 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Network Intrusion Detection Systems: A Multi-Layer Ensemble Approach to Mitigate Adversarial Attacks
Mar 11, 2026Adversarial examples can represent a serious threat to machine learning (ML) algorithms. If used to manipulate the behaviour of ML-based Network Intrusion Detection Systems (NIDS), they can jeopardize network security. In this work, we aim to mitigate such risks by increasing the robustness of NIDS towards adversarial attacks. To that end, we explore two adversarial methods for generating malicious network traffic. The first method is based on Generative Adversarial Networks (GAN) and the second one is the Fast Gradient Sign Method (FGSM). The adversarial examples generated by these methods are then used to evaluate a novel multilayer defense mechanism, specifically designed to mitigate the vulnerability of ML-based NIDS. Our solution consists of one layer of stacking classifiers and a second layer based on an autoencoder. If the incoming network data are classified as benign by the first layer, the second layer is activated to ensure that the decision made by the stacking classifier is correct. We also incorporated adversarial training to further improve the robustness of our solution. Experiments on two datasets, namely UNSW-NB15 and NSL-KDD, demonstrate that the proposed approach increases resilience to adversarial attacks.
Learning from the Best: Active Learning for Wireless Communications
Jan 23, 2024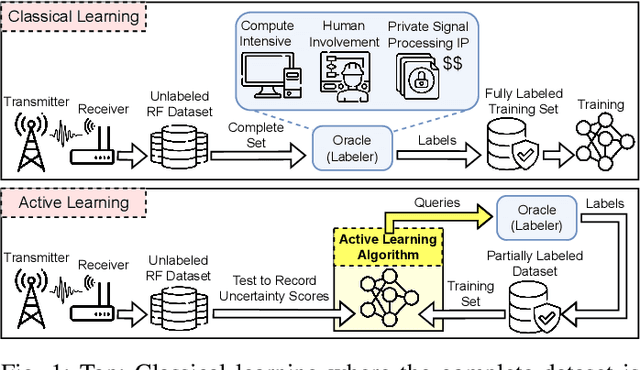
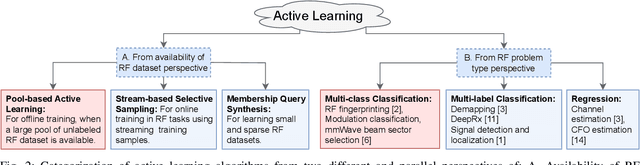
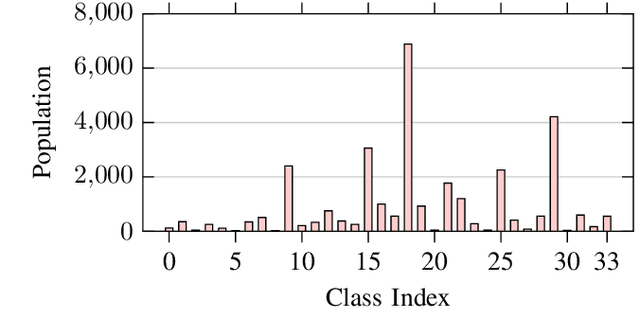
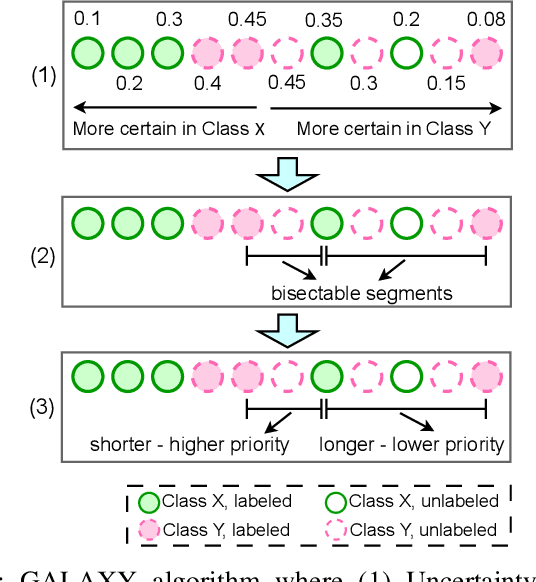
Collecting an over-the-air wireless communications training dataset for deep learning-based communication tasks is relatively simple. However, labeling the dataset requires expert involvement and domain knowledge, may involve private intellectual properties, and is often computationally and financially expensive. Active learning is an emerging area of research in machine learning that aims to reduce the labeling overhead without accuracy degradation. Active learning algorithms identify the most critical and informative samples in an unlabeled dataset and label only those samples, instead of the complete set. In this paper, we introduce active learning for deep learning applications in wireless communications, and present its different categories. We present a case study of deep learning-based mmWave beam selection, where labeling is performed by a compute-intensive algorithm based on exhaustive search. We evaluate the performance of different active learning algorithms on a publicly available multi-modal dataset with different modalities including image and LiDAR. Our results show that using an active learning algorithm for class-imbalanced datasets can reduce labeling overhead by up to 50% for this dataset while maintaining the same accuracy as classical training.
Neural Network-based OFDM Receiver for Resource Constrained IoT Devices
May 12, 2022
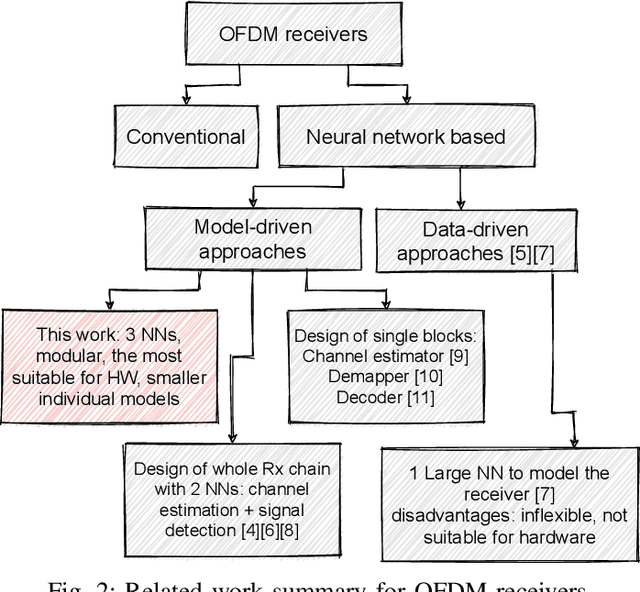
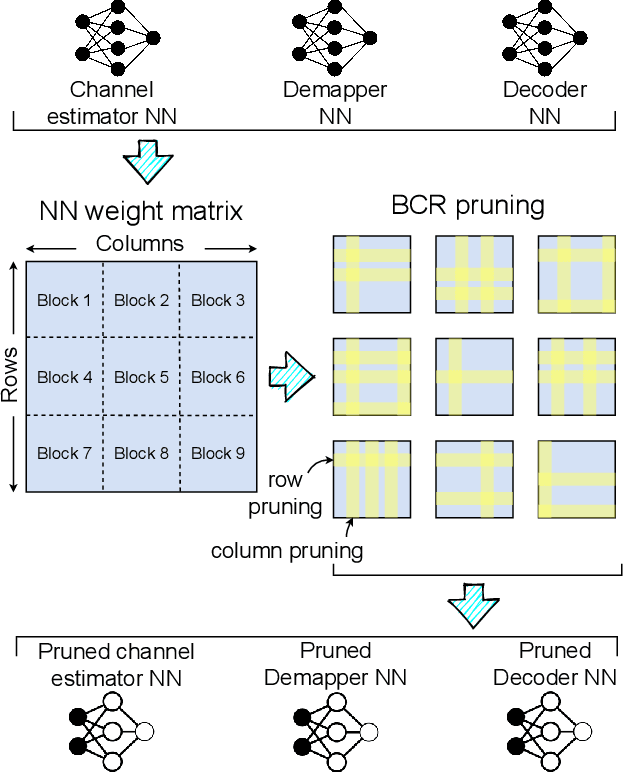
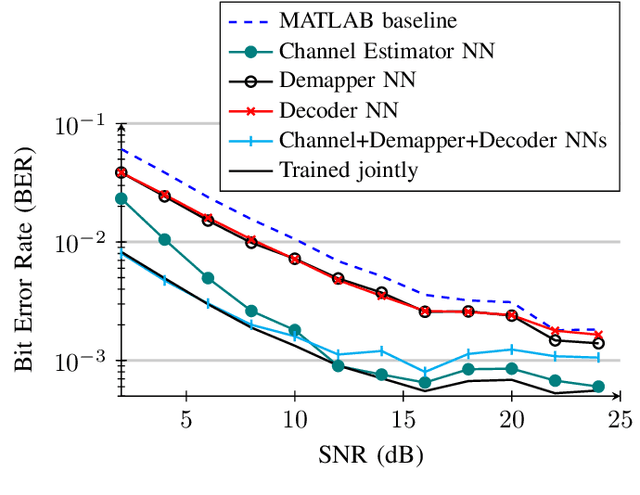
Orthogonal Frequency Division Multiplexing (OFDM)-based waveforms are used for communication links in many current and emerging Internet of Things (IoT) applications, including the latest WiFi standards. For such OFDM-based transceivers, many core physical layer functions related to channel estimation, demapping, and decoding are implemented for specific choices of channel types and modulation schemes, among others. To decouple hard-wired choices from the receiver chain and thereby enhance the flexibility of IoT deployment in many novel scenarios without changing the underlying hardware, we explore a novel, modular Machine Learning (ML)-based receiver chain design. Here, ML blocks replace the individual processing blocks of an OFDM receiver, and we specifically describe this swapping for the legacy channel estimation, symbol demapping, and decoding blocks with Neural Networks (NNs). A unique aspect of this modular design is providing flexible allocation of processing functions to the legacy or ML blocks, allowing them to interchangeably coexist. Furthermore, we study the implementation cost-benefits of the proposed NNs in resource-constrained IoT devices through pruning and quantization, as well as emulation of these compressed NNs within Field Programmable Gate Arrays (FPGAs). Our evaluations demonstrate that the proposed modular NN-based receiver improves bit error rate of the traditional non-ML receiver by averagely 61% and 10% for the simulated and over-the-air datasets, respectively. We further show complexity-performance tradeoffs by presenting computational complexity comparisons between the traditional algorithms and the proposed compressed NNs.
PRONTO: Preamble Overhead Reduction with Neural Networks for Coarse Synchronization
Dec 20, 2021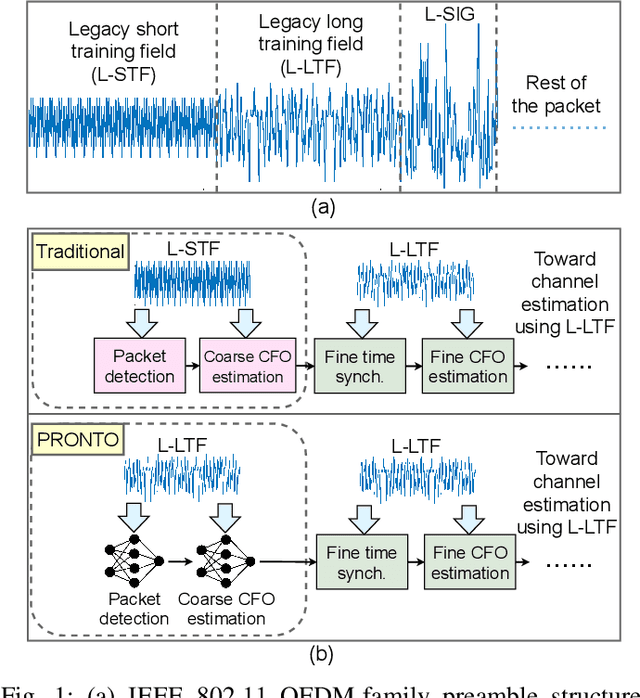
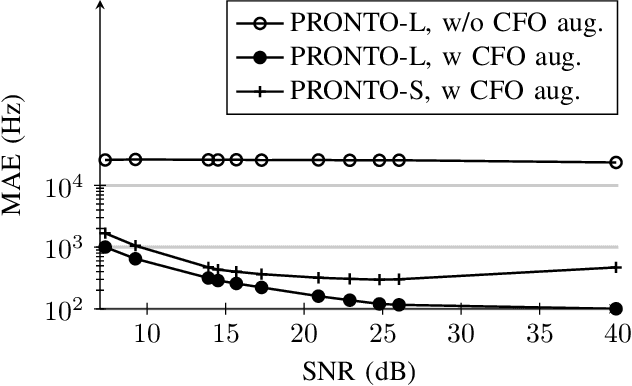
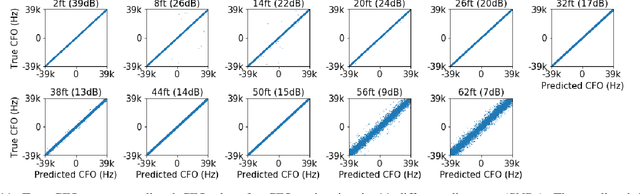
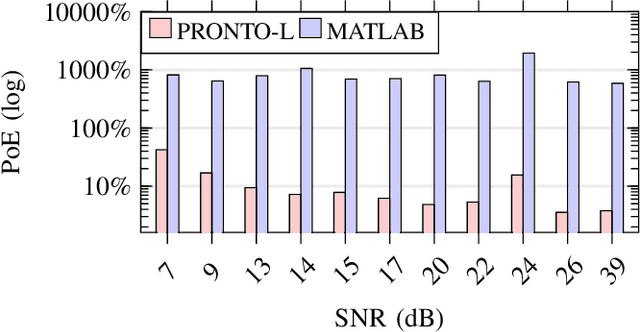
In IEEE 802.11 WiFi-based waveforms, the receiver performs coarse time and frequency synchronization using the first field of the preamble known as the legacy short training field (L-STF). The L-STF occupies upto 40% of the preamble length and takes upto 32 us of airtime. With the goal of reducing communication overhead, we propose a modified waveform, where the preamble length is reduced by eliminating the L-STF. To decode this modified waveform, we propose a machine learning (ML)-based scheme called PRONTO that performs coarse time and frequency estimations using other preamble fields, specifically the legacy long training field (L-LTF). Our contributions are threefold: (i) We present PRONTO featuring customized convolutional neural networks (CNNs) for packet detection and coarse CFO estimation, along with data augmentation steps for robust training. (ii) We propose a generalized decision flow that makes PRONTO compatible with legacy waveforms that include the standard L-STF. (iii) We validate the outcomes on an over-the-air WiFi dataset from a testbed of software defined radios (SDRs). Our evaluations show that PRONTO can perform packet detection with 100% accuracy, and coarse CFO estimation with errors as small as 3%. We demonstrate that PRONTO provides upto 40% preamble length reduction with no bit error rate (BER) degradation. Finally, we experimentally show the speedup achieved by PRONTO through GPU parallelization over the corresponding CPU-only implementations.