 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Dialogue State Tracking for Playing GuessWhich Game
Aug 15, 2024GuessWhich is an engaging visual dialogue game that involves interaction between a Questioner Bot (QBot) and an Answer Bot (ABot) in the context of image-guessing. In this game, QBot's objective is to locate a concealed image solely through a series of visually related questions posed to ABot. However, effectively modeling visually related reasoning in QBot's decision-making process poses a significant challenge. Current approaches either lack visual information or rely on a single real image sampled at each round as decoding context, both of which are inadequate for visual reasoning. To address this limitation, we propose a novel approach that focuses on visually related reasoning through the use of a mental model of the undisclosed image. Within this framework, QBot learns to represent mental imagery, enabling robust visual reasoning by tracking the dialogue state. The dialogue state comprises a collection of representations of mental imagery, as well as representations of the entities involved in the conversation. At each round, QBot engages in visually related reasoning using the dialogue state to construct an internal representation, generate relevant questions, and update both the dialogue state and internal representation upon receiving an answer. Our experimental results on the VisDial datasets (v0.5, 0.9, and 1.0) demonstrate the effectiveness of our proposed model, as it achieves new state-of-the-art performance across all metrics and datasets, surpassing previous state-of-the-art models. Codes and datasets from our experiments are freely available at \href{https://github.com/xubuvd/GuessWhich}.
Enhancing Visual Dialog State Tracking through Iterative Object-Entity Alignment in Multi-Round Conversations
Aug 13, 2024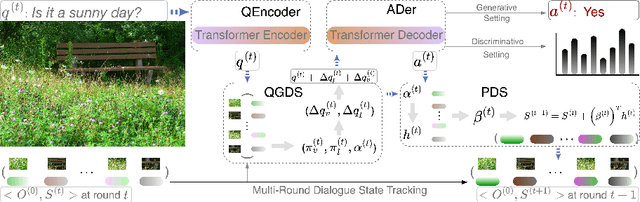
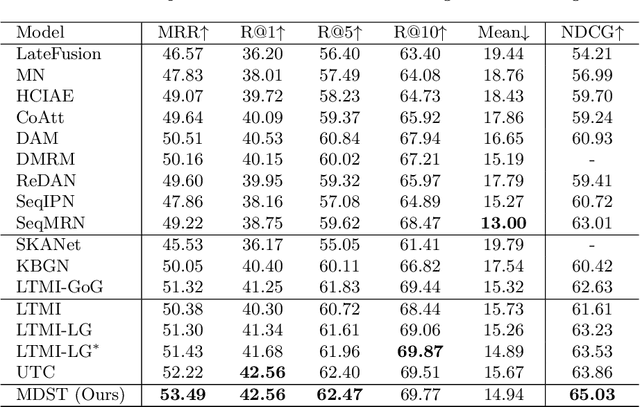
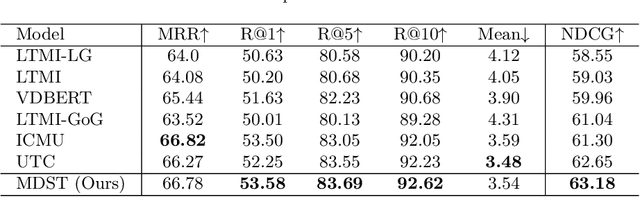
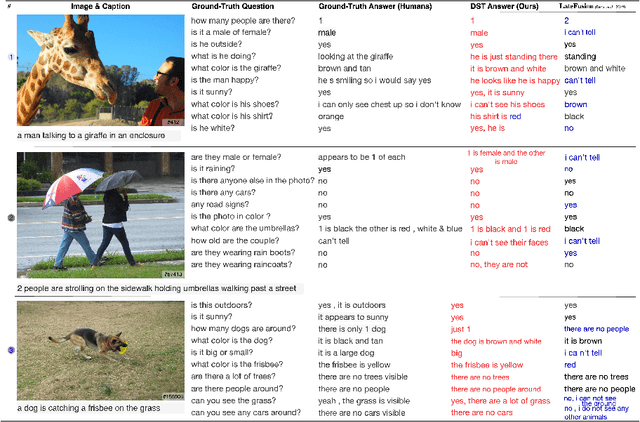
Visual Dialog (VD) is a task where an agent answers a series of image-related questions based on a multi-round dialog history. However, previous VD methods often treat the entire dialog history as a simple text input, disregarding the inherent conversational information flows at the round level. In this paper, we introduce Multi-round Dialogue State Tracking model (MDST), a framework that addresses this limitation by leveraging the dialogue state learned from dialog history to answer questions. MDST captures each round of dialog history, constructing internal dialogue state representations defined as 2-tuples of vision-language representations. These representations effectively ground the current question, enabling the generation of accurate answers. Experimental results on the VisDial v1.0 dataset demonstrate that MDST achieves a new state-of-the-art performance in generative setting. Furthermore, through a series of human studies, we validate the effectiveness of MDST in generating long, consistent, and human-like answers while consistently answering a series of questions correctly.
Mitigate Target-level Insensitivity of Infrared Small Target Detection via Posterior Distribution Modeling
Mar 13, 2024



Infrared Small Target Detection (IRSTD) aims to segment small targets from infrared clutter background. Existing methods mainly focus on discriminative approaches, i.e., a pixel-level front-background binary segmentation. Since infrared small targets are small and low signal-to-clutter ratio, empirical risk has few disturbances when a certain false alarm and missed detection exist, which seriously affect the further improvement of such methods. Motivated by the dense prediction generative methods, in this paper, we propose a diffusion model framework for Infrared Small Target Detection which compensates pixel-level discriminant with mask posterior distribution modeling. Furthermore, we design a Low-frequency Isolation in the wavelet domain to suppress the interference of intrinsic infrared noise on the diffusion noise estimation. This transition from the discriminative paradigm to generative one enables us to bypass the target-level insensitivity. Experiments show that the proposed method achieves competitive performance gains over state-of-the-art methods on NUAA-SIRST, IRSTD-1k, and NUDT-SIRST datasets. Code are available at https://github.com/Li-Haoqing/IRSTD-Diff.
Click on Mask: A Labor-efficient Annotation Framework with Level Set for Infrared Small Target Detection
Oct 19, 2023



Infrared Small Target Detection is a challenging task to separate small targets from infrared clutter background. Recently, deep learning paradigms have achieved promising results. However, these data-driven methods need plenty of manual annotation. Due to the small size of infrared targets, manual annotation consumes more resources and restricts the development of this field. This letter proposed a labor-efficient and cursory annotation framework with level set, which obtains a high-quality pseudo mask with only one cursory click. A variational level set formulation with an expectation difference energy functional is designed, in which the zero level contour is intrinsically maintained during the level set evolution. It solves the issue that zero level contour disappearing due to small target size and excessive regularization. Experiments on the NUAA-SIRST and IRSTD-1k datasets reveal that our approach achieves superior performance. Code is available at https://github.com/Li-Haoqing/COM.
ILNet: Low-level Matters for Salient Infrared Small Target Detection
Sep 24, 2023



Infrared small target detection is a technique for finding small targets from infrared clutter background. Due to the dearth of high-level semantic information, small infrared target features are weakened in the deep layers of the CNN, which underachieves the CNN's representation ability. To address the above problem, in this paper, we propose an infrared low-level network (ILNet) that considers infrared small targets as salient areas with little semantic information. Unlike other SOTA methods, ILNet pays greater attention to low-level information instead of treating them equally. A new lightweight feature fusion module, named Interactive Polarized Orthogonal Fusion module (IPOF), is proposed, which integrates more important low-level features from the shallow layers into the deep layers. A Dynamic One-Dimensional Aggregation layers (DODA) are inserted into the IPOF, to dynamically adjust the aggregation of low dimensional information according to the number of input channels. In addition, the idea of ensemble learning is used to design a Representative Block (RB) to dynamically allocate weights for shallow and deep layers. Experimental results on the challenging NUAA-SIRST (78.22% nIoU and 1.33e-6 Fa) and IRSTD-1K (68.91% nIoU and 3.23e-6 Fa) dataset demonstrate that the proposed ILNet can get better performances than other SOTA methods. Moreover, ILNet can obtain a greater improvement with the increasement of data volume. Training code are available at https://github.com/Li-Haoqing/ILNet.
Natural Scene Recognition Based on Superpixels and Deep Boltzmann Machines
Jun 24, 2015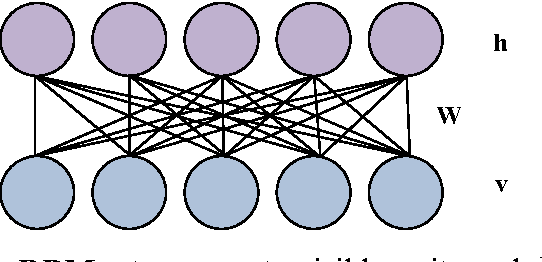
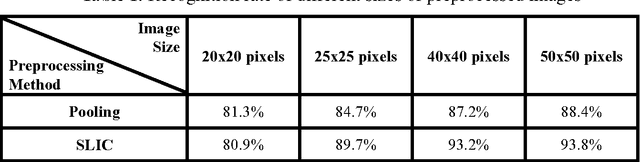

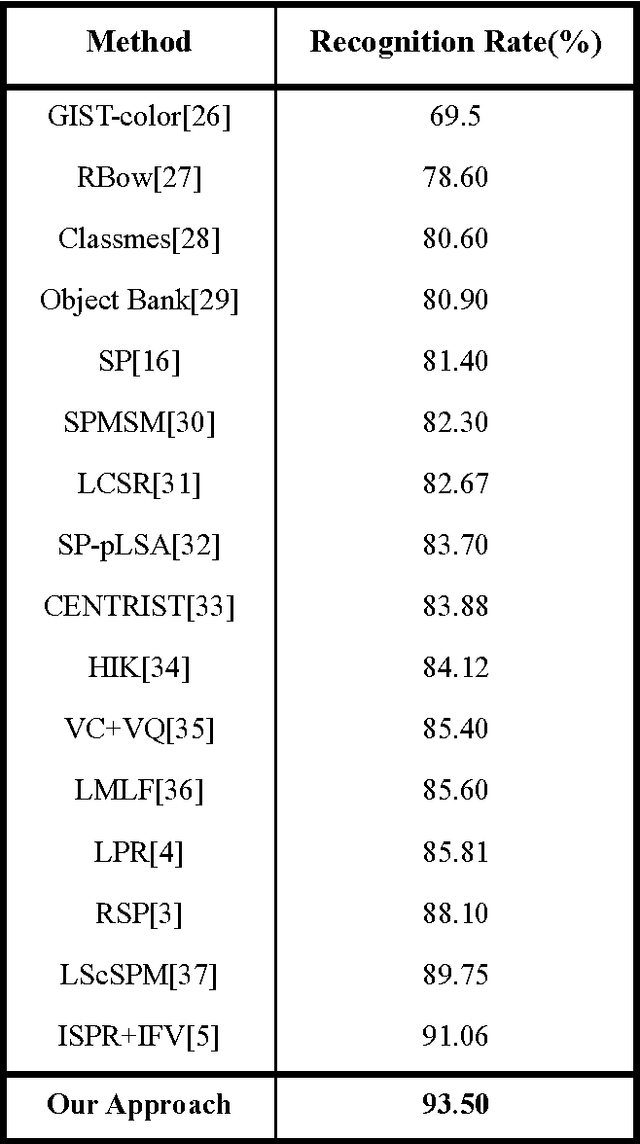
The Deep Boltzmann Machines (DBM) is a state-of-the-art unsupervised learning model, which has been successfully applied to handwritten digit recognition and, as well as object recognition. However, the DBM is limited in scene recognition due to the fact that natural scene images are usually very large. In this paper, an efficient scene recognition approach is proposed based on superpixels and the DBMs. First, a simple linear iterative clustering (SLIC) algorithm is employed to generate superpixels of input images, where each superpixel is regarded as an input of a learning model. Then, a two-layer DBM model is constructed by stacking two restricted Boltzmann machines (RBMs), and a greedy layer-wise algorithm is applied to train the DBM model. Finally, a softmax regression is utilized to categorize scene images. The proposed technique can effectively reduce the computational complexity and enhance the performance for large natural image recognition. The approach is verified and evaluated by extensive experiments, including the fifteen-scene categories dataset the UIUC eight-sports dataset, and the SIFT flow dataset, are used to evaluate the proposed method. The experimental results show that the proposed approach outperforms other state-of-the-art methods in terms of recognition rate.
A Novel Feature Extraction Method for Scene Recognition Based on Centered Convolutional Restricted Boltzmann Machines
Jun 24, 2015
Scene recognition is an important research topic in computer vision, while feature extraction is a key step of object recognition. Although classical Restricted Boltzmann machines (RBM) can efficiently represent complicated data, it is hard to handle large images due to its complexity in computation. In this paper, a novel feature extraction method, named Centered Convolutional Restricted Boltzmann Machines (CCRBM), is proposed for scene recognition. The proposed model is an improved Convolutional Restricted Boltzmann Machines (CRBM) by introducing centered factors in its learning strategy to reduce the source of instabilities. First, the visible units of the network are redefined using centered factors. Then, the hidden units are learned with a modified energy function by utilizing a distribution function, and the visible units are reconstructed using the learned hidden units. In order to achieve better generative ability, the Centered Convolutional Deep Belief Networks (CCDBN) is trained in a greedy layer-wise way. Finally, a softmax regression is incorporated for scene recognition. Extensive experimental evaluations using natural scenes, MIT-indoor scenes, and Caltech 101 datasets show that the proposed approach performs better than other counterparts in terms of stability, generalization, and discrimination. The CCDBN model is more suitable for natural scene image recognition by virtue of convolutional property.