 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast and Accurate 3D Medical Image Segmentation with Data-swapping Method
Dec 19, 2018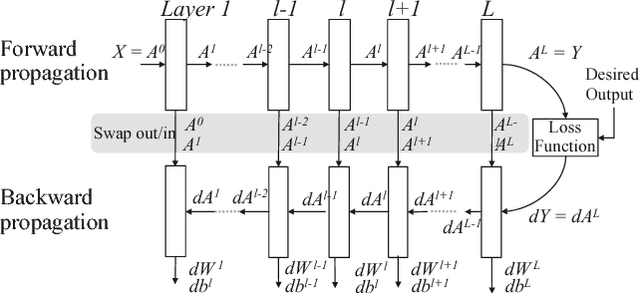
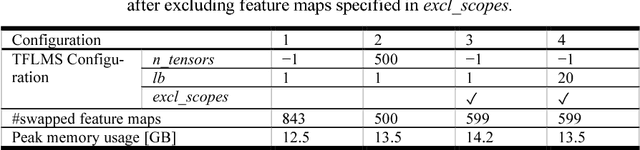
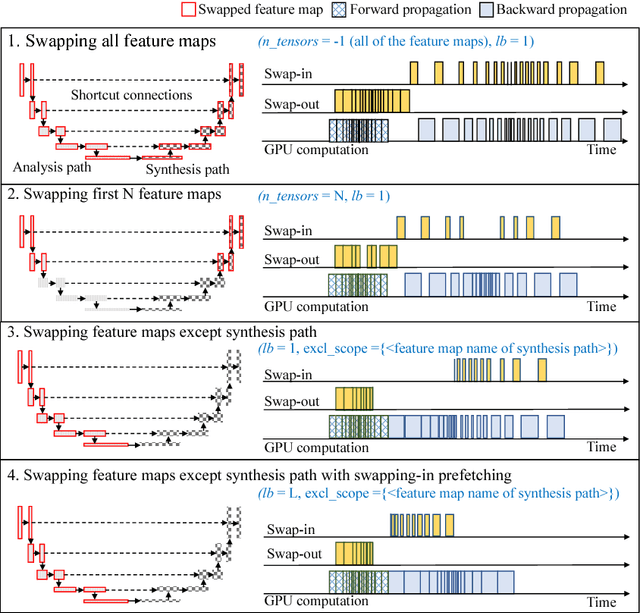
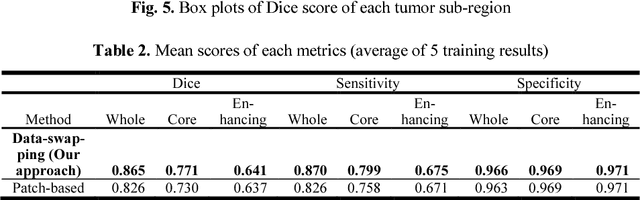
Deep neural network models used for medical image segmentation are large because they are trained with high-resolution three-dimensional (3D) images. Graphics processing units (GPUs) are widely used to accelerate the trainings. However, the memory on a GPU is not large enough to train the models. A popular approach to tackling this problem is patch-based method, which divides a large image into small patches and trains the models with these small patches. However, this method would degrade the segmentation quality if a target object spans multiple patches. In this paper, we propose a novel approach for 3D medical image segmentation that utilizes the data-swapping, which swaps out intermediate data from GPU memory to CPU memory to enlarge the effective GPU memory size, for training high-resolution 3D medical images without patching. We carefully tuned parameters in the data-swapping method to obtain the best training performance for 3D U-Net, a widely used deep neural network model for medical image segmentation. We applied our tuning to train 3D U-Net with full-size images of 192 x 192 x 192 voxels in brain tumor dataset. As a result, communication overhead, which is the most important issue, was reduced by 17.1%. Compared with the patch-based method for patches of 128 x 128 x 128 voxels, our training for full-size images achieved improvement on the mean Dice score by 4.48% and 5.32 % for detecting whole tumor sub-region and tumor core sub-region, respectively. The total training time was reduced from 164 hours to 47 hours, resulting in 3.53 times of acceleration.
Data-parallel distributed training of very large models beyond GPU capacity
Nov 29, 2018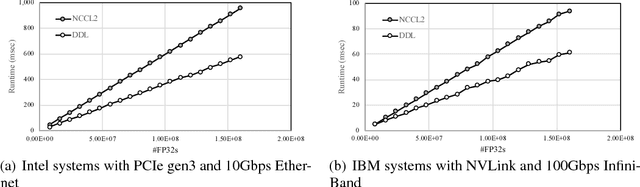

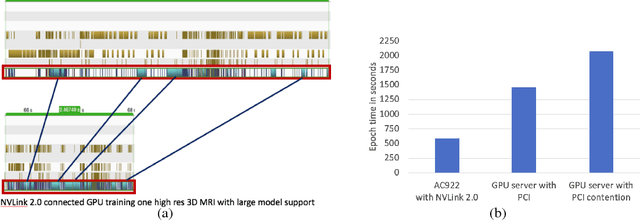

GPUs have limited memory and it is difficult to train wide and/or deep models that cause the training process to go out of memory. It is shown in this paper how an open source tool called Large Model Support (LMS) can utilize a high bandwidth NVLink connection between CPUs and GPUs to accomplish training of deep convolutional networks. LMS performs tensor swapping between CPU memory and GPU memory such that only a minimal number of tensors required in a training step are kept in the GPU memory. It is also shown how LMS can be combined with an MPI based distributed deep learning module to train models in a data-parallel fashion across multiple GPUs, such that each GPU is utilizing the CPU memory for tensor swapping. The hardware architecture that enables the high bandwidth GPU link with the CPU is discussed as well as the associated set of software tools that are available as the PowerAI package.