 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCellularLint: A Systematic Approach to Identify Inconsistent Behavior in Cellular Network Specifications
Jul 18, 2024


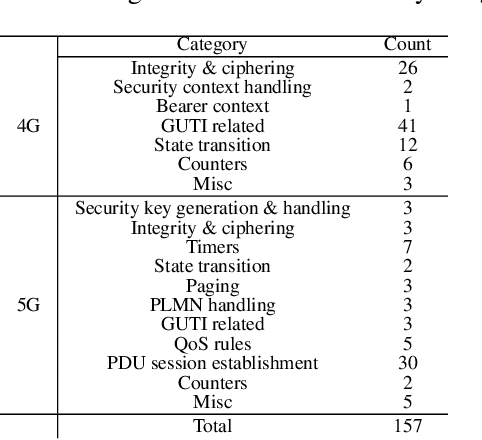
In recent years, there has been a growing focus on scrutinizing the security of cellular networks, often attributing security vulnerabilities to issues in the underlying protocol design descriptions. These protocol design specifications, typically extensive documents that are thousands of pages long, can harbor inaccuracies, underspecifications, implicit assumptions, and internal inconsistencies. In light of the evolving landscape, we introduce CellularLint--a semi-automatic framework for inconsistency detection within the standards of 4G and 5G, capitalizing on a suite of natural language processing techniques. Our proposed method uses a revamped few-shot learning mechanism on domain-adapted large language models. Pre-trained on a vast corpus of cellular network protocols, this method enables CellularLint to simultaneously detect inconsistencies at various levels of semantics and practical use cases. In doing so, CellularLint significantly advances the automated analysis of protocol specifications in a scalable fashion. In our investigation, we focused on the Non-Access Stratum (NAS) and the security specifications of 4G and 5G networks, ultimately uncovering 157 inconsistencies with 82.67% accuracy. After verification of these inconsistencies on open-source implementations and 17 commercial devices, we confirm that they indeed have a substantial impact on design decisions, potentially leading to concerns related to privacy, integrity, availability, and interoperability.
Code Hallucination
Jul 05, 2024Generative models such as large language models are extensively used as code copilots and for whole program generation. However, the programs they generate often have questionable correctness, authenticity and reliability in terms of integration as they might not follow the user requirements, provide incorrect and/or nonsensical outputs, or even contain semantic/syntactic errors - overall known as LLM hallucination. In this work, we present several types of code hallucination. We have generated such hallucinated code manually using large language models. We also present a technique - HallTrigger, in order to demonstrate efficient ways of generating arbitrary code hallucination. Our method leverages 3 different dynamic attributes of LLMs to craft prompts that can successfully trigger hallucinations from models without the need to access model architecture or parameters. Results from popular blackbox models suggest that HallTrigger is indeed effective and the pervasive LLM hallucination have sheer impact on software development.
SPEC5G: A Dataset for 5G Cellular Network Protocol Analysis
Jan 22, 2023
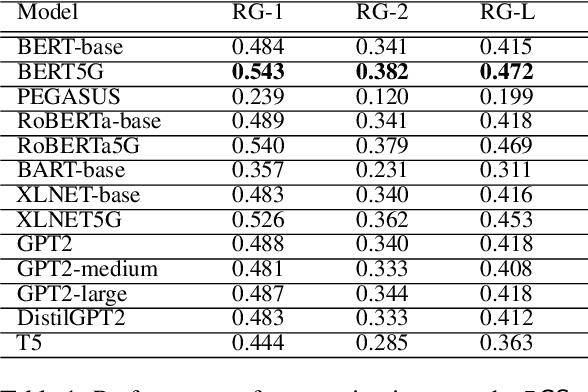
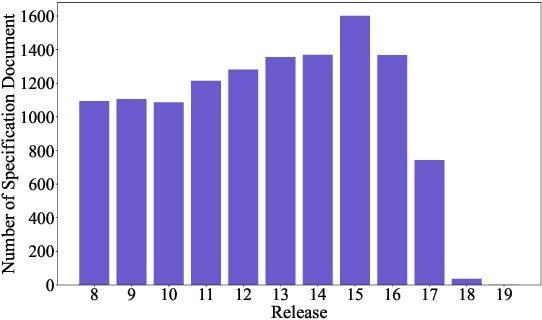
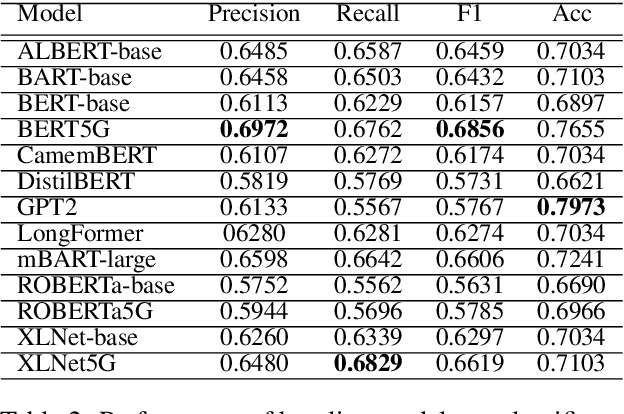
5G is the 5th generation cellular network protocol. It is the state-of-the-art global wireless standard that enables an advanced kind of network designed to connect virtually everyone and everything with increased speed and reduced latency. Therefore, its development, analysis, and security are critical. However, all approaches to the 5G protocol development and security analysis, e.g., property extraction, protocol summarization, and semantic analysis of the protocol specifications and implementations are completely manual. To reduce such manual effort, in this paper, we curate SPEC5G the first-ever public 5G dataset for NLP research. The dataset contains 3,547,586 sentences with 134M words, from 13094 cellular network specifications and 13 online websites. By leveraging large-scale pre-trained language models that have achieved state-of-the-art results on NLP tasks, we use this dataset for security-related text classification and summarization. Security-related text classification can be used to extract relevant security-related properties for protocol testing. On the other hand, summarization can help developers and practitioners understand the high level of the protocol, which is itself a daunting task. Our results show the value of our 5G-centric dataset in 5G protocol analysis automation. We believe that SPEC5G will enable a new research direction into automatic analyses for the 5G cellular network protocol and numerous related downstream tasks. Our data and code are publicly available.