 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAT: Can Trust be Predicted with Context-Awareness in Dynamic Heterogeneous Networks?
Dec 12, 2025Trust prediction provides valuable support for decision-making, risk mitigation, and system security enhancement. Recently, Graph Neural Networks (GNNs) have emerged as a promising approach for trust prediction, owing to their ability to learn expressive node representations that capture intricate trust relationships within a network. However, current GNN-based trust prediction models face several limitations: (i) Most of them fail to capture trust dynamicity, leading to questionable inferences. (ii) They rarely consider the heterogeneous nature of real-world networks, resulting in a loss of rich semantics. (iii) None of them support context-awareness, a basic property of trust, making prediction results coarse-grained. To this end, we propose CAT, the first Context-Aware GNN-based Trust prediction model that supports trust dynamicity and accurately represents real-world heterogeneity. CAT consists of a graph construction layer, an embedding layer, a heterogeneous attention layer, and a prediction layer. It handles dynamic graphs using continuous-time representations and captures temporal information through a time encoding function. To model graph heterogeneity and leverage semantic information, CAT employs a dual attention mechanism that identifies the importance of different node types and nodes within each type. For context-awareness, we introduce a new notion of meta-paths to extract contextual features. By constructing context embeddings and integrating a context-aware aggregator, CAT can predict both context-aware trust and overall trust. Extensive experiments on three real-world datasets demonstrate that CAT outperforms five groups of baselines in trust prediction, while exhibiting strong scalability to large-scale graphs and robustness against both trust-oriented and GNN-oriented attacks.
FlowMur: A Stealthy and Practical Audio Backdoor Attack with Limited Knowledge
Dec 15, 2023

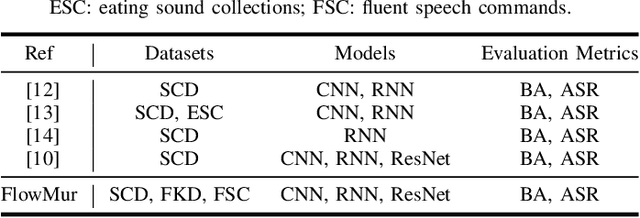

Speech recognition systems driven by DNNs have revolutionized human-computer interaction through voice interfaces, which significantly facilitate our daily lives. However, the growing popularity of these systems also raises special concerns on their security, particularly regarding backdoor attacks. A backdoor attack inserts one or more hidden backdoors into a DNN model during its training process, such that it does not affect the model's performance on benign inputs, but forces the model to produce an adversary-desired output if a specific trigger is present in the model input. Despite the initial success of current audio backdoor attacks, they suffer from the following limitations: (i) Most of them require sufficient knowledge, which limits their widespread adoption. (ii) They are not stealthy enough, thus easy to be detected by humans. (iii) Most of them cannot attack live speech, reducing their practicality. To address these problems, in this paper, we propose FlowMur, a stealthy and practical audio backdoor attack that can be launched with limited knowledge. FlowMur constructs an auxiliary dataset and a surrogate model to augment adversary knowledge. To achieve dynamicity, it formulates trigger generation as an optimization problem and optimizes the trigger over different attachment positions. To enhance stealthiness, we propose an adaptive data poisoning method according to Signal-to-Noise Ratio (SNR). Furthermore, ambient noise is incorporated into the process of trigger generation and data poisoning to make FlowMur robust to ambient noise and improve its practicality. Extensive experiments conducted on two datasets demonstrate that FlowMur achieves high attack performance in both digital and physical settings while remaining resilient to state-of-the-art defenses. In particular, a human study confirms that triggers generated by FlowMur are not easily detected by participants.
Backdoor Attacks against Voice Recognition Systems: A Survey
Jul 23, 2023Voice Recognition Systems (VRSs) employ deep learning for speech recognition and speaker recognition. They have been widely deployed in various real-world applications, from intelligent voice assistance to telephony surveillance and biometric authentication. However, prior research has revealed the vulnerability of VRSs to backdoor attacks, which pose a significant threat to the security and privacy of VRSs. Unfortunately, existing literature lacks a thorough review on this topic. This paper fills this research gap by conducting a comprehensive survey on backdoor attacks against VRSs. We first present an overview of VRSs and backdoor attacks, elucidating their basic knowledge. Then we propose a set of evaluation criteria to assess the performance of backdoor attack methods. Next, we present a comprehensive taxonomy of backdoor attacks against VRSs from different perspectives and analyze the characteristic of different categories. After that, we comprehensively review existing attack methods and analyze their pros and cons based on the proposed criteria. Furthermore, we review classic backdoor defense methods and generic audio defense techniques. Then we discuss the feasibility of deploying them on VRSs. Finally, we figure out several open issues and further suggest future research directions to motivate the research of VRSs security.
TrustGuard: GNN-based Robust and Explainable Trust Evaluation with Dynamicity Support
Jul 13, 2023Trust evaluation assesses trust relationships between entities and facilitates decision-making. Machine Learning (ML) shows great potential for trust evaluation owing to its learning capabilities. In recent years, Graph Neural Networks (GNNs), as a new ML paradigm, have demonstrated superiority in dealing with graph data. This has motivated researchers to explore their use in trust evaluation, as trust relationships among entities can be modeled as a graph. However, current trust evaluation methods that employ GNNs fail to fully satisfy the dynamic nature of trust, overlook the adverse effects of attacks on trust evaluation, and cannot provide convincing explanations on evaluation results. To address these problems, we propose TrustGuard, a GNN-based accurate trust evaluation model that supports trust dynamicity, is robust against typical attacks, and provides explanations through visualization. Specifically, TrustGuard is designed with a layered architecture that contains a snapshot input layer, a spatial aggregation layer, a temporal aggregation layer, and a prediction layer. Among them, the spatial aggregation layer adopts a defense mechanism to robustly aggregate local trust, and the temporal aggregation layer applies an attention mechanism for effective learning of temporal patterns. Extensive experiments on two real-world datasets show that TrustGuard outperforms state-of-the-art GNN-based trust evaluation models with respect to trust prediction across single-timeslot and multi-timeslot, even in the presence of attacks. In addition, TrustGuard can explain its evaluation results by visualizing both spatial and temporal views.
Adversarial attacks and defenses in Speaker Recognition Systems: A survey
May 27, 2022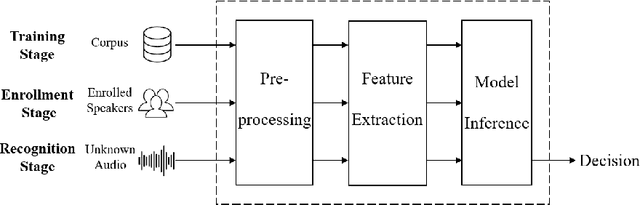
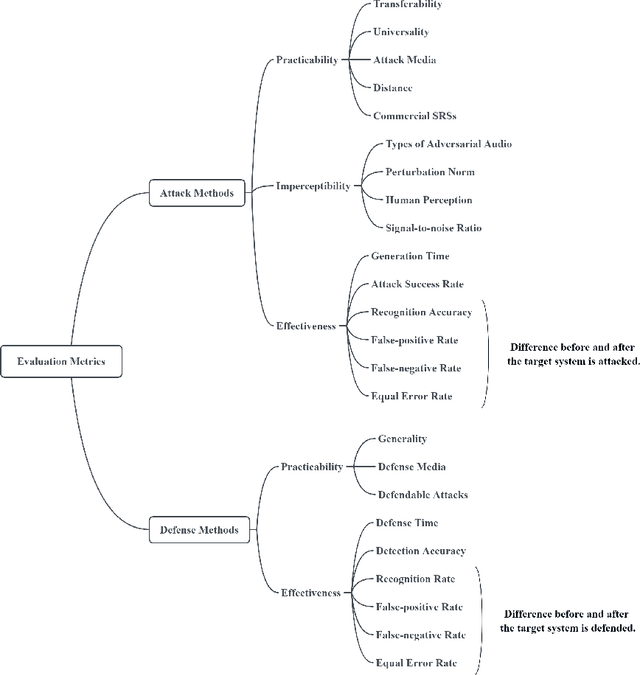
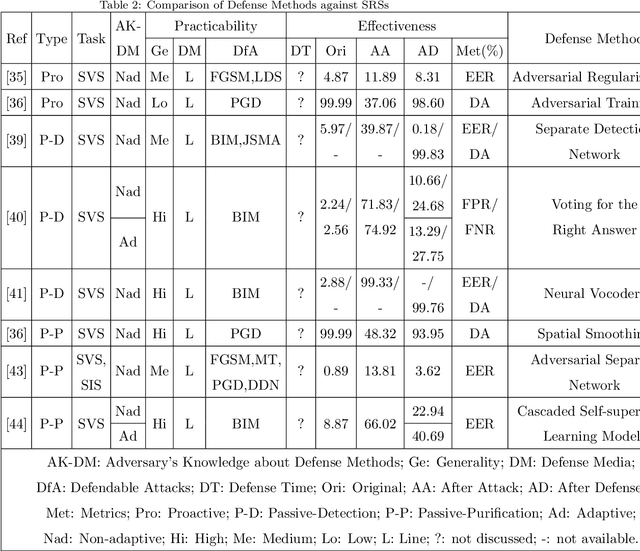
Speaker recognition has become very popular in many application scenarios, such as smart homes and smart assistants, due to ease of use for remote control and economic-friendly features. The rapid development of SRSs is inseparable from the advancement of machine learning, especially neural networks. However, previous work has shown that machine learning models are vulnerable to adversarial attacks in the image domain, which inspired researchers to explore adversarial attacks and defenses in Speaker Recognition Systems (SRS). Unfortunately, existing literature lacks a thorough review of this topic. In this paper, we fill this gap by performing a comprehensive survey on adversarial attacks and defenses in SRSs. We first introduce the basics of SRSs and concepts related to adversarial attacks. Then, we propose two sets of criteria to evaluate the performance of attack methods and defense methods in SRSs, respectively. After that, we provide taxonomies of existing attack methods and defense methods, and further review them by employing our proposed criteria. Finally, based on our review, we find some open issues and further specify a number of future directions to motivate the research of SRSs security.