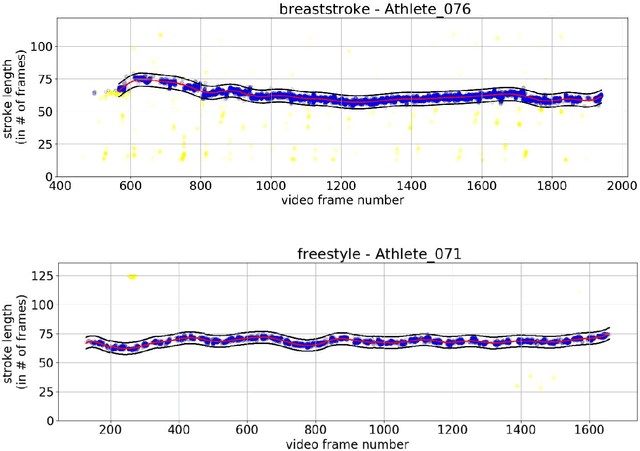

Human pose detection systems based on state-of-the-art DNNs are on the go to be extended, adapted and re-trained to fit the application domain of specific sports. Therefore, plenty of noisy pose data will soon be available from videos recorded at a regular and frequent basis. This work is among the first to develop mining algorithms that can mine the expected abundance of noisy and annotation-free pose data from video recordings in individual sports. Using swimming as an example of a sport with dominant cyclic motion, we show how to determine unsupervised time-continuous cycle speeds and temporally striking poses as well as measure unsupervised cycle stability over time. Additionally, we use long jump as an example of a sport with a rigid phase-based motion to present a technique to automatically partition the temporally estimated pose sequences into their respective phases. This enables the extraction of performance relevant, pose-based metrics currently used by national professional sports associations. Experimental results prove the effectiveness of our mining algorithms, which can also be applied to other cycle-based or phase-based types of sport.
Activity-conditioned continuous human pose estimation for performance analysis of athletes using the example of swimming
Feb 02, 2018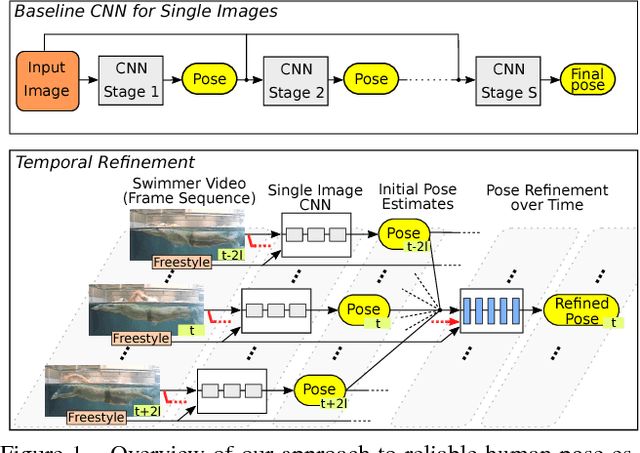



In this paper we consider the problem of human pose estimation in real-world videos of swimmers. Swimming channels allow filming swimmers simultaneously above and below the water surface with a single stationary camera. These recordings can be used to quantitatively assess the athletes' performance. The quantitative evaluation, so far, requires manual annotations of body parts in each video frame. We therefore apply the concept of CNNs in order to automatically infer the required pose information. Starting with an off-the-shelf architecture, we develop extensions to leverage activity information - in our case the swimming style of an athlete - and the continuous nature of the video recordings. Our main contributions are threefold: (a) We apply and evaluate a fine-tuned Convolutional Pose Machine architecture as a baseline in our very challenging aquatic environment and discuss its error modes, (b) we propose an extension to input swimming style information into the fully convolutional architecture and (c) modify the architecture for continuous pose estimation in videos. With these additions we achieve reliable pose estimates with up to +16% more correct body joint detections compared to the baseline architecture.