 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Domain Adaptation for Metal Cutting Sound Detection: Leveraging Abundant Lab Data for Scarce Industry Data
Oct 23, 2024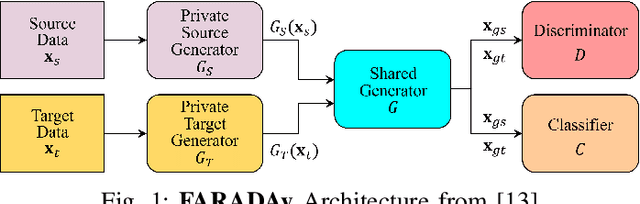
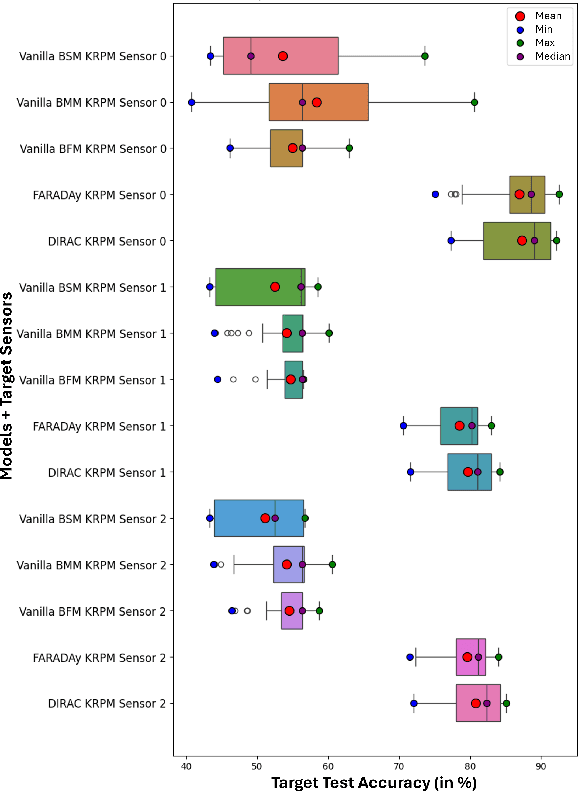
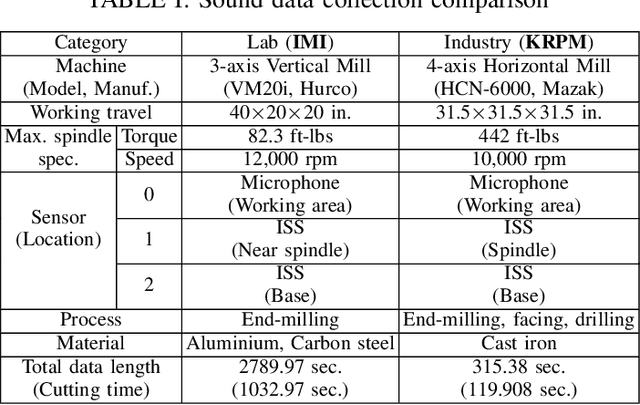

Cutting state monitoring in the milling process is crucial for improving manufacturing efficiency and tool life. Cutting sound detection using machine learning (ML) models, inspired by experienced machinists, can be employed as a cost-effective and non-intrusive monitoring method in a complex manufacturing environment. However, labeling industry data for training is costly and time-consuming. Moreover, industry data is often scarce. In this study, we propose a novel adversarial domain adaptation (DA) approach to leverage abundant lab data to learn from scarce industry data, both labeled, for training a cutting-sound detection model. Rather than adapting the features from separate domains directly, we project them first into two separate latent spaces that jointly work as the feature space for learning domain-independent representations. We also analyze two different mechanisms for adversarial learning where the discriminator works as an adversary and a critic in separate settings, enabling our model to learn expressive domain-invariant and domain-ingrained features, respectively. We collected cutting sound data from multiple sensors in different locations, prepared datasets from lab and industry domain, and evaluated our learning models on them. Experiments showed that our models outperformed the multi-layer perceptron based vanilla domain adaptation models in labeling tasks on the curated datasets, achieving near 92%, 82% and 85% accuracy respectively for three different sensors installed in industry settings.
Transfer Learning for Security: Challenges and Future Directions
Mar 01, 2024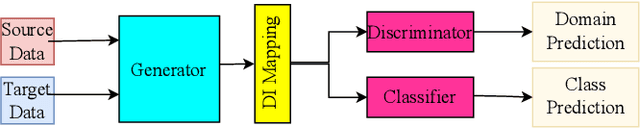

Many machine learning and data mining algorithms rely on the assumption that the training and testing data share the same feature space and distribution. However, this assumption may not always hold. For instance, there are situations where we need to classify data in one domain, but we only have sufficient training data available from a different domain. The latter data may follow a distinct distribution. In such cases, successfully transferring knowledge across domains can significantly improve learning performance and reduce the need for extensive data labeling efforts. Transfer learning (TL) has thus emerged as a promising framework to tackle this challenge, particularly in security-related tasks. This paper aims to review the current advancements in utilizing TL techniques for security. The paper includes a discussion of the existing research gaps in applying TL in the security domain, as well as exploring potential future research directions and issues that arise in the context of TL-assisted security solutions.
Maximal Domain Independent Representations Improve Transfer Learning
Jun 01, 2023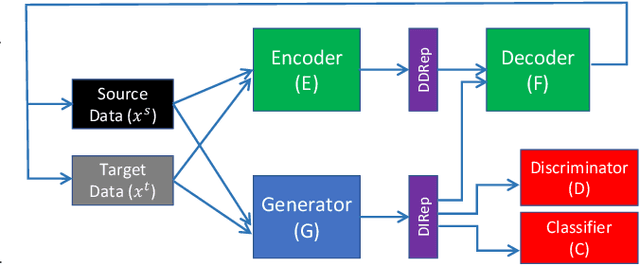
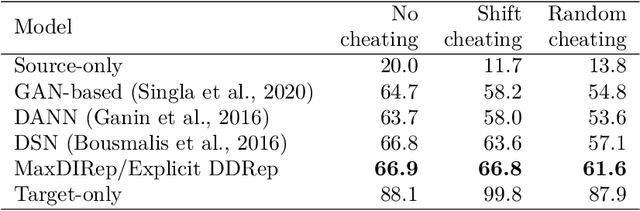
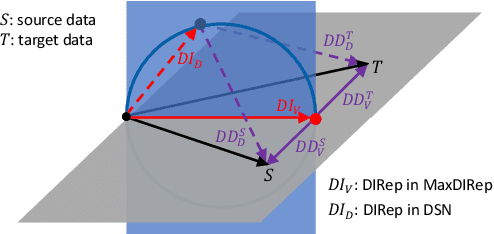

Domain adaptation (DA) adapts a training dataset from a source domain for use in a learning task in a target domain in combination with data available at the target. One popular approach for DA is to create a domain-independent representation (DIRep) learned by a generator from all input samples and then train a classifier on top of it using all labeled samples. A domain discriminator is added to train the generator adversarially to exclude domain specific features from the DIRep. However, this approach tends to generate insufficient information for accurate classification learning. In this paper, we present a novel approach that integrates the adversarial model with a variational autoencoder. In addition to the DIRep, we introduce a domain-dependent representation (DDRep) such that information from both DIRep and DDRep is sufficient to reconstruct samples from both domains. We further penalize the size of the DDRep to drive as much information as possible to the DIRep, which maximizes the accuracy of the classifier in labeling samples in both domains. We empirically evaluate our model using synthetic datasets and demonstrate that spurious class-related features introduced in the source domain are successfully absorbed by the DDRep. This leaves a rich and clean DIRep for accurate transfer learning in the target domain. We further demonstrate its superior performance against other algorithms for a number of common image datasets. We also show we can take advantage of pretrained models.
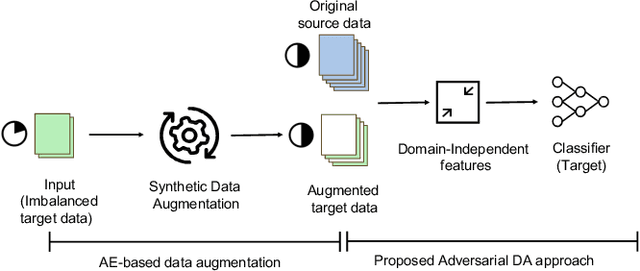
Building Manufacturing Deep Learning Models with Minimal and Imbalanced Training Data Using Domain Adaptation and Data Augmentation
May 31, 2023



Deep learning (DL) techniques are highly effective for defect detection from images. Training DL classification models, however, requires vast amounts of labeled data which is often expensive to collect. In many cases, not only the available training data is limited but may also imbalanced. In this paper, we propose a novel domain adaptation (DA) approach to address the problem of labeled training data scarcity for a target learning task by transferring knowledge gained from an existing source dataset used for a similar learning task. Our approach works for scenarios where the source dataset and the dataset available for the target learning task have same or different feature spaces. We combine our DA approach with an autoencoder-based data augmentation approach to address the problem of imbalanced target datasets. We evaluate our combined approach using image data for wafer defect prediction. The experiments show its superior performance against other algorithms when the number of labeled samples in the target dataset is significantly small and the target dataset is imbalanced.