 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKD-Judge: A Knowledge-Driven Automated Judge Framework for Functional Fitness Movements on Edge Devices
Apr 21, 2026Functional fitness movements are widely used in training, competition, and health-oriented exercise programs, yet consistently enforcing repetition (rep) standards remains challenging due to subjective human judgment, time constraints, and evolving rules. Existing AI-based approaches mainly rely on learned scoring or reference-based comparisons and lack explicit rule-based, limiting transparency and deterministic rep-level validation. To address these limitations, we propose KD-Judge, a novel knowledge-driven automated judging framework for functional fitness movements. It converts unstructured rulebook standards into executable, machine-readable representations using an LLM-based retrieval-augmented generation and chain-of-thought rule-structuring pipeline. The structured rules are then incorporated by a deterministic rule-based judging system with pose-guided kinematic reasoning to assess rep validity and temporal boundaries. To improve efficiency on edge devices, including a high-performance desktop and the resource-constrained Jetson AGX Xavier, we introduce a dual strategy caching mechanism that can be selectively applied to reduce redundant and unnecessary computation. Experiments demonstrate reliable rule-structuring performance and accurate rep-level assessment, with judgment evaluation conducted on the CFRep dataset, achieving faster-than-real-time execution (real-time factor (RTF) < 1). When the proposed caching strategy is enabled, the system achieves up to 3.36x and 15.91x speedups on resource-constrained edge device compared to the non-caching baseline for pre-recorded and live-streaming scenarios, respectively. These results show that KD-Judge enables transparent, efficient, and scalable rule-grounded rep-level analysis that can complement human judging in practice.
MTMed3D: A Multi-Task Transformer-Based Model for 3D Medical Imaging
Nov 15, 2025In the field of medical imaging, AI-assisted techniques such as object detection, segmentation, and classification are widely employed to alleviate the workload of physicians and doctors. However, single-task models are predominantly used, overlooking the shared information across tasks. This oversight leads to inefficiencies in real-life applications. In this work, we propose MTMed3D, a novel end-to-end Multi-task Transformer-based model to address the limitations of single-task models by jointly performing 3D detection, segmentation, and classification in medical imaging. Our model uses a Transformer as the shared encoder to generate multi-scale features, followed by CNN-based task-specific decoders. The proposed framework was evaluated on the BraTS 2018 and 2019 datasets, achieving promising results across all three tasks, especially in detection, where our method achieves better results than prior works. Additionally, we compare our multi-task model with equivalent single-task variants trained separately. Our multi-task model significantly reduces computational costs and achieves faster inference speed while maintaining comparable performance to the single-task models, highlighting its efficiency advantage. To the best of our knowledge, this is the first work to leverage Transformers for multi-task learning that simultaneously covers detection, segmentation, and classification tasks in 3D medical imaging, presenting its potential to enhance diagnostic processes. The code is available at https://github.com/fanlimua/MTMed3D.git.
Boosting Imperceptibility of Stable Diffusion-based Adversarial Examples Generation with Momentum
Oct 17, 2024



We propose a novel framework, Stable Diffusion-based Momentum Integrated Adversarial Examples (SD-MIAE), for generating adversarial examples that can effectively mislead neural network classifiers while maintaining visual imperceptibility and preserving the semantic similarity to the original class label. Our method leverages the text-to-image generation capabilities of the Stable Diffusion model by manipulating token embeddings corresponding to the specified class in its latent space. These token embeddings guide the generation of adversarial images that maintain high visual fidelity. The SD-MIAE framework consists of two phases: (1) an initial adversarial optimization phase that modifies token embeddings to produce misclassified yet natural-looking images and (2) a momentum-based optimization phase that refines the adversarial perturbations. By introducing momentum, our approach stabilizes the optimization of perturbations across iterations, enhancing both the misclassification rate and visual fidelity of the generated adversarial examples. Experimental results demonstrate that SD-MIAE achieves a high misclassification rate of 79%, improving by 35% over the state-of-the-art method while preserving the imperceptibility of adversarial perturbations and the semantic similarity to the original class label, making it a practical method for robust adversarial evaluation.
Using Retriever Augmented Large Language Models for Attack Graph Generation
Aug 11, 2024
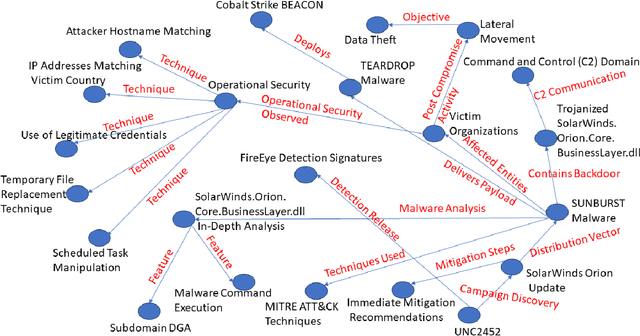
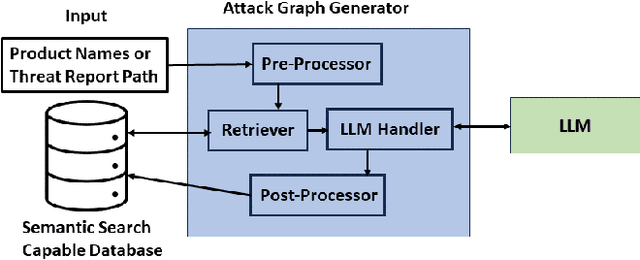

As the complexity of modern systems increases, so does the importance of assessing their security posture through effective vulnerability management and threat modeling techniques. One powerful tool in the arsenal of cybersecurity professionals is the attack graph, a representation of all potential attack paths within a system that an adversary might exploit to achieve a certain objective. Traditional methods of generating attack graphs involve expert knowledge, manual curation, and computational algorithms that might not cover the entire threat landscape due to the ever-evolving nature of vulnerabilities and exploits. This paper explores the approach of leveraging large language models (LLMs), such as ChatGPT, to automate the generation of attack graphs by intelligently chaining Common Vulnerabilities and Exposures (CVEs) based on their preconditions and effects. It also shows how to utilize LLMs to create attack graphs from threat reports.
Transfer Learning for Security: Challenges and Future Directions
Mar 01, 2024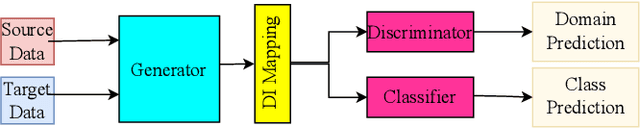

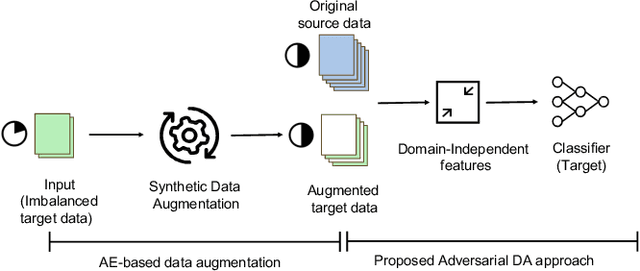
Many machine learning and data mining algorithms rely on the assumption that the training and testing data share the same feature space and distribution. However, this assumption may not always hold. For instance, there are situations where we need to classify data in one domain, but we only have sufficient training data available from a different domain. The latter data may follow a distinct distribution. In such cases, successfully transferring knowledge across domains can significantly improve learning performance and reduce the need for extensive data labeling efforts. Transfer learning (TL) has thus emerged as a promising framework to tackle this challenge, particularly in security-related tasks. This paper aims to review the current advancements in utilizing TL techniques for security. The paper includes a discussion of the existing research gaps in applying TL in the security domain, as well as exploring potential future research directions and issues that arise in the context of TL-assisted security solutions.
Gradient-Leakage Resilient Federated Learning
Jul 02, 2021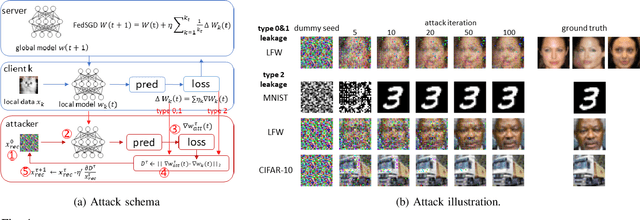
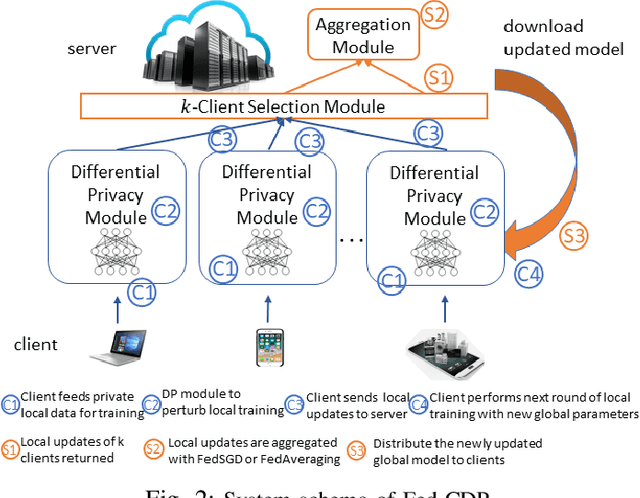
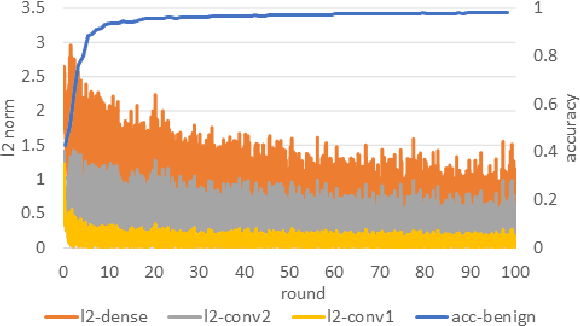
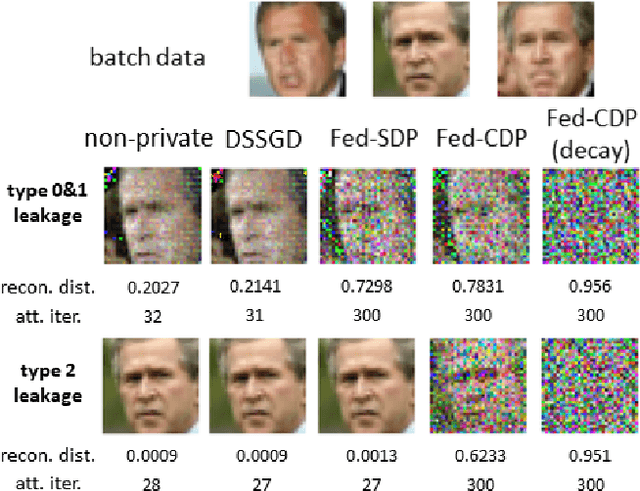
Federated learning(FL) is an emerging distributed learning paradigm with default client privacy because clients can keep sensitive data on their devices and only share local training parameter updates with the federated server. However, recent studies reveal that gradient leakages in FL may compromise the privacy of client training data. This paper presents a gradient leakage resilient approach to privacy-preserving federated learning with per training example-based client differential privacy, coined as Fed-CDP. It makes three original contributions. First, we identify three types of client gradient leakage threats in federated learning even with encrypted client-server communications. We articulate when and why the conventional server coordinated differential privacy approach, coined as Fed-SDP, is insufficient to protect the privacy of the training data. Second, we introduce Fed-CDP, the per example-based client differential privacy algorithm, and provide a formal analysis of Fed-CDP with the $(\epsilon, \delta)$ differential privacy guarantee, and a formal comparison between Fed-CDP and Fed-SDP in terms of privacy accounting. Third, we formally analyze the privacy-utility trade-off for providing differential privacy guarantee by Fed-CDP and present a dynamic decay noise-injection policy to further improve the accuracy and resiliency of Fed-CDP. We evaluate and compare Fed-CDP and Fed-CDP(decay) with Fed-SDP in terms of differential privacy guarantee and gradient leakage resilience over five benchmark datasets. The results show that the Fed-CDP approach outperforms conventional Fed-SDP in terms of resilience to client gradient leakages while offering competitive accuracy performance in federated learning.
Patient-Specific Seizure Prediction Using Single Seizure Electroencephalography Recording
Nov 14, 2020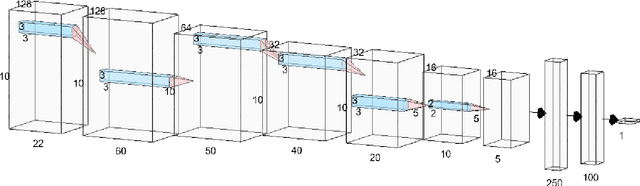
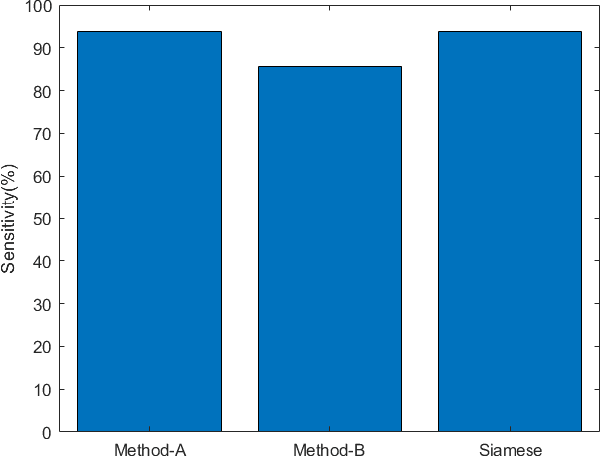
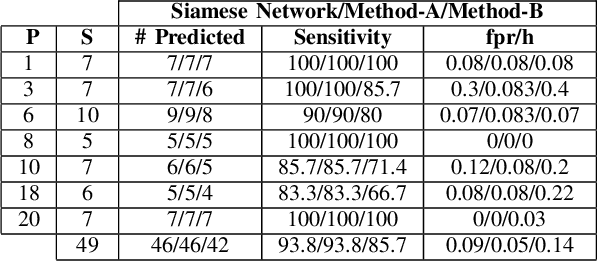
Electroencephalogram (EEG) is a prominent way to measure the brain activity for studying epilepsy, thereby helping in predicting seizures. Seizure prediction is an active research area with many deep learning based approaches dominating the recent literature for solving this problem. But these models require a considerable number of patient-specific seizures to be recorded for extracting the preictal and interictal EEG data for training a classifier. The increase in sensitivity and specificity for seizure prediction using the machine learning models is noteworthy. However, the need for a significant number of patient-specific seizures and periodic retraining of the model because of non-stationary EEG creates difficulties for designing practical device for a patient. To mitigate this process, we propose a Siamese neural network based seizure prediction method that takes a wavelet transformed EEG tensor as an input with convolutional neural network (CNN) as the base network for detecting change-points in EEG. Compared to the solutions in the literature, which utilize days of EEG recordings, our method only needs one seizure for training which translates to less than ten minutes of preictal and interictal data while still getting comparable results to models which utilize multiple seizures for seizure prediction.
Schemaless Queries over Document Tables with Dependencies
Nov 21, 2019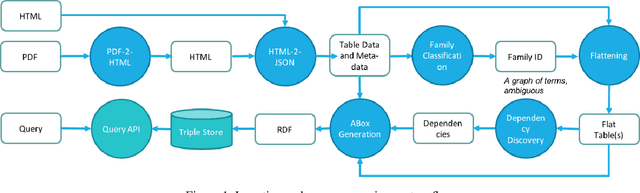
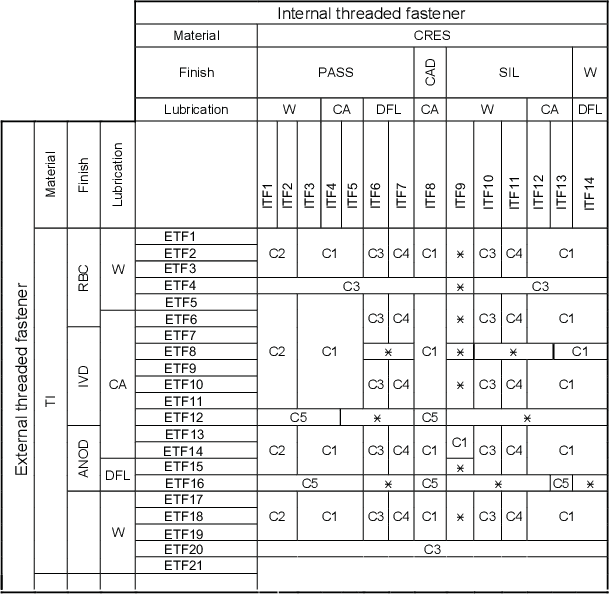
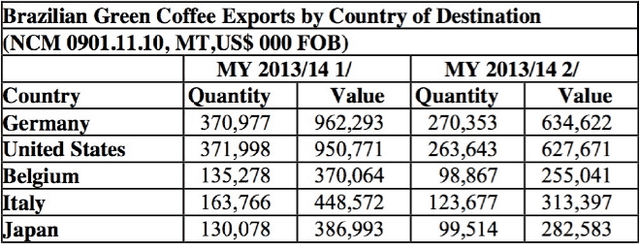
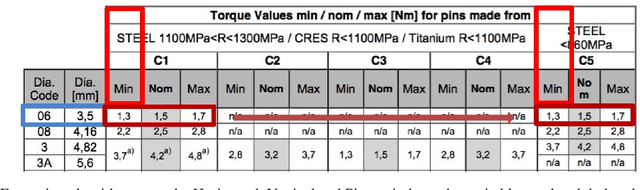
Unstructured enterprise data such as reports, manuals and guidelines often contain tables. The traditional way of integrating data from these tables is through a two-step process of table detection/extraction and mapping the table layouts to an appropriate schema. This can be an expensive process. In this paper we show that by using semantic technologies (RDF/SPARQL and database dependencies) paired with a simple but powerful way to transform tables with non-relational layouts, it is possible to offer query answering services over these tables with minimal manual work or domain-specific mappings. Our method enables users to exploit data in tables embedded in documents with little effort, not only for simple retrieval queries, but also for structured queries that require joining multiple interrelated tables.
Demystifying Learning Rate Polices for High Accuracy Training of Deep Neural Networks
Aug 18, 2019
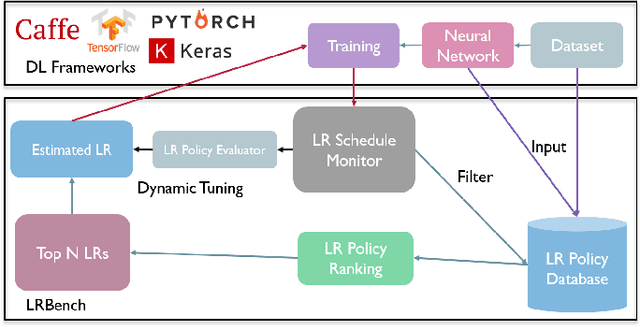
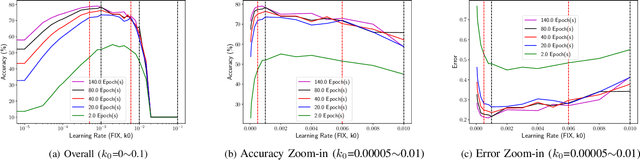
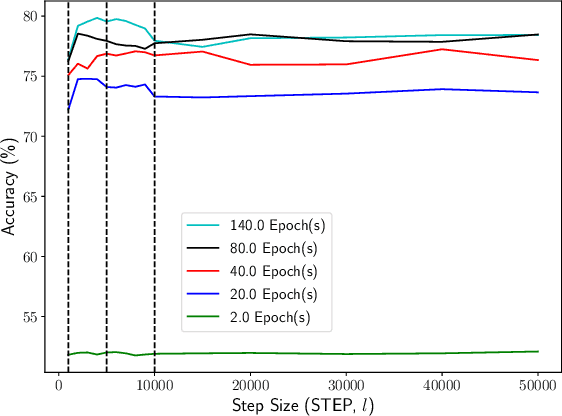
Learning Rate (LR) is an important hyper-parameter to tune for effective training of deep neural networks (DNNs). Even for the baseline of a constant learning rate, it is non-trivial to choose a good constant value for training a DNN. Dynamic learning rates involve multi-step tuning of LR values at various stages of the training process and offer high accuracy and fast convergence. However, they are much harder to tune. In this paper, we present a comprehensive study of 13 learning rate functions and their associated LR policies by examining their range parameters, step parameters, and value update parameters. We propose a set of metrics for evaluating and selecting LR policies, including the classification confidence, variance, cost, and robustness, and implement them in LRBench, an LR benchmarking system. LRBench can assist end-users and DNN developers to select good LR policies and avoid bad LR policies for training their DNNs. We tested LRBench on Caffe, an open source deep learning framework, to showcase the tuning optimization of LR policies. Evaluated through extensive experiments, we attempt to demystify the tuning of LR policies by identifying good LR policies with effective LR value ranges and step sizes for LR update schedules.