 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompiling ONNX Neural Network Models Using MLIR
Oct 01, 2020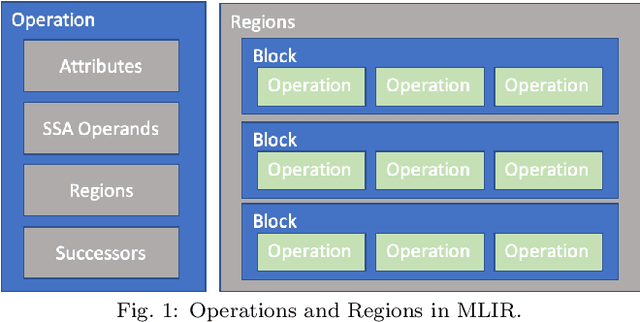

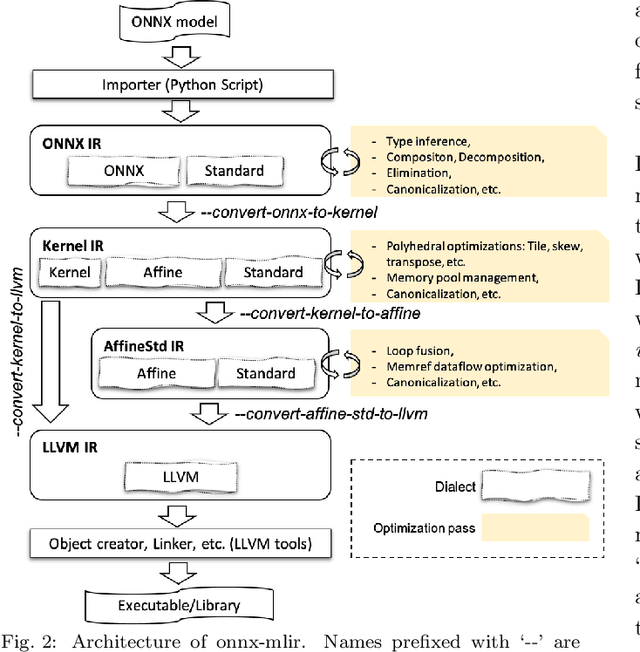
Deep neural network models are becoming increasingly popular and have been used in various tasks such as computer vision, speech recognition, and natural language processing. Machine learning models are commonly trained in a resource-rich environment and then deployed in a distinct environment such as high availability machines or edge devices. To assist the portability of models, the open-source community has proposed the Open Neural Network Exchange (ONNX) standard. In this paper, we present a high-level, preliminary report on our onnx-mlir compiler, which generates code for the inference of deep neural network models described in the ONNX format. Onnx-mlir is an open-source compiler implemented using the Multi-Level Intermediate Representation (MLIR) infrastructure recently integrated in the LLVM project. Onnx-mlir relies on the MLIR concept of dialects to implement its functionality. We propose here two new dialects: (1) an ONNX specific dialect that encodes the ONNX standard semantics, and (2) a loop-based dialect to provide for a common lowering point for all ONNX dialect operations. Each intermediate representation facilitates its own characteristic set of graph-level and loop-based optimizations respectively. We illustrate our approach by following several models through the proposed representations and we include some early optimization work and performance results.
Profiling based Out-of-core Hybrid Method for Large Neural Networks
Jul 11, 2019
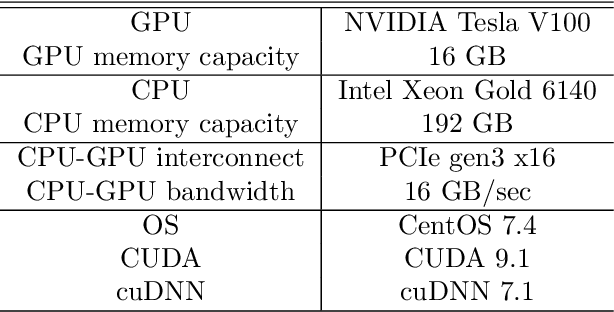
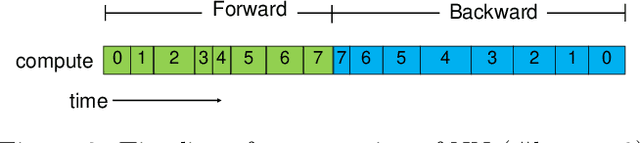

GPUs are widely used to accelerate deep learning with NNs (NNs). On the other hand, since GPU memory capacity is limited, it is difficult to implement efficient programs that compute large NNs on GPU. To compute NNs exceeding GPU memory capacity, data-swapping method and recomputing method have been proposed in existing work. However, in these methods, performance overhead occurs due to data movement or increase of computation. In order to reduce the overhead, it is important to consider characteristics of each layer such as sizes and cost for recomputation. Based on this direction, we proposed Profiling based out-of-core Hybrid method (PoocH). PoocH determines target layers of swapping or recomputing based on runtime profiling. We implemented PoocH by extending a deep learning framework, Chainer, and we evaluated its performance. With PoocH, we successfully computed an NN requiring 50 GB memory on a single GPU with 16 GB memory. Compared with in-core cases, performance degradation was 38 \% on x86 machine and 28 \% on POWER9 machine.
Fast and Accurate 3D Medical Image Segmentation with Data-swapping Method
Dec 19, 2018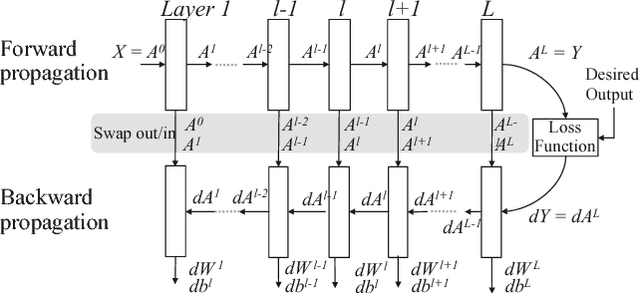
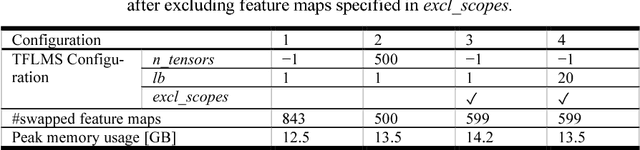
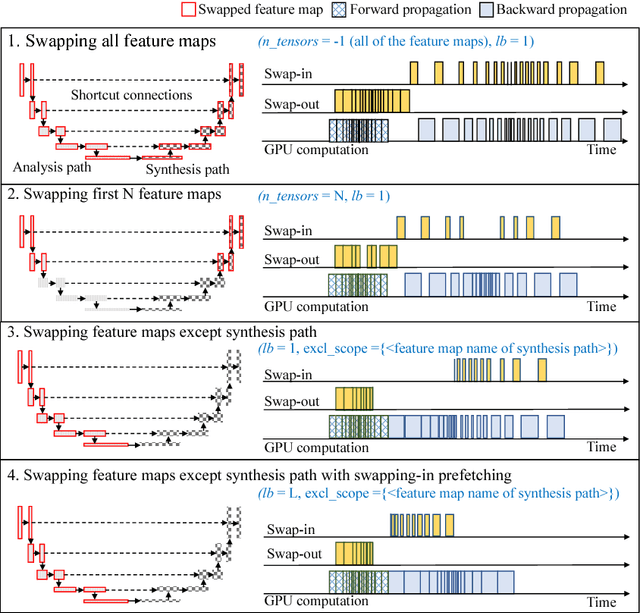
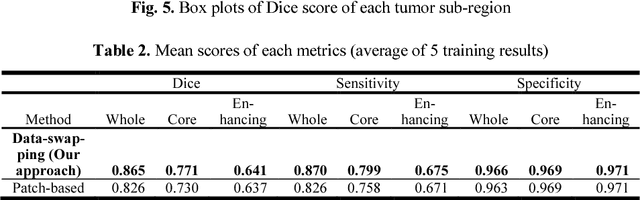
Deep neural network models used for medical image segmentation are large because they are trained with high-resolution three-dimensional (3D) images. Graphics processing units (GPUs) are widely used to accelerate the trainings. However, the memory on a GPU is not large enough to train the models. A popular approach to tackling this problem is patch-based method, which divides a large image into small patches and trains the models with these small patches. However, this method would degrade the segmentation quality if a target object spans multiple patches. In this paper, we propose a novel approach for 3D medical image segmentation that utilizes the data-swapping, which swaps out intermediate data from GPU memory to CPU memory to enlarge the effective GPU memory size, for training high-resolution 3D medical images without patching. We carefully tuned parameters in the data-swapping method to obtain the best training performance for 3D U-Net, a widely used deep neural network model for medical image segmentation. We applied our tuning to train 3D U-Net with full-size images of 192 x 192 x 192 voxels in brain tumor dataset. As a result, communication overhead, which is the most important issue, was reduced by 17.1%. Compared with the patch-based method for patches of 128 x 128 x 128 voxels, our training for full-size images achieved improvement on the mean Dice score by 4.48% and 5.32 % for detecting whole tumor sub-region and tumor core sub-region, respectively. The total training time was reduced from 164 hours to 47 hours, resulting in 3.53 times of acceleration.
TFLMS: Large Model Support in TensorFlow by Graph Rewriting
Jul 05, 2018
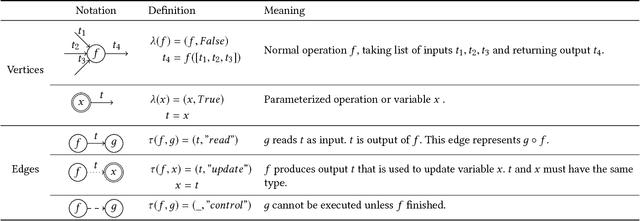
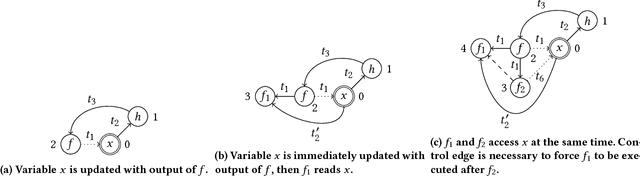

While accelerators such as GPUs have limited memory, deep neural networks are becoming larger and will not fit with the memory limitation of accelerators for training. We propose an approach to tackle this problem by rewriting the computational graph of a neural network, in which swap-out and swap-in operations are inserted to temporarily store intermediate results on CPU memory. In particular, we first revise the concept of a computational graph by defining a concrete semantics for variables in a graph. We then formally show how to derive swap-out and swap-in operations from an existing graph and present rules to optimize the graph. To realize our approach, we developed a module in TensorFlow, named TFLMS. TFLMS is published as a pull request in the TensorFlow repository for contributing to the TensorFlow community. With TFLMS, we were able to train ResNet-50 and 3DUnet with 4.7x and 2x larger batch size, respectively. In particular, we were able to train 3DUNet using images of size of $192^3$ for image segmentation, which, without TFLMS, had been done only by dividing the images to smaller images, which affects the accuracy.