 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Memory Mechanism in Multi-Agent Reinforcement Learning
Paper and Code
Sep 11, 2019

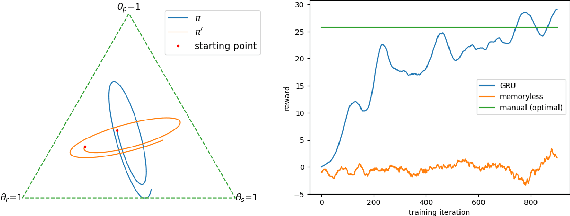

Multi-agent reinforcement learning (MARL) extends (single-agent) reinforcement learning (RL) by introducing additional agents and (potentially) partial observability of the environment. Consequently, algorithms for solving MARL problems incorporate various extensions beyond traditional RL methods, such as a learned communication protocol between cooperative agents that enables exchange of private information or adaptive modeling of opponents in competitive settings. One popular algorithmic construct is a memory mechanism such that an agent's decisions can depend not only upon the current state but also upon the history of observed states and actions. In this paper, we study how a memory mechanism can be useful in environments with different properties, such as observability, internality and presence of a communication channel. Using both prior work and new experiments, we show that a memory mechanism is helpful when learning agents need to model other agents and/or when communication is constrained in some way; however we must to be cautious of agents achieving effective memoryfulness through other means.