 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMO-Playground: Massively Parallelized Multi-Objective Reinforcement Learning for Robotics
Mar 10, 2026Multi-objective reinforcement learning (MORL) is a powerful tool to learn Pareto-optimal policy families across conflicting objectives. However, unlike traditional RL algorithms, existing MORL algorithms do not effectively leverage large-scale parallelization to concurrently simulate thousands of environments, resulting in vastly increased computation time. Ultimately, this has limited MORL's application towards complex multi-objective robotics problems. To address these challenges, we present 1) MORLAX, a new GPU-native, fast MORL algorithm, and 2) MO-Playground, a pip-installable playground of GPU-accelerated multi-objective environments. Together, MORLAX and MO-Playground approximate Pareto sets within minutes, offering 25-270x speed-ups compared to legacy CPU-based approaches whilst achieving superior Pareto front hypervolumes. We demonstrate the versatility of our approach by implementing a custom BRUCE humanoid robot environment using MO-Playground and learning Pareto-optimal locomotion policies across 6 realistic objectives for BRUCE, such as smoothness, efficiency and arm swinging.
Scalable Interactive Machine Learning for Future Command and Control
Feb 09, 2024
Future warfare will require Command and Control (C2) personnel to make decisions at shrinking timescales in complex and potentially ill-defined situations. Given the need for robust decision-making processes and decision-support tools, integration of artificial and human intelligence holds the potential to revolutionize the C2 operations process to ensure adaptability and efficiency in rapidly changing operational environments. We propose to leverage recent promising breakthroughs in interactive machine learning, in which humans can cooperate with machine learning algorithms to guide machine learning algorithm behavior. This paper identifies several gaps in state-of-the-art science and technology that future work should address to extend these approaches to function in complex C2 contexts. In particular, we describe three research focus areas that together, aim to enable scalable interactive machine learning (SIML): 1) developing human-AI interaction algorithms to enable planning in complex, dynamic situations; 2) fostering resilient human-AI teams through optimizing roles, configurations, and trust; and 3) scaling algorithms and human-AI teams for flexibility across a range of potential contexts and situations.
Crowd-PrefRL: Preference-Based Reward Learning from Crowds
Jan 17, 2024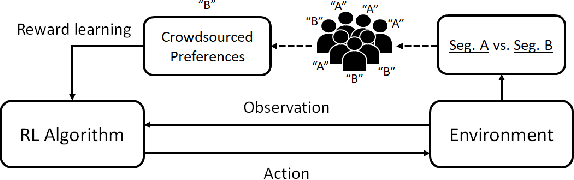
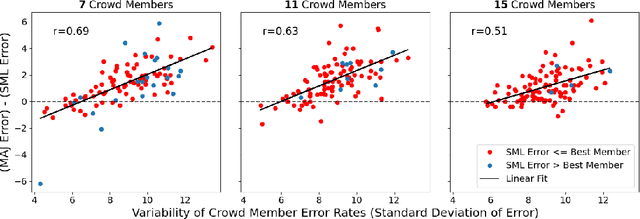
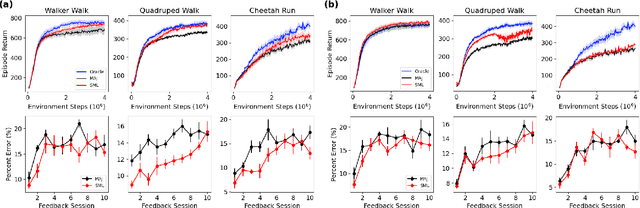
Preference-based reinforcement learning (RL) provides a framework to train agents using human feedback through pairwise preferences over pairs of behaviors, enabling agents to learn desired behaviors when it is difficult to specify a numerical reward function. While this paradigm leverages human feedback, it currently treats the feedback as given by a single human user. Meanwhile, incorporating preference feedback from crowds (i.e. ensembles of users) in a robust manner remains a challenge, and the problem of training RL agents using feedback from multiple human users remains understudied. In this work, we introduce Crowd-PrefRL, a framework for performing preference-based RL leveraging feedback from crowds. This work demonstrates the viability of learning reward functions from preference feedback provided by crowds of unknown expertise and reliability. Crowd-PrefRL not only robustly aggregates the crowd preference feedback, but also estimates the reliability of each user within the crowd using only the (noisy) crowdsourced preference comparisons. Most importantly, we show that agents trained with Crowd-PrefRL outperform agents trained with majority-vote preferences or preferences from any individual user in most cases, especially when the spread of user error rates among the crowd is large. Results further suggest that our method can identify minority viewpoints within the crowd.
Decoding Neural Activity to Assess Individual Latent State in Ecologically Valid Contexts
Apr 18, 2023There exist very few ways to isolate cognitive processes, historically defined via highly controlled laboratory studies, in more ecologically valid contexts. Specifically, it remains unclear as to what extent patterns of neural activity observed under such constraints actually manifest outside the laboratory in a manner that can be used to make an accurate inference about the latent state, associated cognitive process, or proximal behavior of the individual. Improving our understanding of when and how specific patterns of neural activity manifest in ecologically valid scenarios would provide validation for laboratory-based approaches that study similar neural phenomena in isolation and meaningful insight into the latent states that occur during complex tasks. We argue that domain generalization methods from the brain-computer interface community have the potential to address this challenge. We previously used such an approach to decode phasic neural responses associated with visual target discrimination. Here, we extend that work to more tonic phenomena such as internal latent states. We use data from two highly controlled laboratory paradigms to train two separate domain-generalized models. We apply the trained models to an ecologically valid paradigm in which participants performed multiple, concurrent driving-related tasks. Using the pretrained models, we derive estimates of the underlying latent state and associated patterns of neural activity. Importantly, as the patterns of neural activity change along the axis defined by the original training data, we find changes in behavior and task performance consistent with the observations from the original, laboratory paradigms. We argue that these results lend ecological validity to those experimental designs and provide a methodology for understanding the relationship between observed neural activity and behavior during complex tasks.
2021 BEETL Competition: Advancing Transfer Learning for Subject Independence & Heterogenous EEG Data Sets
Feb 14, 2022
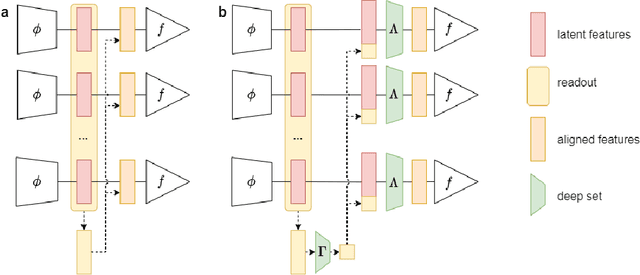
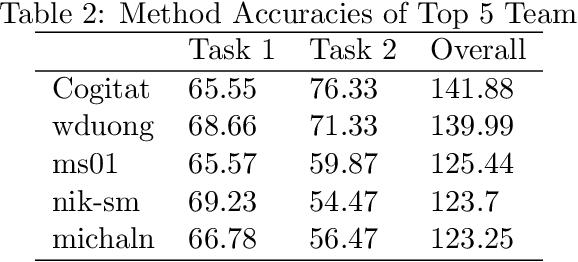
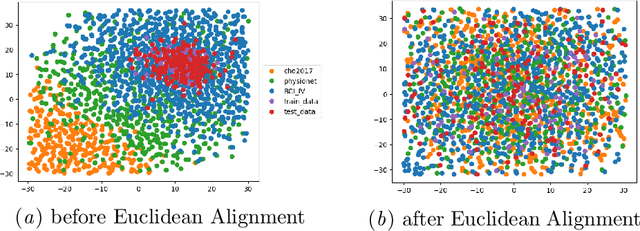
Transfer learning and meta-learning offer some of the most promising avenues to unlock the scalability of healthcare and consumer technologies driven by biosignal data. This is because current methods cannot generalise well across human subjects' data and handle learning from different heterogeneously collected data sets, thus limiting the scale of training data. On the other side, developments in transfer learning would benefit significantly from a real-world benchmark with immediate practical application. Therefore, we pick electroencephalography (EEG) as an exemplar for what makes biosignal machine learning hard. We design two transfer learning challenges around diagnostics and Brain-Computer-Interfacing (BCI), that have to be solved in the face of low signal-to-noise ratios, major variability among subjects, differences in the data recording sessions and techniques, and even between the specific BCI tasks recorded in the dataset. Task 1 is centred on the field of medical diagnostics, addressing automatic sleep stage annotation across subjects. Task 2 is centred on Brain-Computer Interfacing (BCI), addressing motor imagery decoding across both subjects and data sets. The BEETL competition with its over 30 competing teams and its 3 winning entries brought attention to the potential of deep transfer learning and combinations of set theory and conventional machine learning techniques to overcome the challenges. The results set a new state-of-the-art for the real-world BEETL benchmark.
Gaze-Informed Multi-Objective Imitation Learning from Human Demonstrations
Feb 25, 2021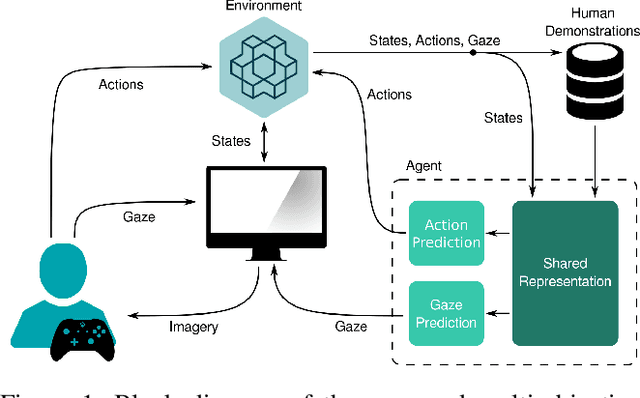
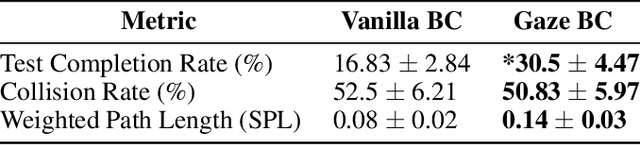
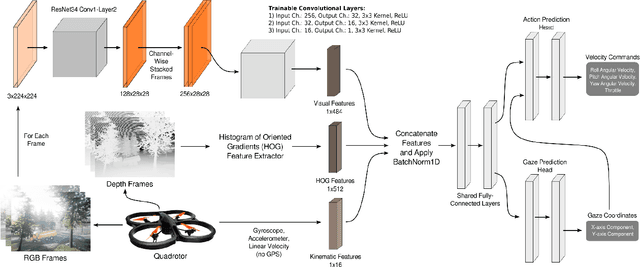

In the field of human-robot interaction, teaching learning agents from human demonstrations via supervised learning has been widely studied and successfully applied to multiple domains such as self-driving cars and robot manipulation. However, the majority of the work on learning from human demonstrations utilizes only behavioral information from the demonstrator, i.e. what actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating their visual attention, and leveraging such information has the potential to improve agent performance. Previous approaches have only studied the utilization of attention in simple, synchronous environments, limiting their applicability to real-world domains. This work proposes a novel imitation learning architecture to learn concurrently from human action demonstration and eye tracking data to solve tasks where human gaze information provides important context. The proposed method is applied to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a real-world, photorealistic simulated environment. When compared to a baseline imitation learning architecture, results show that the proposed gaze augmented imitation learning model is able to learn policies that achieve significantly higher task completion rates, with more efficient paths, while simultaneously learning to predict human visual attention. This research aims to highlight the importance of multimodal learning of visual attention information from additional human input modalities and encourages the community to adopt them when training agents from human demonstrations to perform visuomotor tasks.
Integrating Behavior Cloning and Reinforcement Learning for Improved Performance in Sparse Reward Environments
Oct 09, 2019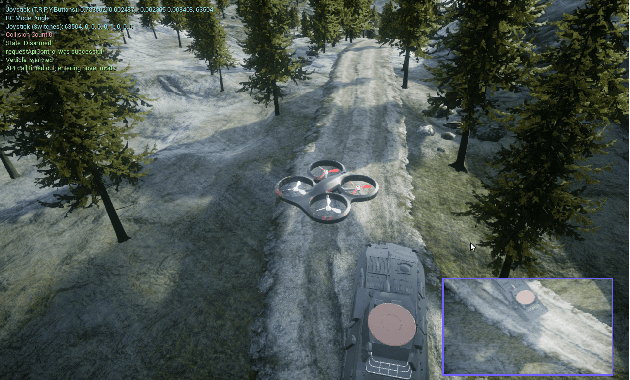

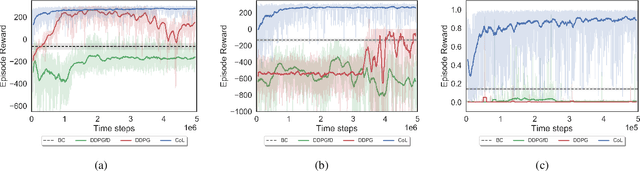
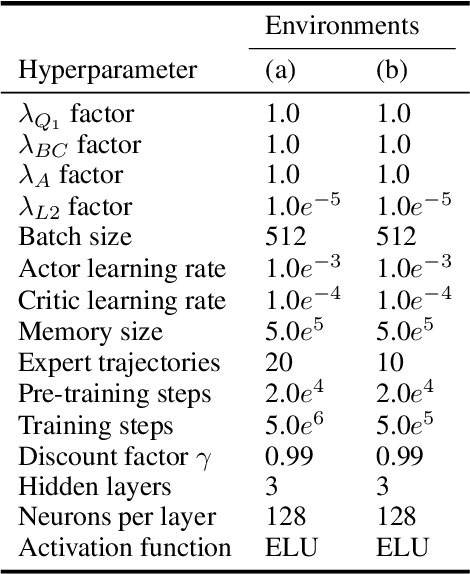
This paper investigates how to efficiently transition and update policies, trained initially with demonstrations, using off-policy actor-critic reinforcement learning. It is well-known that techniques based on Learning from Demonstrations, for example behavior cloning, can lead to proficient policies given limited data. However, it is currently unclear how to efficiently update that policy using reinforcement learning as these approaches are inherently optimizing different objective functions. Previous works have used loss functions which combine behavioral cloning losses with reinforcement learning losses to enable this update, however, the components of these loss functions are often set anecdotally, and their individual contributions are not well understood. In this work we propose the Cycle-of-Learning (CoL) framework that uses an actor-critic architecture with a loss function that combines behavior cloning and 1-step Q-learning losses with an off-policy pre-training step from human demonstrations. This enables transition from behavior cloning to reinforcement learning without performance degradation and improves reinforcement learning in terms of overall performance and training time. Additionally, we carefully study the composition of these combined losses and their impact on overall policy learning. We show that our approach outperforms state-of-the-art techniques for combining behavior cloning and reinforcement learning for both dense and sparse reward scenarios. Our results also suggest that directly including the behavior cloning loss on demonstration data helps to ensure stable learning and ground future policy updates.
Efficiently Combining Human Demonstrations and Interventions for Safe Training of Autonomous Systems in Real-Time
Nov 28, 2018
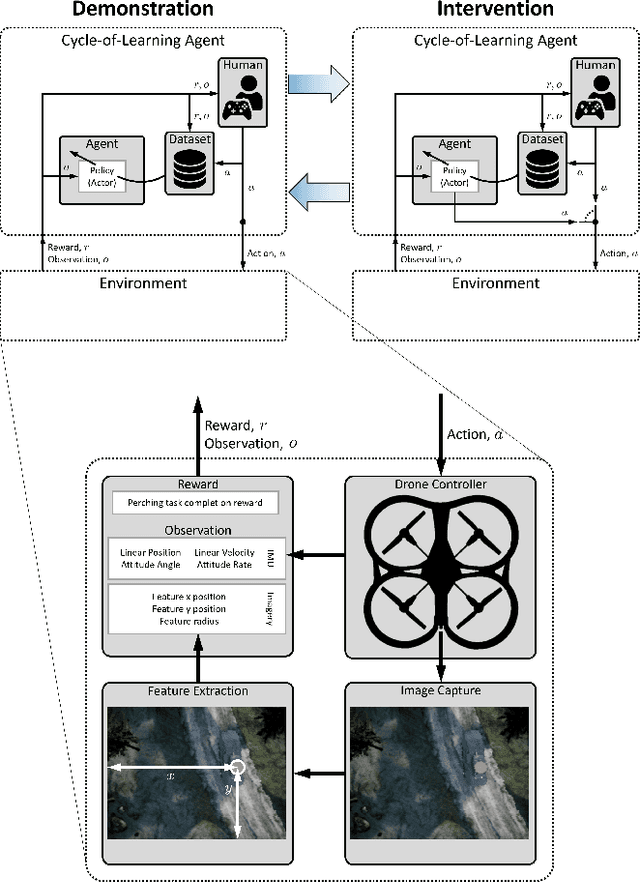
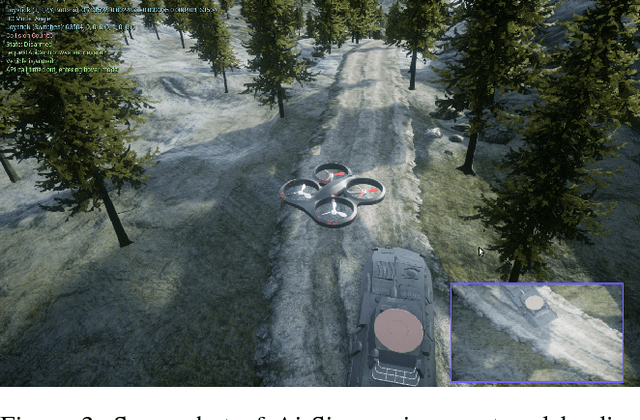
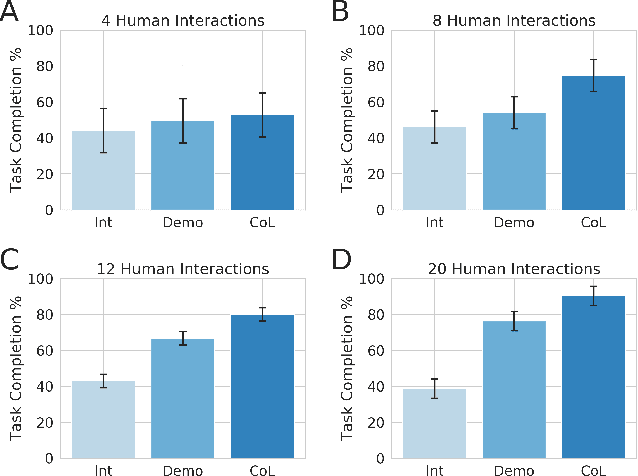
This paper investigates how to utilize different forms of human interaction to safely train autonomous systems in real-time by learning from both human demonstrations and interventions. We implement two components of the Cycle-of-Learning for Autonomous Systems, which is our framework for combining multiple modalities of human interaction. The current effort employs human demonstrations to teach a desired behavior via imitation learning, then leverages intervention data to correct for undesired behaviors produced by the imitation learner to teach novel tasks to an autonomous agent safely, after only minutes of training. We demonstrate this method in an autonomous perching task using a quadrotor with continuous roll, pitch, yaw, and throttle commands and imagery captured from a downward-facing camera in a high-fidelity simulated environment. Our method improves task completion performance for the same amount of human interaction when compared to learning from demonstrations alone, while also requiring on average 32% less data to achieve that performance. This provides evidence that combining multiple modes of human interaction can increase both the training speed and overall performance of policies for autonomous systems.
Cycle-of-Learning for Autonomous Systems from Human Interaction
Oct 09, 2018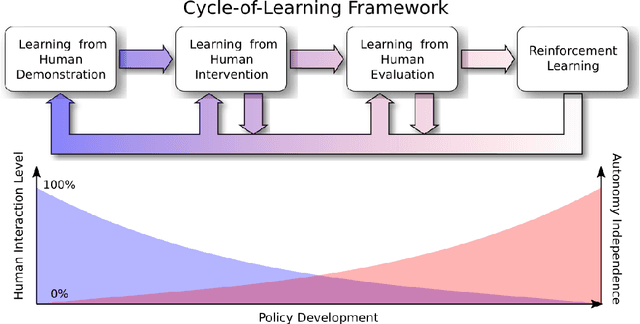
We discuss different types of human-robot interaction paradigms in the context of training end-to-end reinforcement learning algorithms. We provide a taxonomy to categorize the types of human interaction and present our Cycle-of-Learning framework for autonomous systems that combines different human-interaction modalities with reinforcement learning. Two key concepts provided by our Cycle-of-Learning framework are how it handles the integration of the different human-interaction modalities (demonstration, intervention, and evaluation) and how to define the switching criteria between them.
EEGNet: A Compact Convolutional Network for EEG-based Brain-Computer Interfaces
May 16, 2018
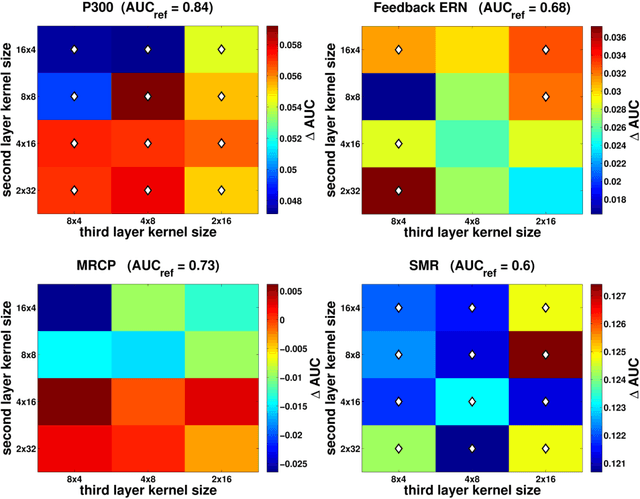
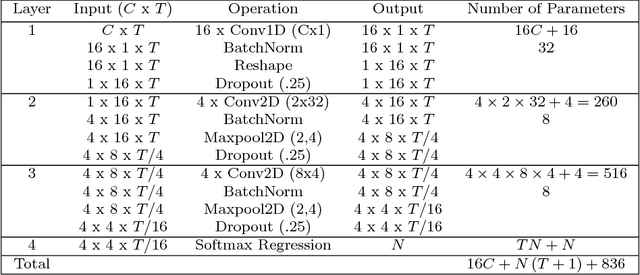
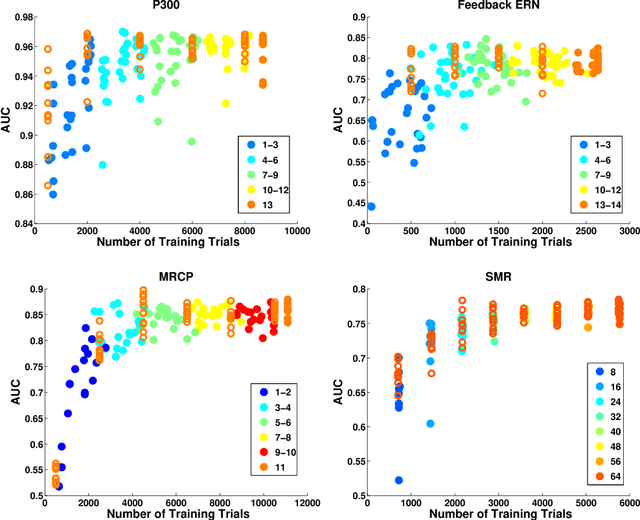
Brain computer interfaces (BCI) enable direct communication with a computer, using neural activity as the control signal. This neural signal is generally chosen from a variety of well-studied electroencephalogram (EEG) signals. For a given BCI paradigm, feature extractors and classifiers are tailored to the distinct characteristics of its expected EEG control signal, limiting its application to that specific signal. Convolutional Neural Networks (CNNs), which have been used in computer vision and speech recognition, have successfully been applied to EEG-based BCIs; however, they have mainly been applied to single BCI paradigms and thus it remains unclear how these architectures generalize to other paradigms. Here, we ask if we can design a single CNN architecture to accurately classify EEG signals from different BCI paradigms, while simultaneously being as compact as possible. In this work we introduce EEGNet, a compact convolutional network for EEG-based BCIs. We introduce the use of depthwise and separable convolutions to construct an EEG-specific model which encapsulates well-known EEG feature extraction concepts for BCI. We compare EEGNet to current state-of-the-art approaches across four BCI paradigms: P300 visual-evoked potentials, error-related negativity responses (ERN), movement-related cortical potentials (MRCP), and sensory motor rhythms (SMR). We show that EEGNet generalizes across paradigms better than the reference algorithms when only limited training data is available. We demonstrate three different approaches to visualize the contents of a trained EEGNet model to enable interpretation of the learned features. Our results suggest that EEGNet is robust enough to learn a wide variety of interpretable features over a range of BCI tasks, suggesting that the observed performances were not due to artifact or noise sources in the data.