 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Guarantees for Distributionally Robust Optimization with Optimal Transport and OT-Regularized Divergences
Mar 29, 2026We study finite-sample statistical performance guarantees for distributionally robust optimization (DRO) with optimal transport (OT) and OT-regularized divergence model neighborhoods. Specifically, we derive concentration inequalities for supervised learning via DRO-based adversarial training, as commonly employed to enhance the adversarial robustness of machine learning models. Our results apply to a wide range of OT cost functions, beyond the $p$-Wasserstein case studied by previous authors. In particular, our results are the first to: 1) cover soft-constraint norm-ball OT cost functions; soft-constraint costs have been shown empirically to enhance robustness when used in adversarial training, 2) apply to the combination of adversarial sample generation and adversarial reweighting that is induced by using OT-regularized $f$-divergence model neighborhoods; the added reweighting mechanism has also been shown empirically to further improve performance. In addition, even in the $p$-Wasserstein case, our bounds exhibit better behavior as a function of the DRO neighborhood size than previous results when applied to the adversarial setting.
Concentration Inequalities for the Stochastic Optimization of Unbounded Objectives with Application to Denoising Score Matching
Feb 12, 2025We derive novel concentration inequalities that bound the statistical error for a large class of stochastic optimization problems, focusing on the case of unbounded objective functions. Our derivations utilize the following tools: 1) A new form of McDiarmid's inequality that is based on sample dependent one component difference bounds and which leads to a novel uniform law of large numbers result for unbounded functions. 2) A Rademacher complexity bound for families of functions that satisfy an appropriate local Lipschitz property. As an application of these results, we derive statistical error bounds for denoising score matching (DSM), an application that inherently requires one to consider unbounded objective functions, even when the data distribution has bounded support. In addition, our results establish the benefit of sample reuse in algorithms that employ easily sampled auxiliary random variables in addition to the training data, e.g., as in DSM, which uses auxiliary Gaussian random variables.
An Interactive Framework for Implementing Privacy-Preserving Federated Learning: Experiments on Large Language Models
Feb 11, 2025
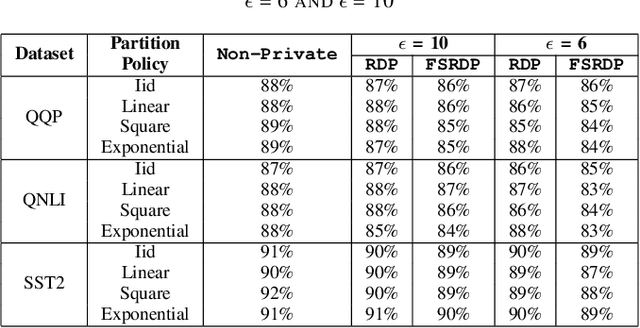


Federated learning (FL) enhances privacy by keeping user data on local devices. However, emerging attacks have demonstrated that the updates shared by users during training can reveal significant information about their data. This has greatly thwart the adoption of FL methods for training robust AI models in sensitive applications. Differential Privacy (DP) is considered the gold standard for safeguarding user data. However, DP guarantees are highly conservative, providing worst-case privacy guarantees. This can result in overestimating privacy needs, which may compromise the model's accuracy. Additionally, interpretations of these privacy guarantees have proven to be challenging in different contexts. This is further exacerbated when other factors, such as the number of training iterations, data distribution, and specific application requirements, can add further complexity to this problem. In this work, we proposed a framework that integrates a human entity as a privacy practitioner to determine an optimal trade-off between the model's privacy and utility. Our framework is the first to address the variable memory requirement of existing DP methods in FL settings, where resource-limited devices (e.g., cell phones) can participate. To support such settings, we adopt a recent DP method with fixed memory usage to ensure scalable private FL. We evaluated our proposed framework by fine-tuning a BERT-based LLM model using the GLUE dataset (a common approach in literature), leveraging the new accountant, and employing diverse data partitioning strategies to mimic real-world conditions. As a result, we achieved stable memory usage, with an average accuracy reduction of 1.33% for $\epsilon = 10$ and 1.9% for $\epsilon = 6$, when compared to the state-of-the-art DP accountant which does not support fixed memory usage.
Concentration Inequalities for $(f,Γ)$-GANs
Jun 24, 2024Generative adversarial networks (GANs) are unsupervised learning methods for training a generator distribution to produce samples that approximate those drawn from a target distribution. Many such methods can be formulated as minimization of a metric or divergence. Recent works have proven the statistical consistency of GANs that are based on integral probability metrics (IPMs), e.g., WGAN which is based on the 1-Wasserstein metric. IPMs are defined by optimizing a linear functional (difference of expectations) over a space of discriminators. A much larger class of GANs, which allow for the use of nonlinear objective functionals, can be constructed using $(f,\Gamma)$-divergences; these generalize and interpolate between IPMs and $f$-divergences (e.g., KL or $\alpha$-divergences). Instances of $(f,\Gamma)$-GANs have been shown to exhibit improved performance in a number of applications. In this work we study the statistical consistency of $(f,\Gamma)$-GANs for general $f$ and $\Gamma$. Specifically, we derive finite-sample concentration inequalities. These derivations require novel arguments due to nonlinearity of the objective functional. We demonstrate that our new results reduce to the known results for IPM-GANs in the appropriate limit while also significantly extending the domain of applicability of this theory.
Nonlinear denoising score matching for enhanced learning of structured distributions
May 24, 2024
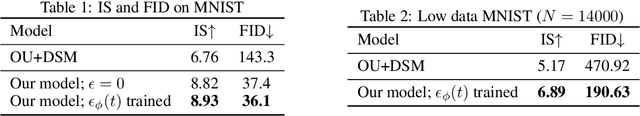
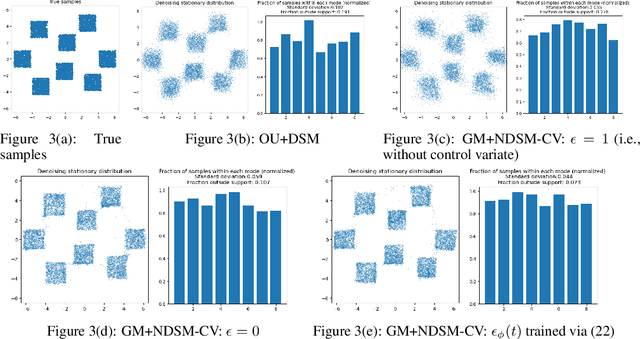
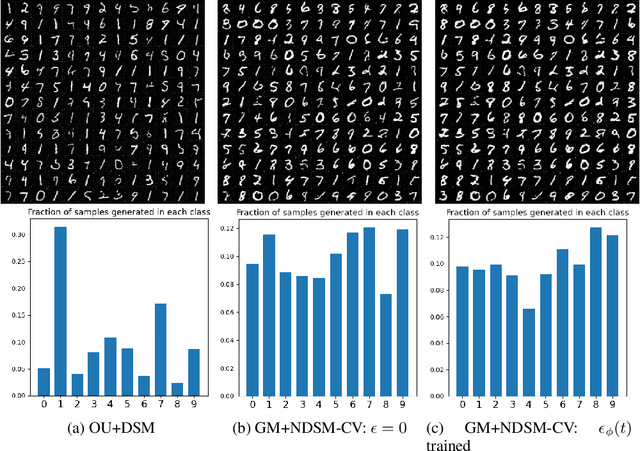
We present a novel method for training score-based generative models which uses nonlinear noising dynamics to improve learning of structured distributions. Generalizing to a nonlinear drift allows for additional structure to be incorporated into the dynamics, thus making the training better adapted to the data, e.g., in the case of multimodality or (approximate) symmetries. Such structure can be obtained from the data by an inexpensive preprocessing step. The nonlinear dynamics introduces new challenges into training which we address in two ways: 1) we develop a new nonlinear denoising score matching (NDSM) method, 2) we introduce neural control variates in order to reduce the variance of the NDSM training objective. We demonstrate the effectiveness of this method on several examples: a) a collection of low-dimensional examples, motivated by clustering in latent space, b) high-dimensional images, addressing issues with mode collapse, small training sets, and approximate symmetries, the latter being a challenge for methods based on equivariant neural networks, which require exact symmetries.
Adversarially Robust Deep Learning with Optimal-Transport-Regularized Divergences
Sep 07, 2023We introduce the $ARMOR_D$ methods as novel approaches to enhancing the adversarial robustness of deep learning models. These methods are based on a new class of optimal-transport-regularized divergences, constructed via an infimal convolution between an information divergence and an optimal-transport (OT) cost. We use these as tools to enhance adversarial robustness by maximizing the expected loss over a neighborhood of distributions, a technique known as distributionally robust optimization. Viewed as a tool for constructing adversarial samples, our method allows samples to be both transported, according to the OT cost, and re-weighted, according to the information divergence. We demonstrate the effectiveness of our method on malware detection and image recognition applications and find that, to our knowledge, it outperforms existing methods at enhancing the robustness against adversarial attacks. $ARMOR_D$ yields the robustified accuracy of $98.29\%$ against $FGSM$ and $98.18\%$ against $PGD^{40}$ on the MNIST dataset, reducing the error rate by more than $19.7\%$ and $37.2\%$ respectively compared to prior methods. Similarly, in malware detection, a discrete (binary) data domain, $ARMOR_D$ improves the robustified accuracy under $rFGSM^{50}$ attack compared to the previous best-performing adversarial training methods by $37.0\%$ while lowering false negative and false positive rates by $51.1\%$ and $57.53\%$, respectively.
Function-space regularized Rényi divergences
Oct 10, 2022We propose a new family of regularized R\'enyi divergences parametrized not only by the order $\alpha$ but also by a variational function space. These new objects are defined by taking the infimal convolution of the standard R\'enyi divergence with the integral probability metric (IPM) associated with the chosen function space. We derive a novel dual variational representation that can be used to construct numerically tractable divergence estimators. This representation avoids risk-sensitive terms and therefore exhibits lower variance, making it well-behaved when $\alpha>1$; this addresses a notable weakness of prior approaches. We prove several properties of these new divergences, showing that they interpolate between the classical R\'enyi divergences and IPMs. We also study the $\alpha\to\infty$ limit, which leads to a regularized worst-case-regret and a new variational representation in the classical case. Moreover, we show that the proposed regularized R\'enyi divergences inherit features from IPMs such as the ability to compare distributions that are not absolutely continuous, e.g., empirical measures and distributions with low-dimensional support. We present numerical results on both synthetic and real datasets, showing the utility of these new divergences in both estimation and GAN training applications; in particular, we demonstrate significantly reduced variance and improved training performance.
Structure-preserving GANs
Feb 02, 2022
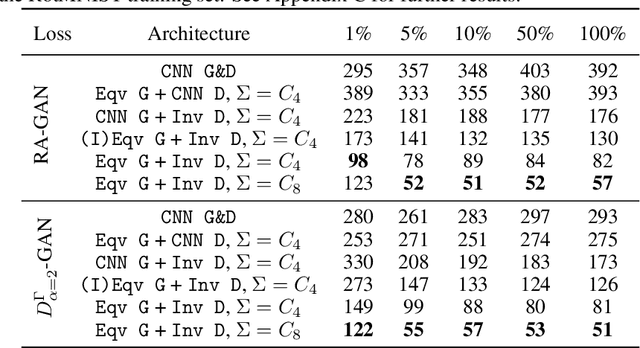

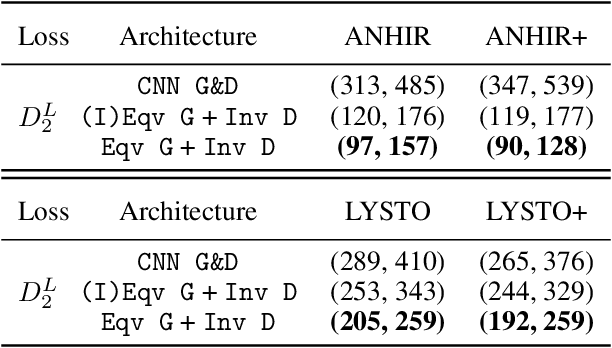
Generative adversarial networks (GANs), a class of distribution-learning methods based on a two-player game between a generator and a discriminator, can generally be formulated as a minmax problem based on the variational representation of a divergence between the unknown and the generated distributions. We introduce structure-preserving GANs as a data-efficient framework for learning distributions with additional structure such as group symmetry, by developing new variational representations for divergences. Our theory shows that we can reduce the discriminator space to its projection on the invariant discriminator space, using the conditional expectation with respect to the $\sigma$-algebra associated to the underlying structure. In addition, we prove that the discriminator space reduction must be accompanied by a careful design of structured generators, as flawed designs may easily lead to a catastrophic "mode collapse" of the learned distribution. We contextualize our framework by building symmetry-preserving GANs for distributions with intrinsic group symmetry, and demonstrate that both players, namely the equivariant generator and invariant discriminator, play important but distinct roles in the learning process. Empirical experiments and ablation studies across a broad range of data sets, including real-world medical imaging, validate our theory, and show our proposed methods achieve significantly improved sample fidelity and diversity -- almost an order of magnitude measured in Fr\'echet Inception Distance -- especially in the small data regime.
$(f,Γ)$-Divergences: Interpolating between $f$-Divergences and Integral Probability Metrics
Nov 11, 2020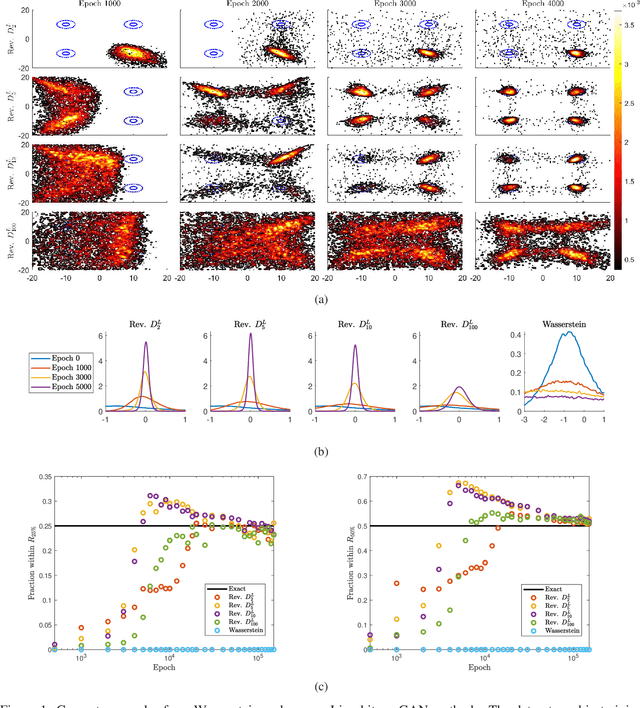
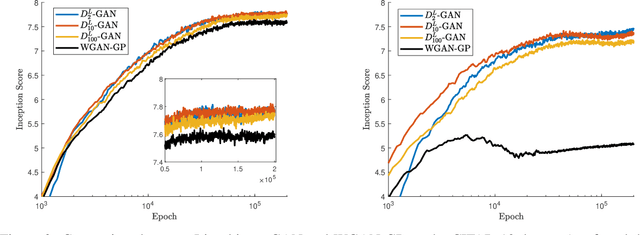
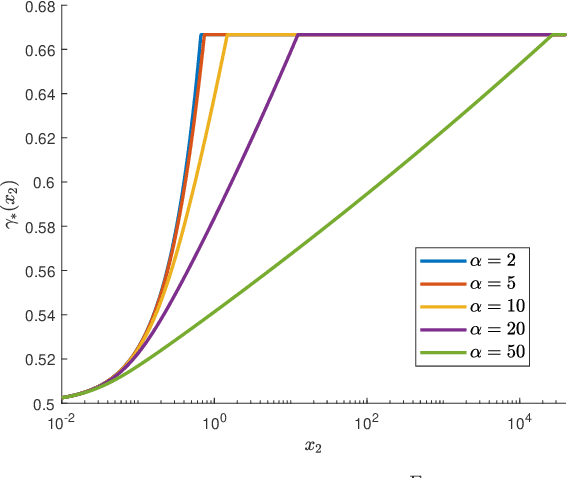
We develop a general framework for constructing new information-theoretic divergences that rigorously interpolate between $f$-divergences and integral probability metrics (IPMs), such as the Wasserstein distance. These new divergences inherit features from IPMs, such as the ability to compare distributions which are not absolute continuous, as well as from $f$-divergences, for instance the strict concavity of their variational representations and the ability to compare heavy-tailed distributions. When combined, these features establish a divergence with improved convergence and estimation properties for statistical learning applications. We demonstrate their use in the training of generative adversarial networks (GAN) for heavy-tailed data and also show they can provide improved performance over gradient-penalized Wasserstein GAN in image generation.
A Variational Formula for Rényi Divergences
Jul 07, 2020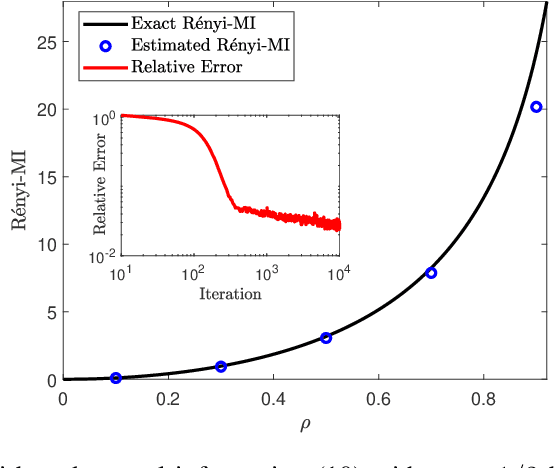

We derive a new variational formula for the R\'enyi family of divergences, $R_\alpha(Q\|P)$, generalizing the classical Donsker-Varadhan variational formula for the Kullback-Leibler divergence. The objective functional in this new variational representation is expressed in terms of expectations under $Q$ and $P$, and hence can be estimated using samples from the two distributions. We illustrate the utility of such a variational formula by constructing neural-network estimators for the R\'enyi divergences.