 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze-Informed Multi-Objective Imitation Learning from Human Demonstrations
Feb 25, 2021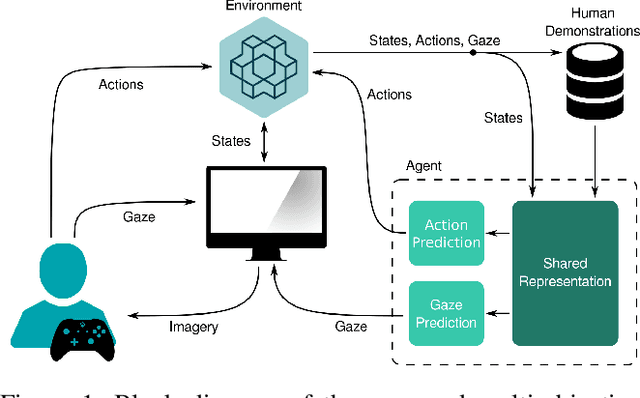
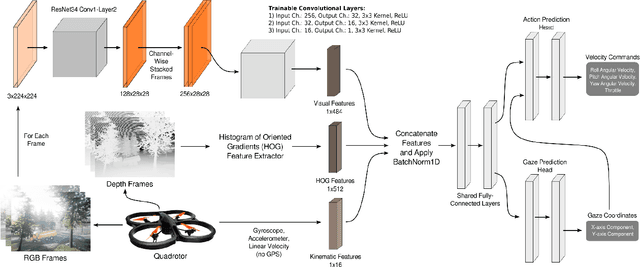

In the field of human-robot interaction, teaching learning agents from human demonstrations via supervised learning has been widely studied and successfully applied to multiple domains such as self-driving cars and robot manipulation. However, the majority of the work on learning from human demonstrations utilizes only behavioral information from the demonstrator, i.e. what actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating their visual attention, and leveraging such information has the potential to improve agent performance. Previous approaches have only studied the utilization of attention in simple, synchronous environments, limiting their applicability to real-world domains. This work proposes a novel imitation learning architecture to learn concurrently from human action demonstration and eye tracking data to solve tasks where human gaze information provides important context. The proposed method is applied to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a real-world, photorealistic simulated environment. When compared to a baseline imitation learning architecture, results show that the proposed gaze augmented imitation learning model is able to learn policies that achieve significantly higher task completion rates, with more efficient paths, while simultaneously learning to predict human visual attention. This research aims to highlight the importance of multimodal learning of visual attention information from additional human input modalities and encourages the community to adopt them when training agents from human demonstrations to perform visuomotor tasks.
PODNet: A Neural Network for Discovery of Plannable Options
Nov 15, 2019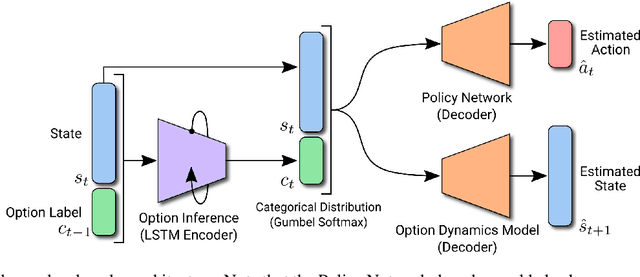
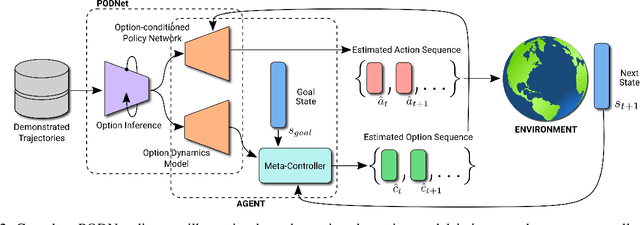
Learning from demonstration has been widely studied in machine learning but becomes challenging when the demonstrated trajectories are unstructured and follow different objectives. This short-paper proposes PODNet, Plannable Option Discovery Network, addressing how to segment an unstructured set of demonstrated trajectories for option discovery. This enables learning from demonstration to perform multiple tasks and plan high-level trajectories based on the discovered option labels. PODNet combines a custom categorical variational autoencoder, a recurrent option inference network, option-conditioned policy network, and option dynamics model in an end-to-end learning architecture. Due to the concurrently trained option-conditioned policy network and option dynamics model, the proposed architecture has implications in multi-task and hierarchical learning, explainable and interpretable artificial intelligence, and applications where the agent is required to learn only from observations.