 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoverNav: Cover Following Navigation Planning in Unstructured Outdoor Environment with Deep Reinforcement Learning
Aug 12, 2023Autonomous navigation in offroad environments has been extensively studied in the robotics field. However, navigation in covert situations where an autonomous vehicle needs to remain hidden from outside observers remains an underexplored area. In this paper, we propose a novel Deep Reinforcement Learning (DRL) based algorithm, called CoverNav, for identifying covert and navigable trajectories with minimal cost in offroad terrains and jungle environments in the presence of observers. CoverNav focuses on unmanned ground vehicles seeking shelters and taking covers while safely navigating to a predefined destination. Our proposed DRL method computes a local cost map that helps distinguish which path will grant the maximal covertness while maintaining a low cost trajectory using an elevation map generated from 3D point cloud data, the robot's pose, and directed goal information. CoverNav helps robot agents to learn the low elevation terrain using a reward function while penalizing it proportionately when it experiences high elevation. If an observer is spotted, CoverNav enables the robot to select natural obstacles (e.g., rocks, houses, disabled vehicles, trees, etc.) and use them as shelters to hide behind. We evaluate CoverNav using the Unity simulation environment and show that it guarantees dynamically feasible velocities in the terrain when fed with an elevation map generated by another DRL based navigation algorithm. Additionally, we evaluate CoverNav's effectiveness in achieving a maximum goal distance of 12 meters and its success rate in different elevation scenarios with and without cover objects. We observe competitive performance comparable to state of the art (SOTA) methods without compromising accuracy.
Emergent Behaviors in Multi-Agent Target Acquisition
Dec 15, 2022Only limited studies and superficial evaluations are available on agents' behaviors and roles within a Multi-Agent System (MAS). We simulate a MAS using Reinforcement Learning (RL) in a pursuit-evasion (a.k.a predator-prey pursuit) game, which shares task goals with target acquisition, and we create different adversarial scenarios by replacing RL-trained pursuers' policies with two distinct (non-RL) analytical strategies. Using heatmaps of agents' positions (state-space variable) over time, we are able to categorize an RL-trained evader's behaviors. The novelty of our approach entails the creation of an influential feature set that reveals underlying data regularities, which allow us to classify an agent's behavior. This classification may aid in catching the (enemy) targets by enabling us to identify and predict their behaviors, and when extended to pursuers, this approach towards identifying teammates' behavior may allow agents to coordinate more effectively.
* This article appeared in the news at: https://www.army.mil/article/258408/u_s_army_scientists_invent_a_method_to_characterize_ai_behavior
Learning to Guide Multiple Heterogeneous Actors from a Single Human Demonstration via Automatic Curriculum Learning in StarCraft II
May 11, 2022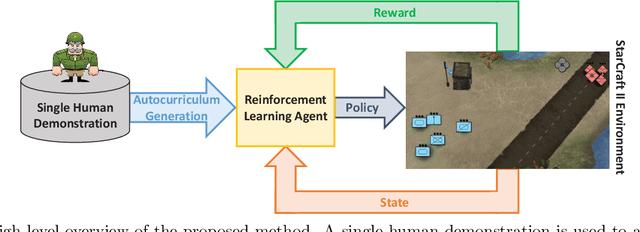


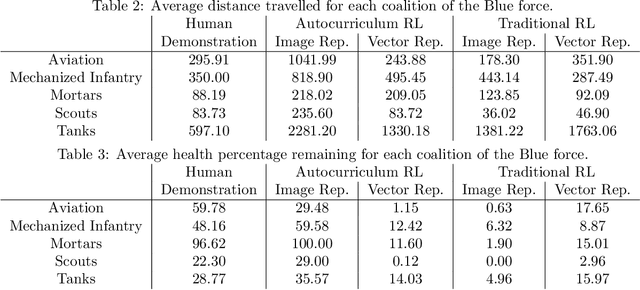
Traditionally, learning from human demonstrations via direct behavior cloning can lead to high-performance policies given that the algorithm has access to large amounts of high-quality data covering the most likely scenarios to be encountered when the agent is operating. However, in real-world scenarios, expert data is limited and it is desired to train an agent that learns a behavior policy general enough to handle situations that were not demonstrated by the human expert. Another alternative is to learn these policies with no supervision via deep reinforcement learning, however, these algorithms require a large amount of computing time to perform well on complex tasks with high-dimensional state and action spaces, such as those found in StarCraft II. Automatic curriculum learning is a recent mechanism comprised of techniques designed to speed up deep reinforcement learning by adjusting the difficulty of the current task to be solved according to the agent's current capabilities. Designing a proper curriculum, however, can be challenging for sufficiently complex tasks, and thus we leverage human demonstrations as a way to guide agent exploration during training. In this work, we aim to train deep reinforcement learning agents that can command multiple heterogeneous actors where starting positions and overall difficulty of the task are controlled by an automatically-generated curriculum from a single human demonstration. Our results show that an agent trained via automated curriculum learning can outperform state-of-the-art deep reinforcement learning baselines and match the performance of the human expert in a simulated command and control task in StarCraft II modeled over a real military scenario.
Strategic Maneuver and Disruption with Reinforcement Learning Approaches for Multi-Agent Coordination
Mar 17, 2022
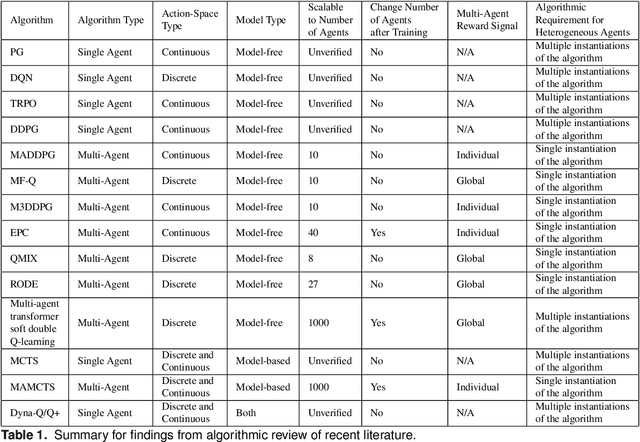
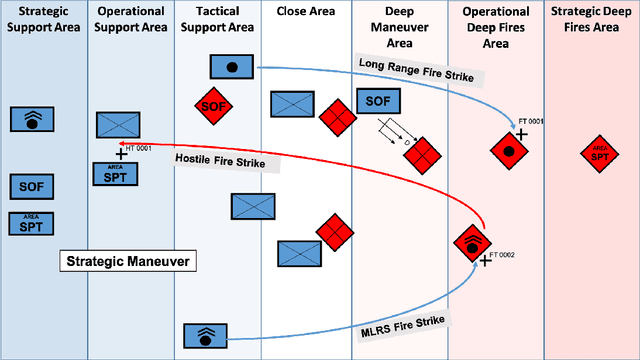
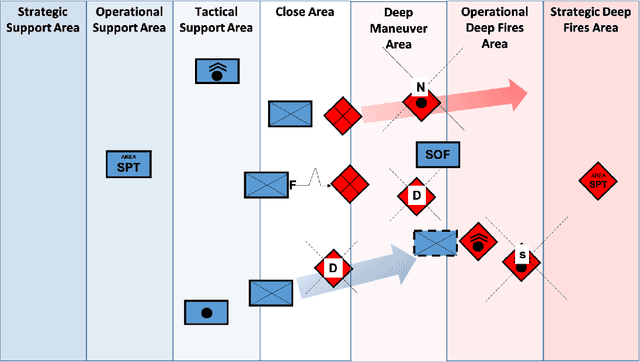
Reinforcement learning (RL) approaches can illuminate emergent behaviors that facilitate coordination across teams of agents as part of a multi-agent system (MAS), which can provide windows of opportunity in various military tasks. Technologically advancing adversaries pose substantial risks to a friendly nation's interests and resources. Superior resources alone are not enough to defeat adversaries in modern complex environments because adversaries create standoff in multiple domains against predictable military doctrine-based maneuvers. Therefore, as part of a defense strategy, friendly forces must use strategic maneuvers and disruption to gain superiority in complex multi-faceted domains such as multi-domain operations (MDO). One promising avenue for implementing strategic maneuver and disruption to gain superiority over adversaries is through coordination of MAS in future military operations. In this paper, we present overviews of prominent works in the RL domain with their strengths and weaknesses for overcoming the challenges associated with performing autonomous strategic maneuver and disruption in military contexts.
On games and simulators as a platform for development of artificial intelligence for command and control
Oct 21, 2021

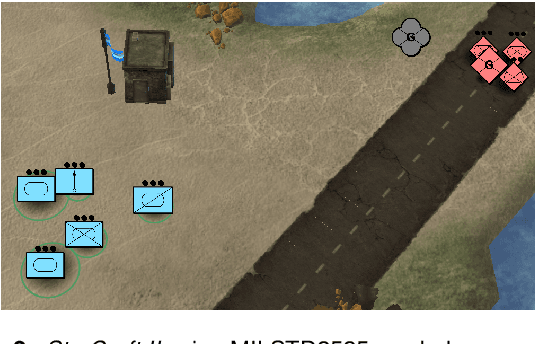
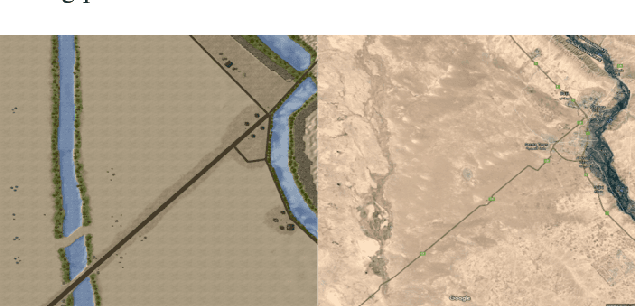
Games and simulators can be a valuable platform to execute complex multi-agent, multiplayer, imperfect information scenarios with significant parallels to military applications: multiple participants manage resources and make decisions that command assets to secure specific areas of a map or neutralize opposing forces. These characteristics have attracted the artificial intelligence (AI) community by supporting development of algorithms with complex benchmarks and the capability to rapidly iterate over new ideas. The success of artificial intelligence algorithms in real-time strategy games such as StarCraft II have also attracted the attention of the military research community aiming to explore similar techniques in military counterpart scenarios. Aiming to bridge the connection between games and military applications, this work discusses past and current efforts on how games and simulators, together with the artificial intelligence algorithms, have been adapted to simulate certain aspects of military missions and how they might impact the future battlefield. This paper also investigates how advances in virtual reality and visual augmentation systems open new possibilities in human interfaces with gaming platforms and their military parallels.
Survey of Recent Multi-Agent Reinforcement Learning Algorithms Utilizing Centralized Training
Jul 29, 2021Much work has been dedicated to the exploration of Multi-Agent Reinforcement Learning (MARL) paradigms implementing a centralized learning with decentralized execution (CLDE) approach to achieve human-like collaboration in cooperative tasks. Here, we discuss variations of centralized training and describe a recent survey of algorithmic approaches. The goal is to explore how different implementations of information sharing mechanism in centralized learning may give rise to distinct group coordinated behaviors in multi-agent systems performing cooperative tasks.
* This article appeared in the news at: https://www.army.mil/article/247261/army_researchers_develop_innovative_framework_for_training_ai
On Memory Mechanism in Multi-Agent Reinforcement Learning
Sep 11, 2019

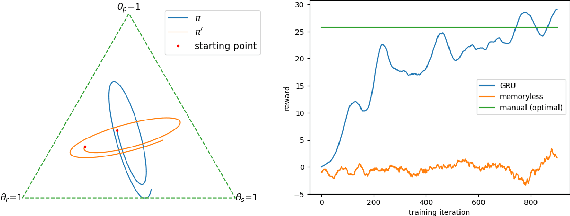

Multi-agent reinforcement learning (MARL) extends (single-agent) reinforcement learning (RL) by introducing additional agents and (potentially) partial observability of the environment. Consequently, algorithms for solving MARL problems incorporate various extensions beyond traditional RL methods, such as a learned communication protocol between cooperative agents that enables exchange of private information or adaptive modeling of opponents in competitive settings. One popular algorithmic construct is a memory mechanism such that an agent's decisions can depend not only upon the current state but also upon the history of observed states and actions. In this paper, we study how a memory mechanism can be useful in environments with different properties, such as observability, internality and presence of a communication channel. Using both prior work and new experiments, we show that a memory mechanism is helpful when learning agents need to model other agents and/or when communication is constrained in some way; however we must to be cautious of agents achieving effective memoryfulness through other means.
Coordination-driven learning in multi-agent problem spaces
Sep 13, 2018We discuss the role of coordination as a direct learning objective in multi-agent reinforcement learning (MARL) domains. To this end, we present a novel means of quantifying coordination in multi-agent systems, and discuss the implications of using such a measure to optimize coordinated agent policies. This concept has important implications for adversary-aware RL, which we take to be a sub-domain of multi-agent learning.