 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowd-PrefRL: Preference-Based Reward Learning from Crowds
Jan 17, 2024
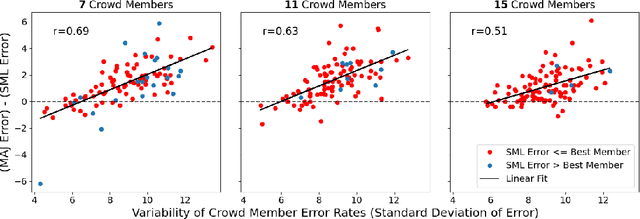
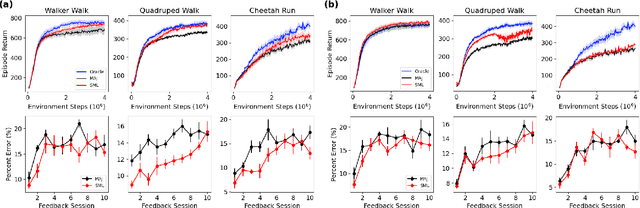
Preference-based reinforcement learning (RL) provides a framework to train agents using human feedback through pairwise preferences over pairs of behaviors, enabling agents to learn desired behaviors when it is difficult to specify a numerical reward function. While this paradigm leverages human feedback, it currently treats the feedback as given by a single human user. Meanwhile, incorporating preference feedback from crowds (i.e. ensembles of users) in a robust manner remains a challenge, and the problem of training RL agents using feedback from multiple human users remains understudied. In this work, we introduce Crowd-PrefRL, a framework for performing preference-based RL leveraging feedback from crowds. This work demonstrates the viability of learning reward functions from preference feedback provided by crowds of unknown expertise and reliability. Crowd-PrefRL not only robustly aggregates the crowd preference feedback, but also estimates the reliability of each user within the crowd using only the (noisy) crowdsourced preference comparisons. Most importantly, we show that agents trained with Crowd-PrefRL outperform agents trained with majority-vote preferences or preferences from any individual user in most cases, especially when the spread of user error rates among the crowd is large. Results further suggest that our method can identify minority viewpoints within the crowd.