 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Leakage Resilient Federated Learning
Jul 02, 2021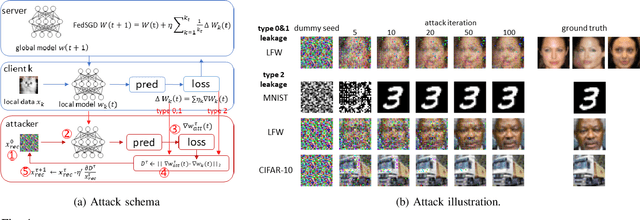
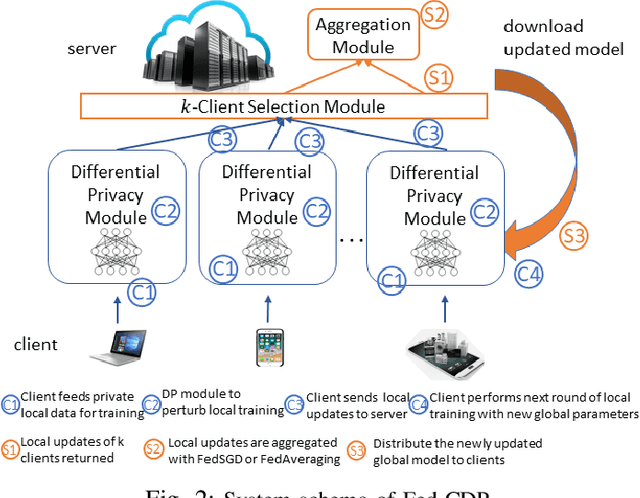
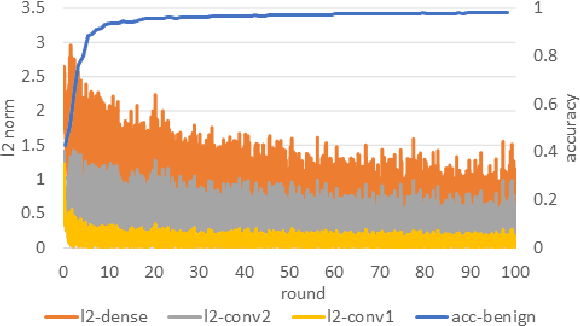
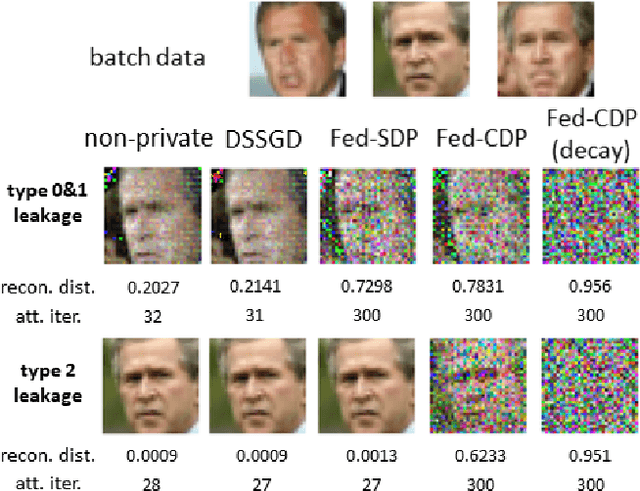
Federated learning(FL) is an emerging distributed learning paradigm with default client privacy because clients can keep sensitive data on their devices and only share local training parameter updates with the federated server. However, recent studies reveal that gradient leakages in FL may compromise the privacy of client training data. This paper presents a gradient leakage resilient approach to privacy-preserving federated learning with per training example-based client differential privacy, coined as Fed-CDP. It makes three original contributions. First, we identify three types of client gradient leakage threats in federated learning even with encrypted client-server communications. We articulate when and why the conventional server coordinated differential privacy approach, coined as Fed-SDP, is insufficient to protect the privacy of the training data. Second, we introduce Fed-CDP, the per example-based client differential privacy algorithm, and provide a formal analysis of Fed-CDP with the $(\epsilon, \delta)$ differential privacy guarantee, and a formal comparison between Fed-CDP and Fed-SDP in terms of privacy accounting. Third, we formally analyze the privacy-utility trade-off for providing differential privacy guarantee by Fed-CDP and present a dynamic decay noise-injection policy to further improve the accuracy and resiliency of Fed-CDP. We evaluate and compare Fed-CDP and Fed-CDP(decay) with Fed-SDP in terms of differential privacy guarantee and gradient leakage resilience over five benchmark datasets. The results show that the Fed-CDP approach outperforms conventional Fed-SDP in terms of resilience to client gradient leakages while offering competitive accuracy performance in federated learning.
Compiling ONNX Neural Network Models Using MLIR
Oct 01, 2020

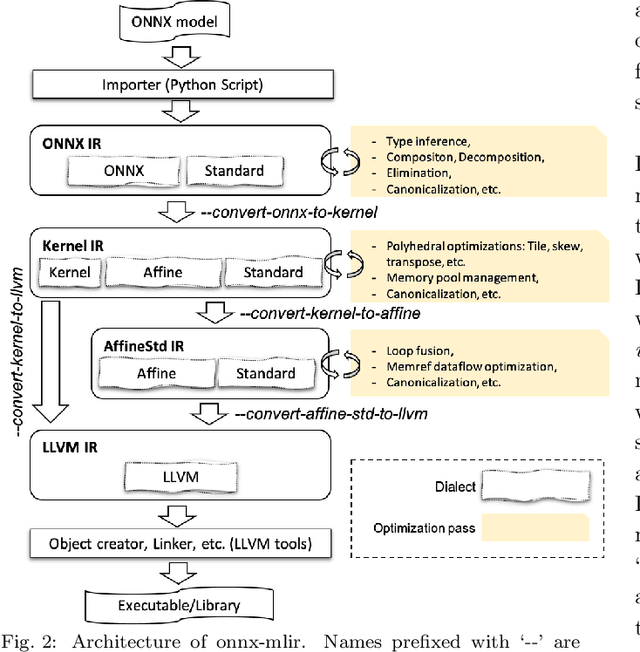
Deep neural network models are becoming increasingly popular and have been used in various tasks such as computer vision, speech recognition, and natural language processing. Machine learning models are commonly trained in a resource-rich environment and then deployed in a distinct environment such as high availability machines or edge devices. To assist the portability of models, the open-source community has proposed the Open Neural Network Exchange (ONNX) standard. In this paper, we present a high-level, preliminary report on our onnx-mlir compiler, which generates code for the inference of deep neural network models described in the ONNX format. Onnx-mlir is an open-source compiler implemented using the Multi-Level Intermediate Representation (MLIR) infrastructure recently integrated in the LLVM project. Onnx-mlir relies on the MLIR concept of dialects to implement its functionality. We propose here two new dialects: (1) an ONNX specific dialect that encodes the ONNX standard semantics, and (2) a loop-based dialect to provide for a common lowering point for all ONNX dialect operations. Each intermediate representation facilitates its own characteristic set of graph-level and loop-based optimizations respectively. We illustrate our approach by following several models through the proposed representations and we include some early optimization work and performance results.