 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Complexity Radio Frequency Interference Mitigation for Radio Astronomy Using Large Antenna Array
Mar 07, 2024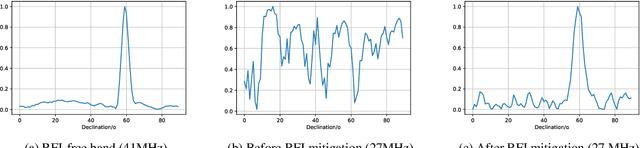
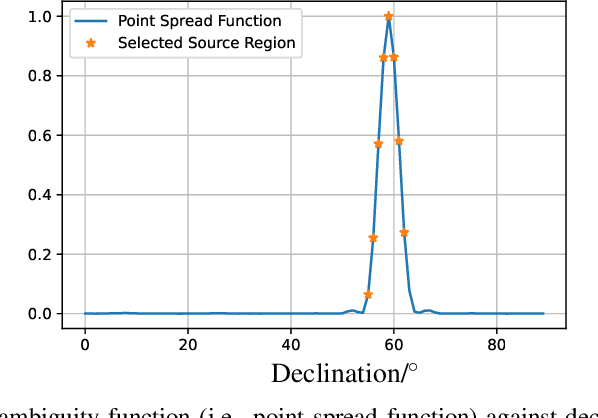
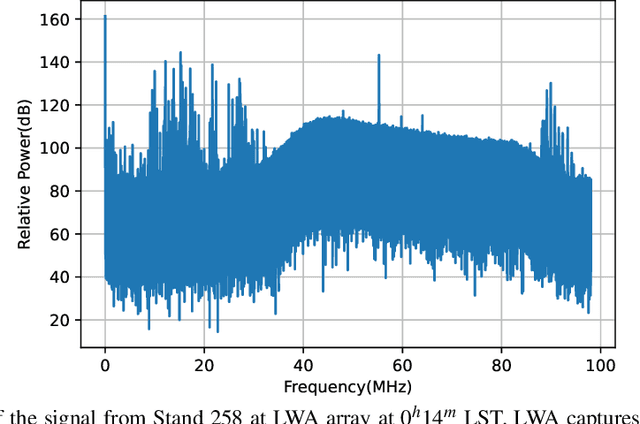
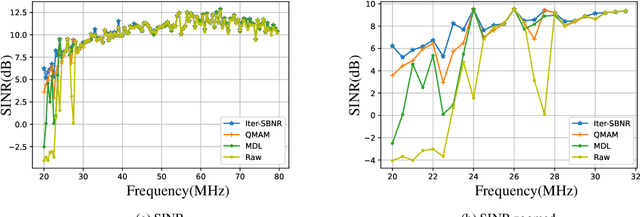
With the ongoing growth in radio communications, there is an increased contamination of radio astronomical source data, which hinders the study of celestial radio sources. In many cases, fast mitigation of strong radio frequency interference (RFI) is valuable for studying short lived radio transients so that the astronomers can perform detailed observations of celestial radio sources. The standard method to manually excise contaminated blocks in time and frequency makes the removed data useless for radio astronomy analyses. This motivates the need for better radio frequency interference (RFI) mitigation techniques for array of size M antennas. Although many solutions for mitigating strong RFI improves the quality of the final celestial source signal, many standard approaches require all the eigenvalues of the spatial covariance matrix ($\textbf{R} \in \mathbb{C}^{M \times M}$) of the received signal, which has $O(M^3)$ computation complexity for removing RFI of size $d$ where $\textit{d} \ll M$. In this work, we investigate two approaches for RFI mitigation, 1) the computationally efficient Lanczos method based on the Quadratic Mean to Arithmetic Mean (QMAM) approach using information from previously-collected data under similar radio-sky-conditions, and 2) an approach using a celestial source as a reference for RFI mitigation. QMAM uses the Lanczos method for finding the Rayleigh-Ritz values of the covariance matrix $\textbf{R}$, thus, reducing the computational complexity of the overall approach to $O(\textit{d}M^2)$. Our numerical results, using data from the radio observatory Long Wavelength Array (LWA-1), demonstrate the effectiveness of both proposed approaches to remove strong RFI, with the QMAM-based approach still being computationally efficient.
Analogies and Feature Attributions for Model Agnostic Explanation of Similarity Learners
Feb 02, 2022

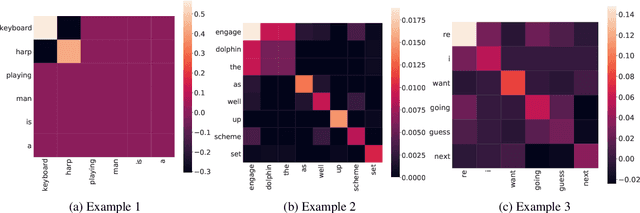

Post-hoc explanations for black box models have been studied extensively in classification and regression settings. However, explanations for models that output similarity between two inputs have received comparatively lesser attention. In this paper, we provide model agnostic local explanations for similarity learners applicable to tabular and text data. We first propose a method that provides feature attributions to explain the similarity between a pair of inputs as determined by a black box similarity learner. We then propose analogies as a new form of explanation in machine learning. Here the goal is to identify diverse analogous pairs of examples that share the same level of similarity as the input pair and provide insight into (latent) factors underlying the model's prediction. The selection of analogies can optionally leverage feature attributions, thus connecting the two forms of explanation while still maintaining complementarity. We prove that our analogy objective function is submodular, making the search for good-quality analogies efficient. We apply the proposed approaches to explain similarities between sentences as predicted by a state-of-the-art sentence encoder, and between patients in a healthcare utilization application. Efficacy is measured through quantitative evaluations, a careful user study, and examples of explanations.
Patient-Specific Seizure Prediction Using Single Seizure Electroencephalography Recording
Nov 14, 2020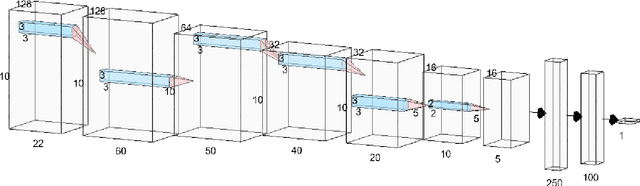
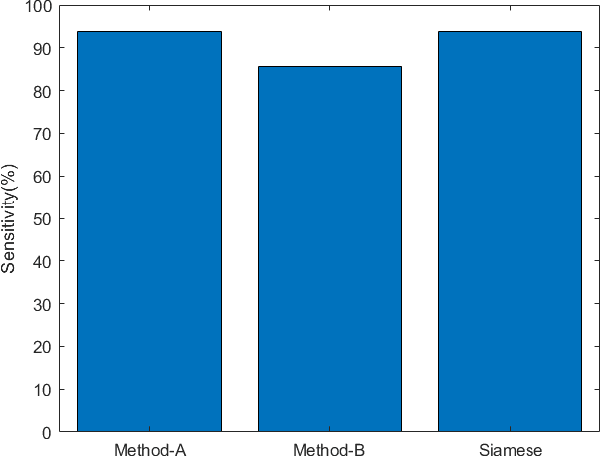
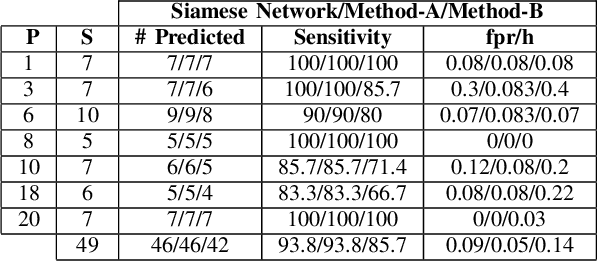
Electroencephalogram (EEG) is a prominent way to measure the brain activity for studying epilepsy, thereby helping in predicting seizures. Seizure prediction is an active research area with many deep learning based approaches dominating the recent literature for solving this problem. But these models require a considerable number of patient-specific seizures to be recorded for extracting the preictal and interictal EEG data for training a classifier. The increase in sensitivity and specificity for seizure prediction using the machine learning models is noteworthy. However, the need for a significant number of patient-specific seizures and periodic retraining of the model because of non-stationary EEG creates difficulties for designing practical device for a patient. To mitigate this process, we propose a Siamese neural network based seizure prediction method that takes a wavelet transformed EEG tensor as an input with convolutional neural network (CNN) as the base network for detecting change-points in EEG. Compared to the solutions in the literature, which utilize days of EEG recordings, our method only needs one seizure for training which translates to less than ten minutes of preictal and interictal data while still getting comparable results to models which utilize multiple seizures for seizure prediction.