 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Recursive Fusion of Multiresolution Multispectral Images with Location-Aware Neural Networks
Jun 16, 2025Multiresolution image fusion is a key problem for real-time satellite imaging and plays a central role in detecting and monitoring natural phenomena such as floods. It aims to solve the trade-off between temporal and spatial resolution in remote sensing instruments. Although several algorithms have been proposed for this problem, the presence of outliers such as clouds downgrades their performance. Moreover, strategies that integrate robustness, recursive operation and learned models are missing. In this paper, a robust recursive image fusion framework leveraging location-aware neural networks (NN) to model the image dynamics is proposed. Outliers are modeled by representing the probability of contamination of a given pixel and band. A NN model trained on a small dataset provides accurate predictions of the stochastic image time evolution, which improves both the accuracy and robustness of the method. A recursive solution is proposed to estimate the high-resolution images using a Bayesian variational inference framework. Experiments fusing images from the Landsat 8 and MODIS instruments show that the proposed approach is significantly more robust against cloud cover, without losing performance when no clouds are present.
Mitigate Target-level Insensitivity of Infrared Small Target Detection via Posterior Distribution Modeling
Mar 13, 2024



Infrared Small Target Detection (IRSTD) aims to segment small targets from infrared clutter background. Existing methods mainly focus on discriminative approaches, i.e., a pixel-level front-background binary segmentation. Since infrared small targets are small and low signal-to-clutter ratio, empirical risk has few disturbances when a certain false alarm and missed detection exist, which seriously affect the further improvement of such methods. Motivated by the dense prediction generative methods, in this paper, we propose a diffusion model framework for Infrared Small Target Detection which compensates pixel-level discriminant with mask posterior distribution modeling. Furthermore, we design a Low-frequency Isolation in the wavelet domain to suppress the interference of intrinsic infrared noise on the diffusion noise estimation. This transition from the discriminative paradigm to generative one enables us to bypass the target-level insensitivity. Experiments show that the proposed method achieves competitive performance gains over state-of-the-art methods on NUAA-SIRST, IRSTD-1k, and NUDT-SIRST datasets. Code are available at https://github.com/Li-Haoqing/IRSTD-Diff.
Click on Mask: A Labor-efficient Annotation Framework with Level Set for Infrared Small Target Detection
Oct 19, 2023



Infrared Small Target Detection is a challenging task to separate small targets from infrared clutter background. Recently, deep learning paradigms have achieved promising results. However, these data-driven methods need plenty of manual annotation. Due to the small size of infrared targets, manual annotation consumes more resources and restricts the development of this field. This letter proposed a labor-efficient and cursory annotation framework with level set, which obtains a high-quality pseudo mask with only one cursory click. A variational level set formulation with an expectation difference energy functional is designed, in which the zero level contour is intrinsically maintained during the level set evolution. It solves the issue that zero level contour disappearing due to small target size and excessive regularization. Experiments on the NUAA-SIRST and IRSTD-1k datasets reveal that our approach achieves superior performance. Code is available at https://github.com/Li-Haoqing/COM.
ILNet: Low-level Matters for Salient Infrared Small Target Detection
Sep 24, 2023



Infrared small target detection is a technique for finding small targets from infrared clutter background. Due to the dearth of high-level semantic information, small infrared target features are weakened in the deep layers of the CNN, which underachieves the CNN's representation ability. To address the above problem, in this paper, we propose an infrared low-level network (ILNet) that considers infrared small targets as salient areas with little semantic information. Unlike other SOTA methods, ILNet pays greater attention to low-level information instead of treating them equally. A new lightweight feature fusion module, named Interactive Polarized Orthogonal Fusion module (IPOF), is proposed, which integrates more important low-level features from the shallow layers into the deep layers. A Dynamic One-Dimensional Aggregation layers (DODA) are inserted into the IPOF, to dynamically adjust the aggregation of low dimensional information according to the number of input channels. In addition, the idea of ensemble learning is used to design a Representative Block (RB) to dynamically allocate weights for shallow and deep layers. Experimental results on the challenging NUAA-SIRST (78.22% nIoU and 1.33e-6 Fa) and IRSTD-1K (68.91% nIoU and 3.23e-6 Fa) dataset demonstrate that the proposed ILNet can get better performances than other SOTA methods. Moreover, ILNet can obtain a greater improvement with the increasement of data volume. Training code are available at https://github.com/Li-Haoqing/ILNet.
Robust Interference Mitigation techniques for Direct Position Estimation
Aug 09, 2023Global Navigation Satellite System (GNSS) is pervasive in navigation and positioning applications, where precise position and time referencing estimations are required. Conventional methods for GNSS positioning involve a two-step process, where intermediate measurements such as Doppler shift and time delay of received GNSS signals are computed and then used to solve for the receiver's position. Alternatively, Direct Position Estimation (DPE) was proposed to infer the position directly from the sampled signal without intermediate variables, yielding to superior levels of sensitivity and operation under challenging environments. However, the positioning resilience of DPE method is still under the threat of various interferences. Robust Interference Mitigation (RIM) processing has been studied and proved to be efficient against various interference in conventional two-step positioning (2SP) methods, and therefore worthy to be explored regarding its potential to enhance DPE. This article extends DPE methodology by incorporating RIM strategies that address the increasing need to protect GNSS receivers against intentional or unintentional interferences, such as jamming signals, which can deny GNSS-based positioning. RIM, which leverages robust statistics, was shown to provide competitive results in two-step approaches and is here employed in a high-sensitivity DPE framework with successful results. The article also provides a quantification of the loss of efficiency of using RIM when no interference is present and validates the proposed methodology on relevant interference cases, while the approach can be used to mitigate other common interference signals.
Online Fusion of Multi-resolution Multispectral Images with Weakly Supervised Temporal Dynamics
Jan 06, 2023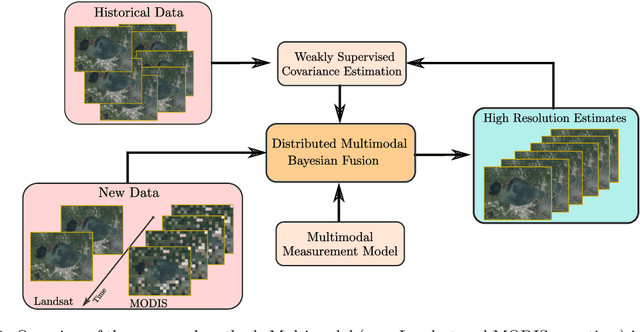
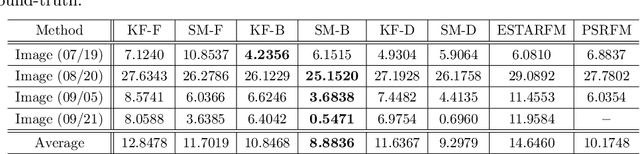
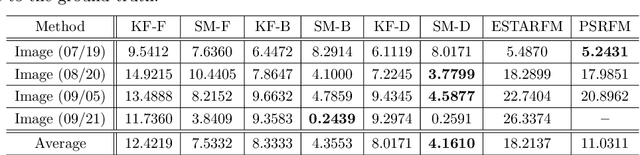
Real-time satellite imaging has a central role in monitoring, detecting and estimating the intensity of key natural phenomena such as floods, earthquakes, etc. One important constraint of satellite imaging is the trade-off between spatial/spectral resolution and their revisiting time, a consequence of design and physical constraints imposed by satellite orbit among other technical limitations. In this paper, we focus on fusing multi-temporal, multi-spectral images where data acquired from different instruments with different spatial resolutions is used. We leverage the spatial relationship between images at multiple modalities to generate high-resolution image sequences at higher revisiting rates. To achieve this goal, we formulate the fusion method as a recursive state estimation problem and study its performance in filtering and smoothing contexts. Furthermore, a calibration strategy is proposed to estimate the time-varying temporal dynamics of the image sequence using only a small amount of historical image data. Differently from the training process in traditional machine learning algorithms, which usually require large datasets and computation times, the parameters of the temporal dynamical model are calibrated based on an analytical expression that uses only two of the images in the historical dataset. A distributed version of the Bayesian filtering and smoothing strategies is also proposed to reduce its computational complexity. To evaluate the proposed methodology we consider a water mapping task where real data acquired by the Landsat and MODIS instruments are fused generating high spatial-temporal resolution image estimates. Our experiments show that the proposed methodology outperforms the competing methods in both estimation accuracy and water mapping tasks.
Recursive classification of satellite imaging time-series: An application to water and land cover mapping
Jan 04, 2023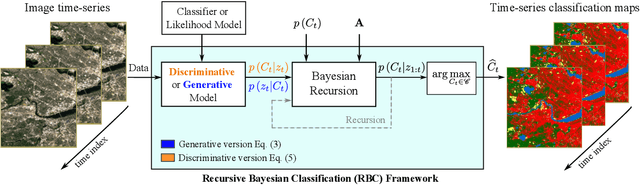
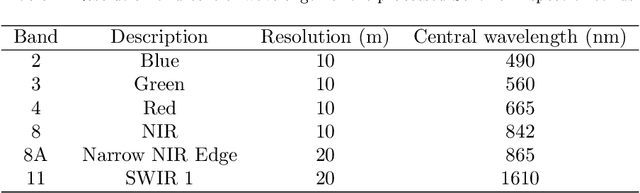
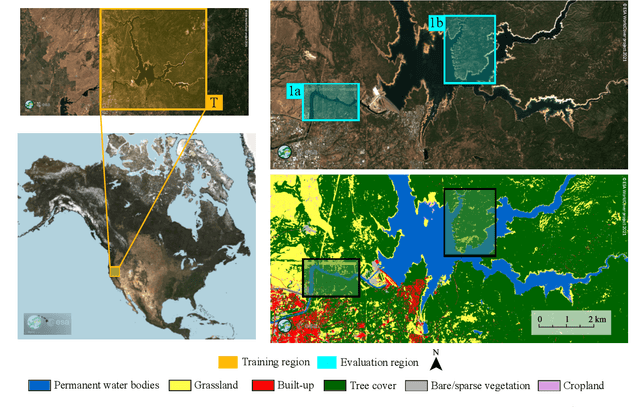
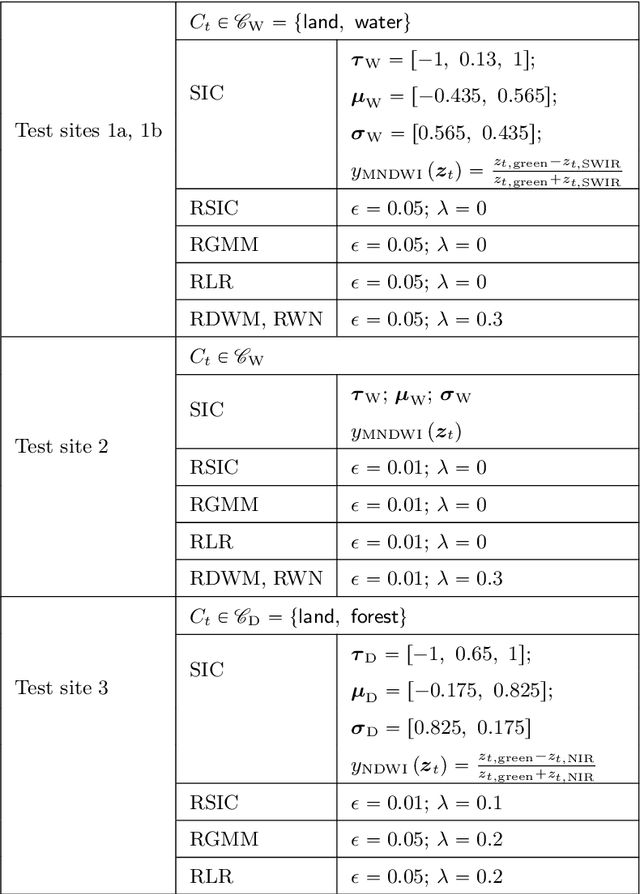
A wide variety of applications of fundamental importance for security, environmental protection and urban development need access to accurate land cover monitoring and water mapping, for which the analysis of optical remote sensing imagery is key. Classification of time-series images, particularly with recursive methods, is of increasing interest in the current literature. Nevertheless, existing recursive approaches typically require large amounts of training data. This paper introduces a recursive classification framework that provides high accuracy while requiring low computational cost and minimal supervision. The proposed approach transforms a static classifier into a recursive one using a probabilistic framework that is robust to non-informative image variations. A water mapping and a land cover experiment are conducted analyzing Sentinel-2 satellite data covering two areas in the United States. The performance of three static classification algorithms and their recursive versions is compared, including a Gaussian Mixture Model (GMM), Logistic Regression (LR) and Spectral Index Classifiers (SICs). SICs consist in a new approach that we introduce to convert the Modified Normalized Difference Water Index (MNDWI) and the Normalized Difference Vegetation Index (NDVI) into probabilistic classification results. Two state-of-the-art deep learning-based classifiers are also used as benchmark models. Results show that the proposed method significantly increases the robustness of existing static classifiers in multitemporal settings. Our method also improves the performance of deep learning-based classifiers without the need of additional training data.
Neural Network-based OFDM Receiver for Resource Constrained IoT Devices
May 12, 2022
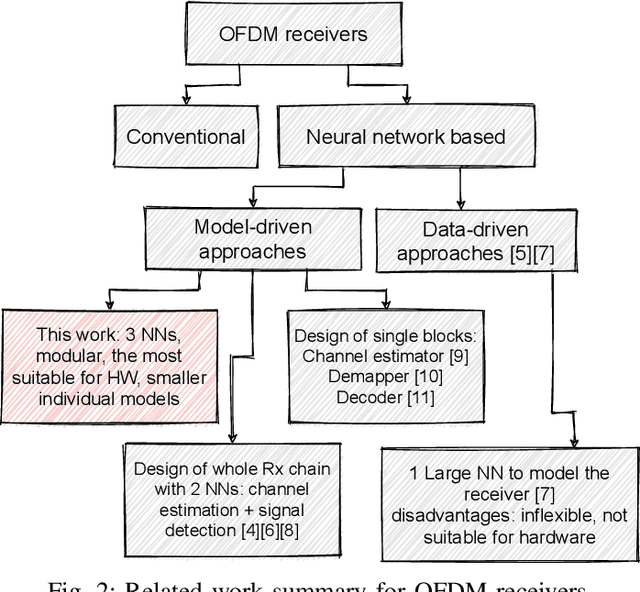
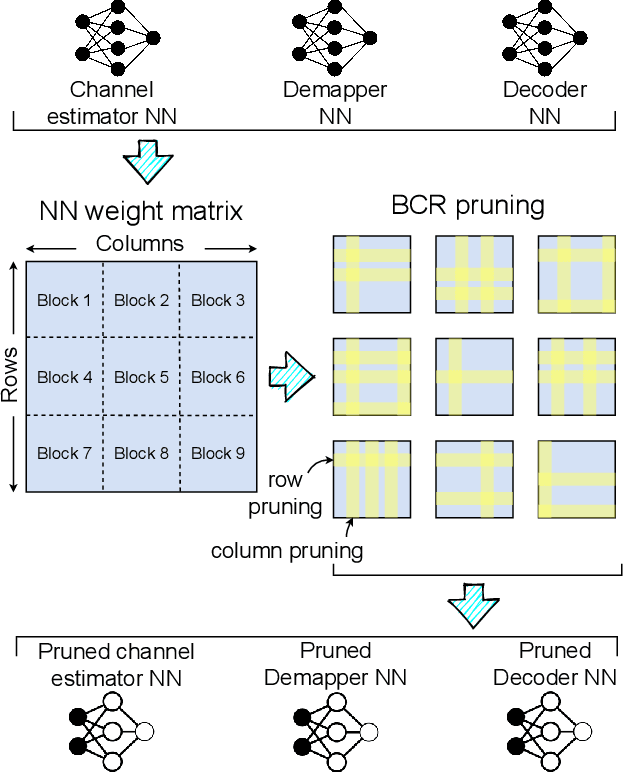
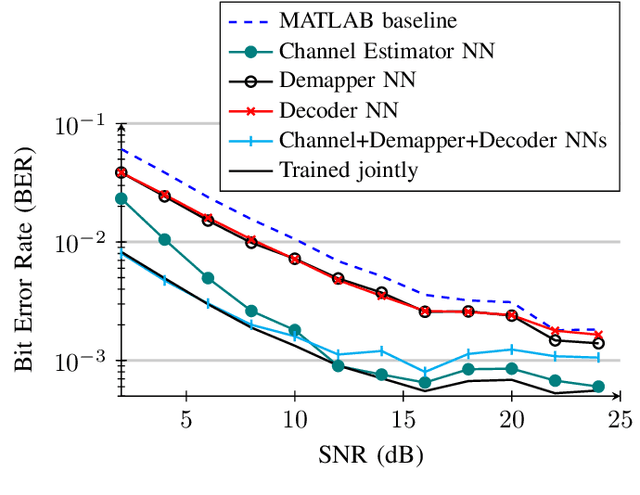
Orthogonal Frequency Division Multiplexing (OFDM)-based waveforms are used for communication links in many current and emerging Internet of Things (IoT) applications, including the latest WiFi standards. For such OFDM-based transceivers, many core physical layer functions related to channel estimation, demapping, and decoding are implemented for specific choices of channel types and modulation schemes, among others. To decouple hard-wired choices from the receiver chain and thereby enhance the flexibility of IoT deployment in many novel scenarios without changing the underlying hardware, we explore a novel, modular Machine Learning (ML)-based receiver chain design. Here, ML blocks replace the individual processing blocks of an OFDM receiver, and we specifically describe this swapping for the legacy channel estimation, symbol demapping, and decoding blocks with Neural Networks (NNs). A unique aspect of this modular design is providing flexible allocation of processing functions to the legacy or ML blocks, allowing them to interchangeably coexist. Furthermore, we study the implementation cost-benefits of the proposed NNs in resource-constrained IoT devices through pruning and quantization, as well as emulation of these compressed NNs within Field Programmable Gate Arrays (FPGAs). Our evaluations demonstrate that the proposed modular NN-based receiver improves bit error rate of the traditional non-ML receiver by averagely 61% and 10% for the simulated and over-the-air datasets, respectively. We further show complexity-performance tradeoffs by presenting computational complexity comparisons between the traditional algorithms and the proposed compressed NNs.
Online multi-resolution fusion of space-borne multispectral images
Apr 26, 2022
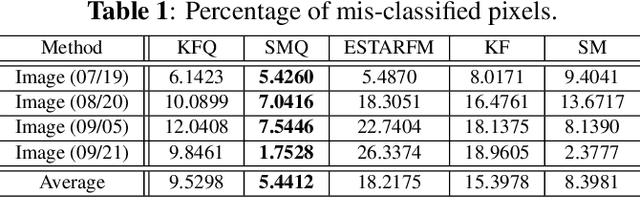
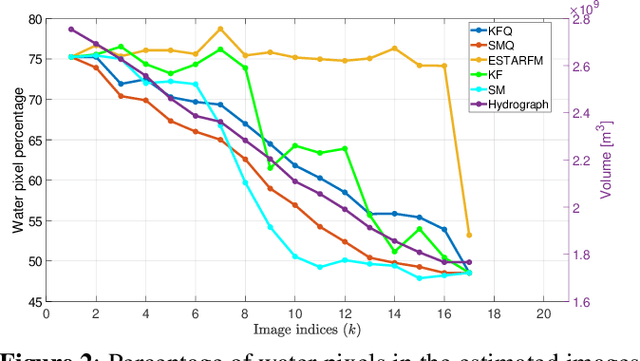
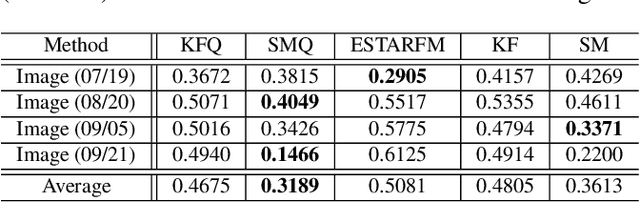
Satellite imaging has a central role in monitoring, detecting and estimating the intensity of key natural phenomena. One important feature of satellite images is the trade-off between spatial/spectral resolution and their revisiting time, a consequence of design and physical constraints imposed by satellite orbit among other technical limitations. In this paper, we focus on fusing multi-temporal, multi-spectral images where data acquired from different instruments with different spatial resolutions is used. We leverage the spatial relationship between images at multiple modalities to generate high-resolution image sequences at higher revisiting rates. To achieve this goal, we formulate the fusion method as a recursive state estimation problem and study its performance in filtering and smoothing contexts. The proposed strategy clearly outperforms competing methodologies, which is shown in the paper for real data acquired by the Landsat and MODIS instruments.
Model-Based Deep Autoencoder Networks for Nonlinear Hyperspectral Unmixing
Apr 17, 2021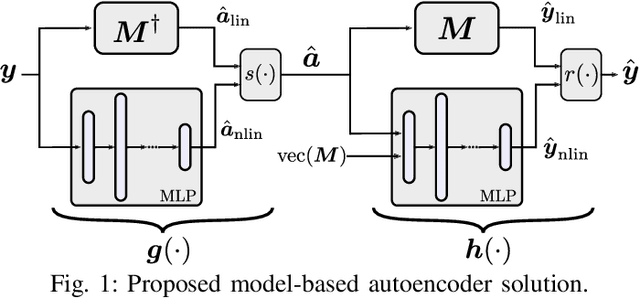
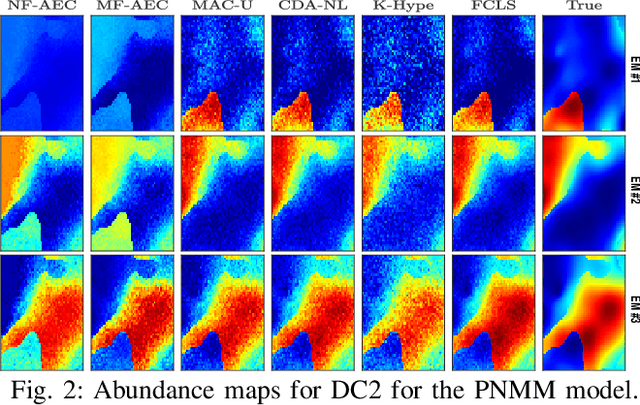
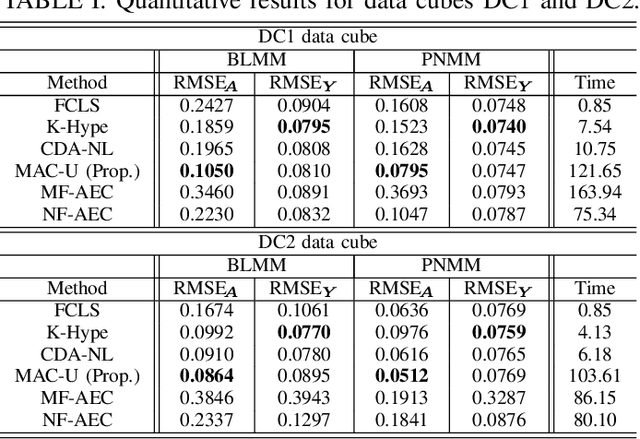
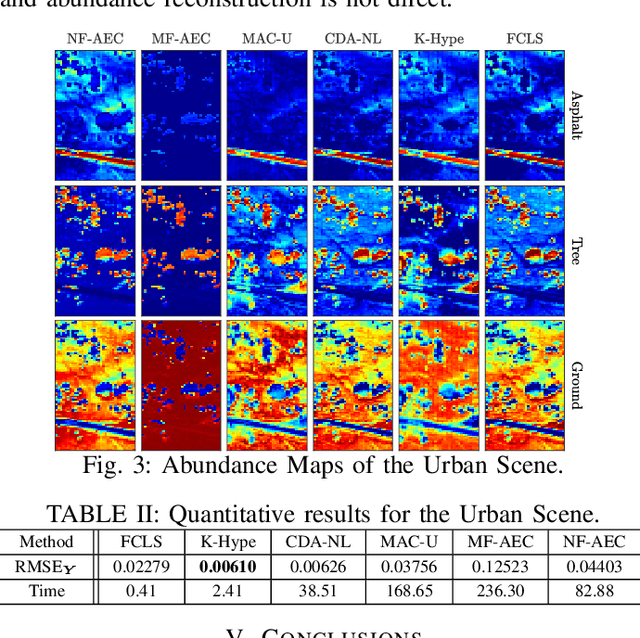
Autoencoder (AEC) networks have recently emerged as a promising approach to perform unsupervised hyperspectral unmixing (HU) by associating the latent representations with the abundances, the decoder with the mixing model and the encoder with its inverse. AECs are especially appealing for nonlinear HU since they lead to unsupervised and model-free algorithms. However, existing approaches fail to explore the fact that the encoder should invert the mixing process, which might reduce their robustness. In this paper, we propose a model-based AEC for nonlinear HU by considering the mixing model a nonlinear fluctuation over a linear mixture. Differently from previous works, we show that this restriction naturally imposes a particular structure to both the encoder and to the decoder networks. This introduces prior information in the AEC without reducing the flexibility of the mixing model. Simulations with synthetic and real data indicate that the proposed strategy improves nonlinear HU.