 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePromoting High Diversity Ensemble Learning with EnsembleBench
Oct 20, 2020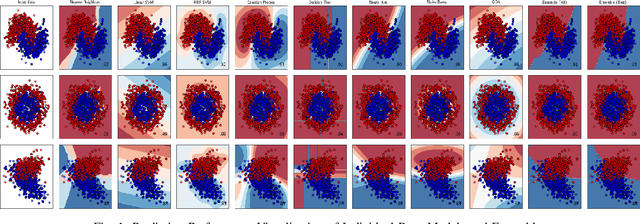
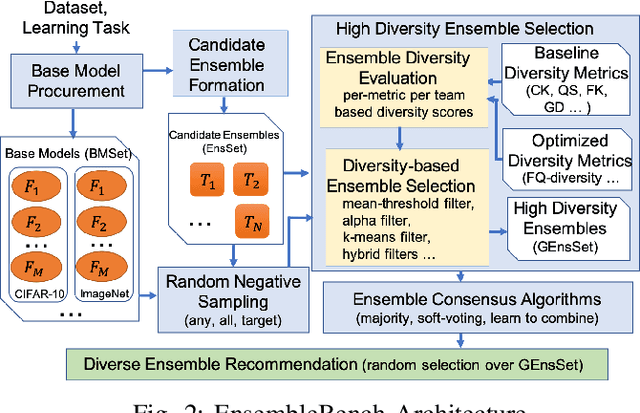
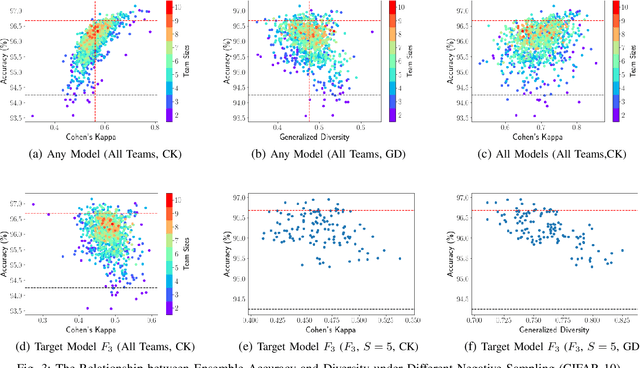
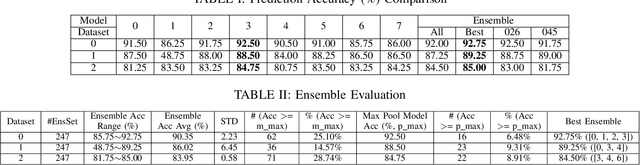
Ensemble learning is gaining renewed interests in recent years. This paper presents EnsembleBench, a holistic framework for evaluating and recommending high diversity and high accuracy ensembles. The design of EnsembleBench offers three novel features: (1) EnsembleBench introduces a set of quantitative metrics for assessing the quality of ensembles and for comparing alternative ensembles constructed for the same learning tasks. (2) EnsembleBench implements a suite of baseline diversity metrics and optimized diversity metrics for identifying and selecting ensembles with high diversity and high quality, making it an effective framework for benchmarking, evaluating and recommending high diversity model ensembles. (3) Four representative ensemble consensus methods are provided in the first release of EnsembleBench, enabling empirical study on the impact of consensus methods on ensemble accuracy. A comprehensive experimental evaluation on popular benchmark datasets demonstrates the utility and effectiveness of EnsembleBench for promoting high diversity ensembles and boosting the overall performance of selected ensembles.
Demystifying Learning Rate Polices for High Accuracy Training of Deep Neural Networks
Aug 18, 2019
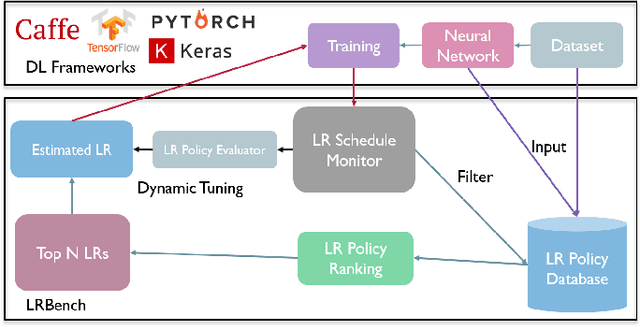
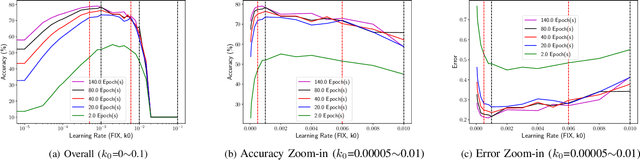
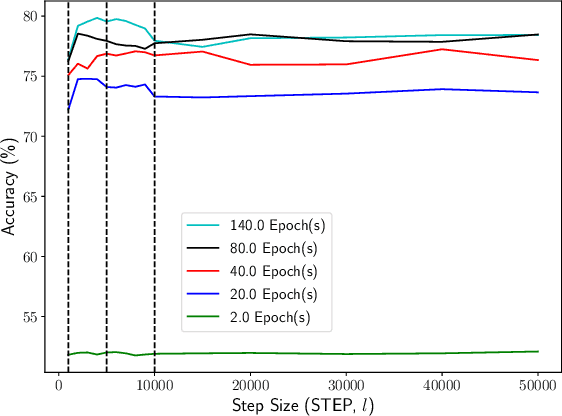
Learning Rate (LR) is an important hyper-parameter to tune for effective training of deep neural networks (DNNs). Even for the baseline of a constant learning rate, it is non-trivial to choose a good constant value for training a DNN. Dynamic learning rates involve multi-step tuning of LR values at various stages of the training process and offer high accuracy and fast convergence. However, they are much harder to tune. In this paper, we present a comprehensive study of 13 learning rate functions and their associated LR policies by examining their range parameters, step parameters, and value update parameters. We propose a set of metrics for evaluating and selecting LR policies, including the classification confidence, variance, cost, and robustness, and implement them in LRBench, an LR benchmarking system. LRBench can assist end-users and DNN developers to select good LR policies and avoid bad LR policies for training their DNNs. We tested LRBench on Caffe, an open source deep learning framework, to showcase the tuning optimization of LR policies. Evaluated through extensive experiments, we attempt to demystify the tuning of LR policies by identifying good LR policies with effective LR value ranges and step sizes for LR update schedules.