 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Visual Dialog State Tracking through Iterative Object-Entity Alignment in Multi-Round Conversations
Paper and Code
Aug 13, 2024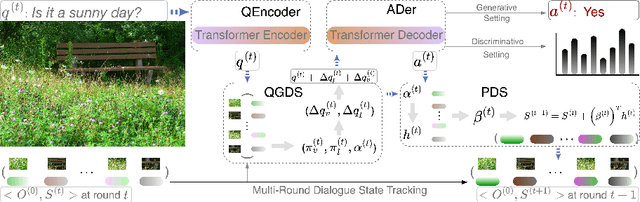
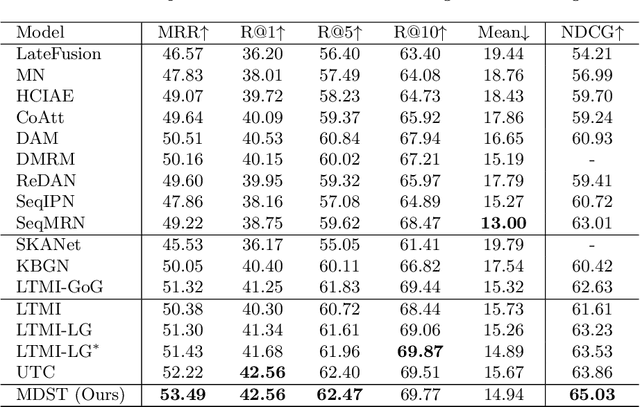
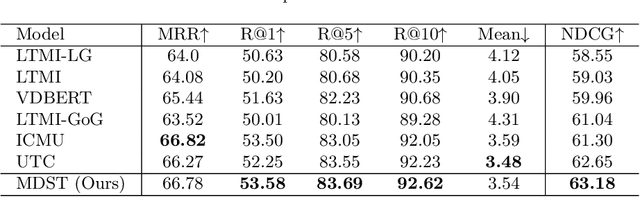
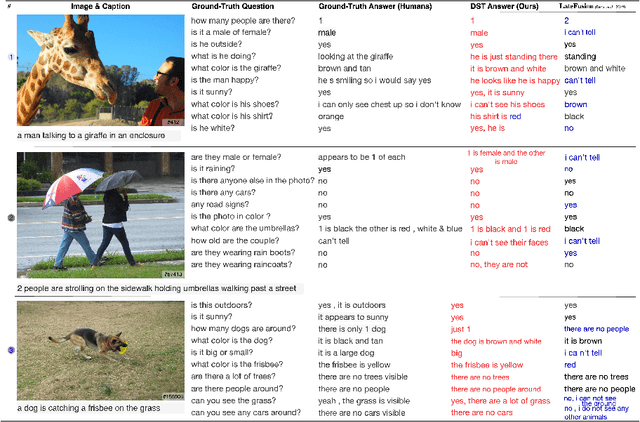
Visual Dialog (VD) is a task where an agent answers a series of image-related questions based on a multi-round dialog history. However, previous VD methods often treat the entire dialog history as a simple text input, disregarding the inherent conversational information flows at the round level. In this paper, we introduce Multi-round Dialogue State Tracking model (MDST), a framework that addresses this limitation by leveraging the dialogue state learned from dialog history to answer questions. MDST captures each round of dialog history, constructing internal dialogue state representations defined as 2-tuples of vision-language representations. These representations effectively ground the current question, enabling the generation of accurate answers. Experimental results on the VisDial v1.0 dataset demonstrate that MDST achieves a new state-of-the-art performance in generative setting. Furthermore, through a series of human studies, we validate the effectiveness of MDST in generating long, consistent, and human-like answers while consistently answering a series of questions correctly.