 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from the Best: Active Learning for Wireless Communications
Jan 23, 2024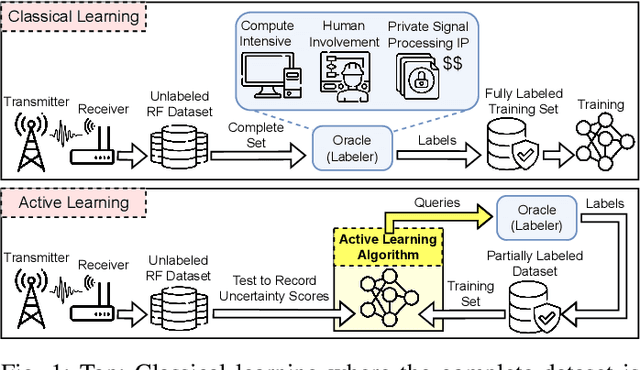
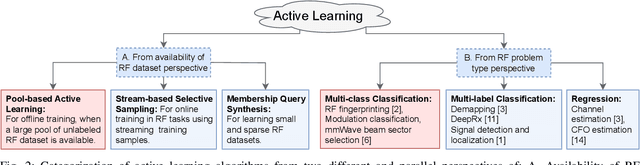
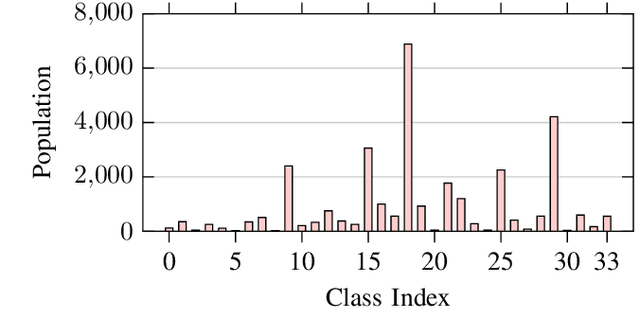
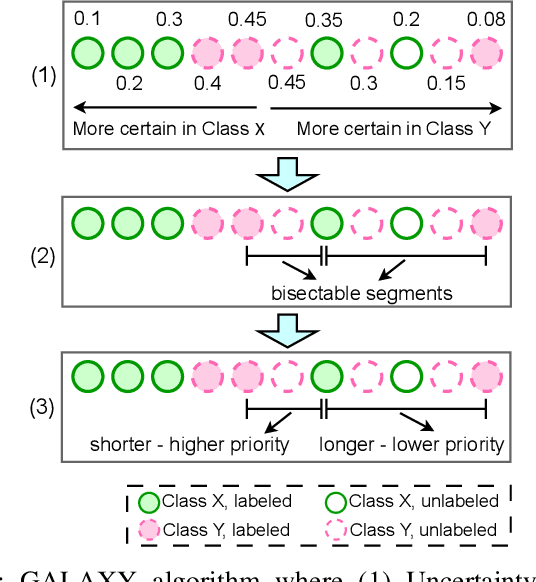
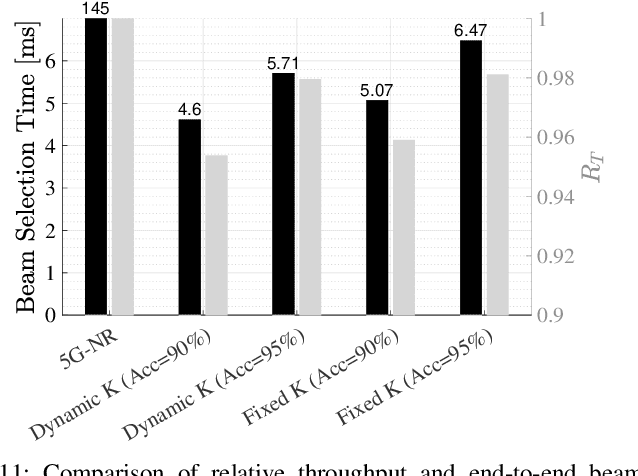
Collecting an over-the-air wireless communications training dataset for deep learning-based communication tasks is relatively simple. However, labeling the dataset requires expert involvement and domain knowledge, may involve private intellectual properties, and is often computationally and financially expensive. Active learning is an emerging area of research in machine learning that aims to reduce the labeling overhead without accuracy degradation. Active learning algorithms identify the most critical and informative samples in an unlabeled dataset and label only those samples, instead of the complete set. In this paper, we introduce active learning for deep learning applications in wireless communications, and present its different categories. We present a case study of deep learning-based mmWave beam selection, where labeling is performed by a compute-intensive algorithm based on exhaustive search. We evaluate the performance of different active learning algorithms on a publicly available multi-modal dataset with different modalities including image and LiDAR. Our results show that using an active learning algorithm for class-imbalanced datasets can reduce labeling overhead by up to 50% for this dataset while maintaining the same accuracy as classical training.
Multiverse at the Edge: Interacting Real World and Digital Twins for Wireless Beamforming
May 10, 2023Creating a digital world that closely mimics the real world with its many complex interactions and outcomes is possible today through advanced emulation software and ubiquitous computing power. Such a software-based emulation of an entity that exists in the real world is called a 'digital twin'. In this paper, we consider a twin of a wireless millimeter-wave band radio that is mounted on a vehicle and show how it speeds up directional beam selection in mobile environments. To achieve this, we go beyond instantiating a single twin and propose the 'Multiverse' paradigm, with several possible digital twins attempting to capture the real world at different levels of fidelity. Towards this goal, this paper describes (i) a decision strategy at the vehicle that determines which twin must be used given the computational and latency limitations, and (ii) a self-learning scheme that uses the Multiverse-guided beam outcomes to enhance DL-based decision-making in the real world over time. Our work is distinguished from prior works as follows: First, we use a publicly available RF dataset collected from an autonomous car for creating different twins. Second, we present a framework with continuous interaction between the real world and Multiverse of twins at the edge, as opposed to a one-time emulation that is completed prior to actual deployment. Results reveal that Multiverse offers up to 79.43% and 85.22% top-10 beam selection accuracy for LOS and NLOS scenarios, respectively. Moreover, we observe 52.72-85.07% improvement in beam selection time compared to 802.11ad standard.
Going Beyond RF: How AI-enabled Multimodal Beamforming will Shape the NextG Standard
Mar 30, 2022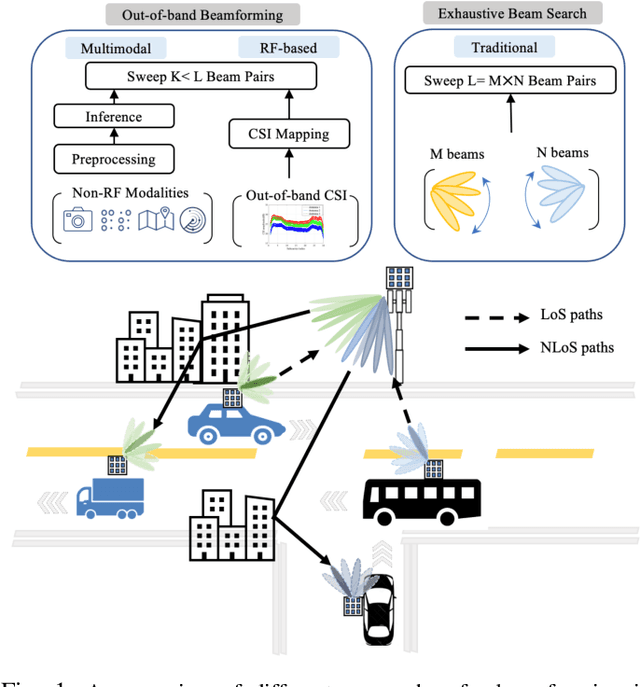


Incorporating artificial intelligence and machine learning (AI/ML) methods within the 5G wireless standard promises autonomous network behavior and ultra-low-latency reconfiguration. However, the effort so far has purely focused on learning from radio frequency (RF) signals. Future standards and next-generation (nextG) networks beyond 5G will have two significant evolutions over the state-of-the-art 5G implementations: (i) massive number of antenna elements, scaling up to hundreds-to-thousands in number, and (ii) inclusion of AI/ML in the critical path of the network reconfiguration process that can access sensor feeds from a variety of RF and non-RF sources. While the former allows unprecedented flexibility in 'beamforming', where signals combine constructively at a target receiver, the latter enables the network with enhanced situation awareness not captured by a single and isolated data modality. This survey presents a thorough analysis of the different approaches used for beamforming today, focusing on mmWave bands, and then proceeds to make a compelling case for considering non-RF sensor data from multiple modalities, such as LiDAR, Radar, GPS for increasing beamforming directional accuracy and reducing processing time. This so called idea of multimodal beamforming will require deep learning based fusion techniques, which will serve to augment the current RF-only and classical signal processing methods that do not scale well for massive antenna arrays. The survey describes relevant deep learning architectures for multimodal beamforming, identifies computational challenges and the role of edge computing in this process, dataset generation tools, and finally, lists open challenges that the community should tackle to realize this transformative vision of the future of beamforming.
Deep Learning on Multimodal Sensor Data at the Wireless Edge for Vehicular Network
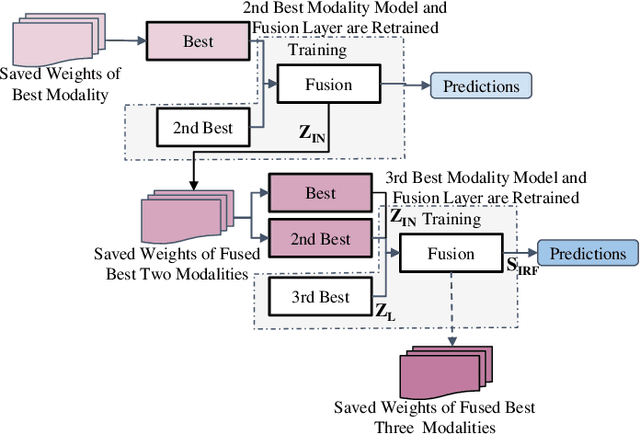
Jan 12, 2022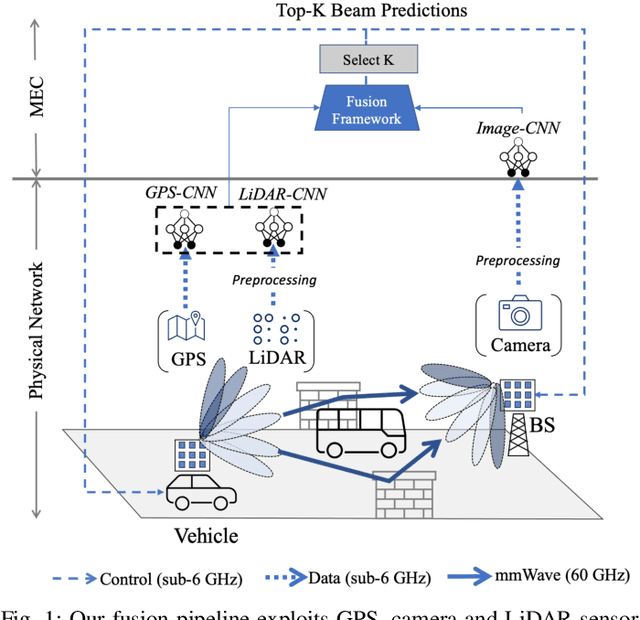

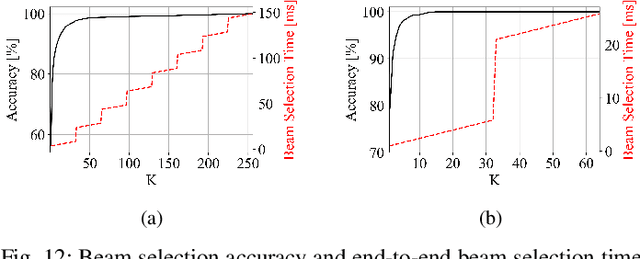
Beam selection for millimeter-wave links in a vehicular scenario is a challenging problem, as an exhaustive search among all candidate beam pairs cannot be assuredly completed within short contact times. We solve this problem via a novel expediting beam selection by leveraging multimodal data collected from sensors like LiDAR, camera images, and GPS. We propose individual modality and distributed fusion-based deep learning (F-DL) architectures that can execute locally as well as at a mobile edge computing center (MEC), with a study on associated tradeoffs. We also formulate and solve an optimization problem that considers practical beam-searching, MEC processing and sensor-to-MEC data delivery latency overheads for determining the output dimensions of the above F-DL architectures. Results from extensive evaluations conducted on publicly available synthetic and home-grown real-world datasets reveal 95% and 96% improvement in beam selection speed over classical RF-only beam sweeping, respectively. F-DL also outperforms the state-of-the-art techniques by 20-22% in predicting top-10 best beam pairs.
PRONTO: Preamble Overhead Reduction with Neural Networks for Coarse Synchronization
Dec 20, 2021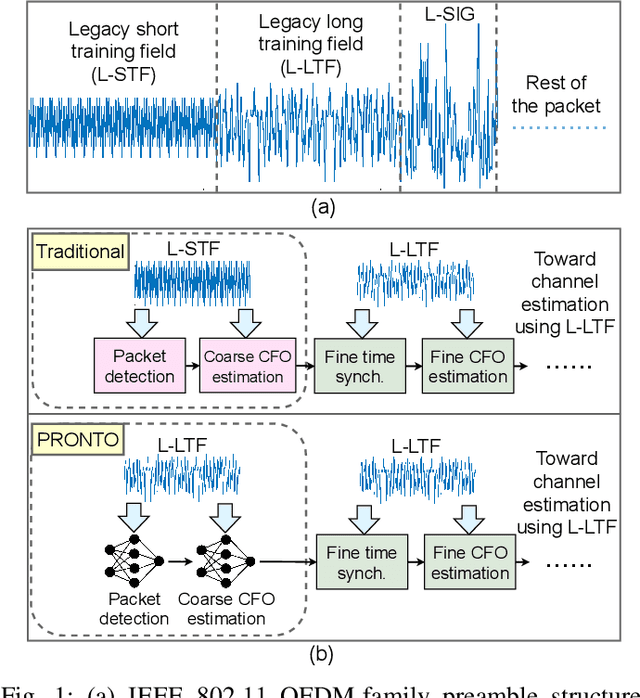
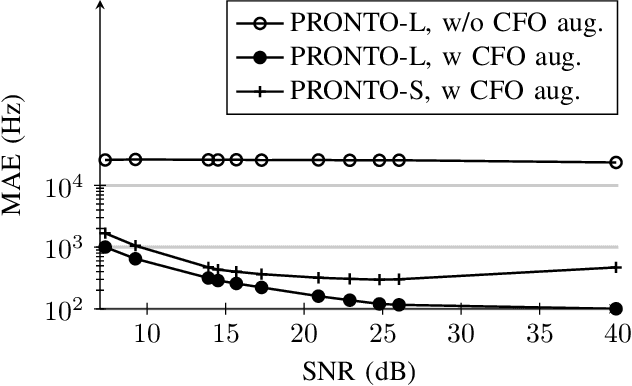
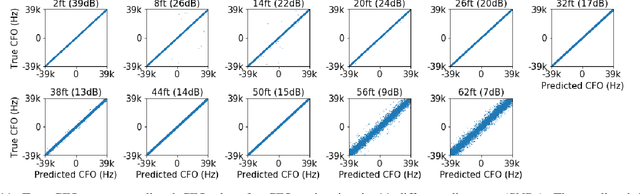
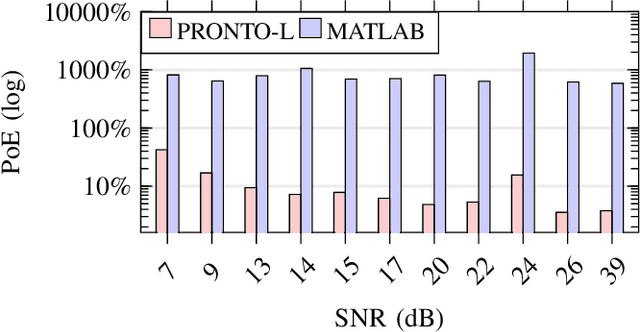
In IEEE 802.11 WiFi-based waveforms, the receiver performs coarse time and frequency synchronization using the first field of the preamble known as the legacy short training field (L-STF). The L-STF occupies upto 40% of the preamble length and takes upto 32 us of airtime. With the goal of reducing communication overhead, we propose a modified waveform, where the preamble length is reduced by eliminating the L-STF. To decode this modified waveform, we propose a machine learning (ML)-based scheme called PRONTO that performs coarse time and frequency estimations using other preamble fields, specifically the legacy long training field (L-LTF). Our contributions are threefold: (i) We present PRONTO featuring customized convolutional neural networks (CNNs) for packet detection and coarse CFO estimation, along with data augmentation steps for robust training. (ii) We propose a generalized decision flow that makes PRONTO compatible with legacy waveforms that include the standard L-STF. (iii) We validate the outcomes on an over-the-air WiFi dataset from a testbed of software defined radios (SDRs). Our evaluations show that PRONTO can perform packet detection with 100% accuracy, and coarse CFO estimation with errors as small as 3%. We demonstrate that PRONTO provides upto 40% preamble length reduction with no bit error rate (BER) degradation. Finally, we experimentally show the speedup achieved by PRONTO through GPU parallelization over the corresponding CPU-only implementations.