 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial attacks and defenses in Speaker Recognition Systems: A survey
Paper and Code
May 27, 2022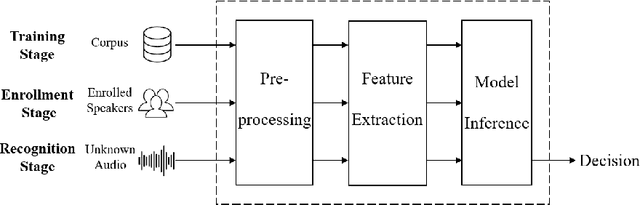
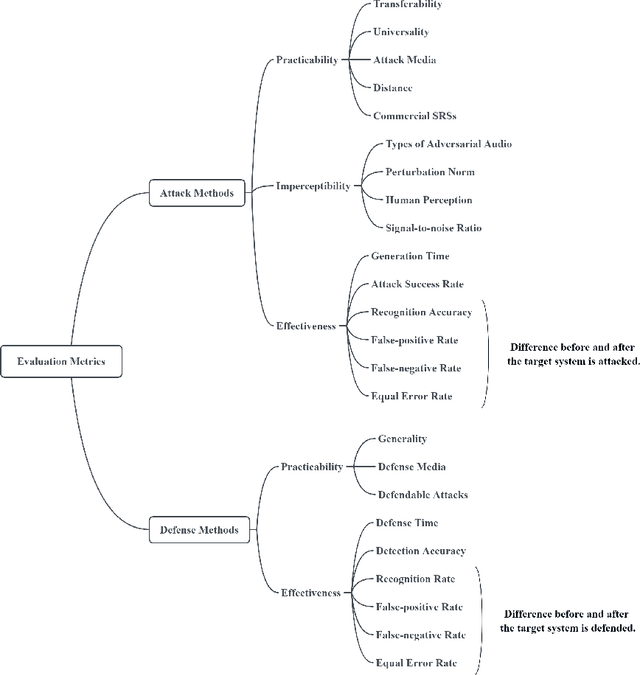
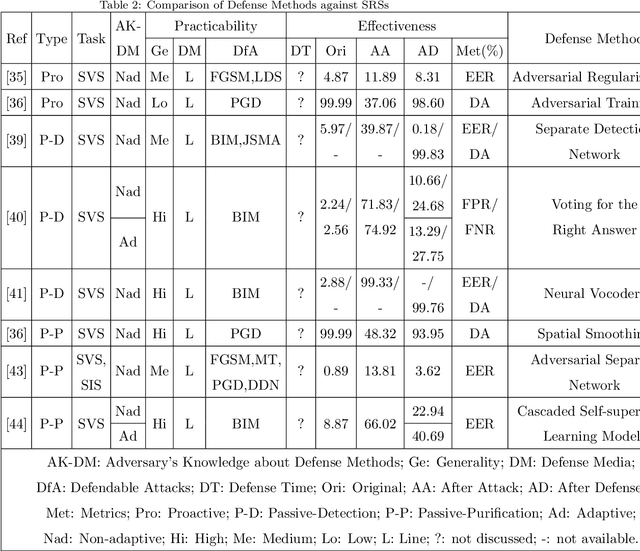
Speaker recognition has become very popular in many application scenarios, such as smart homes and smart assistants, due to ease of use for remote control and economic-friendly features. The rapid development of SRSs is inseparable from the advancement of machine learning, especially neural networks. However, previous work has shown that machine learning models are vulnerable to adversarial attacks in the image domain, which inspired researchers to explore adversarial attacks and defenses in Speaker Recognition Systems (SRS). Unfortunately, existing literature lacks a thorough review of this topic. In this paper, we fill this gap by performing a comprehensive survey on adversarial attacks and defenses in SRSs. We first introduce the basics of SRSs and concepts related to adversarial attacks. Then, we propose two sets of criteria to evaluate the performance of attack methods and defense methods in SRSs, respectively. After that, we provide taxonomies of existing attack methods and defense methods, and further review them by employing our proposed criteria. Finally, based on our review, we find some open issues and further specify a number of future directions to motivate the research of SRSs security.