 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFDECORATOR: Wrapping Instruction Following Reinforcement Learning with Verifiable Rewards
Aug 06, 2025Reinforcement Learning with Verifiable Rewards (RLVR) improves instruction following capabilities of large language models (LLMs), but suffers from training inefficiency due to inadequate difficulty assessment. Moreover, RLVR is prone to over-optimization, where LLMs exploit verification shortcuts without aligning to the actual intent of user instructions. We introduce Instruction Following Decorator (IFDecorator}, a framework that wraps RLVR training into a robust and sample-efficient pipeline. It consists of three components: (1) a cooperative-adversarial data flywheel that co-evolves instructions and hybrid verifications, generating progressively more challenging instruction-verification pairs; (2) IntentCheck, a bypass module enforcing intent alignment; and (3) trip wires, a diagnostic mechanism that detects reward hacking via trap instructions, which trigger and capture shortcut exploitation behaviors. Our Qwen2.5-32B-Instruct-IFDecorator achieves 87.43% accuracy on IFEval, outperforming larger proprietary models such as GPT-4o. Additionally, we demonstrate substantial improvements on FollowBench while preserving general capabilities. Our trip wires show significant reductions in reward hacking rates. We will release models, code, and data for future research.
Pruning Adversarially Robust Neural Networks without Adversarial Examples
Oct 09, 2022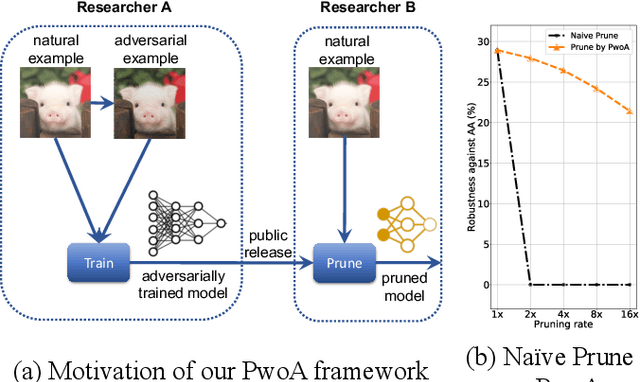
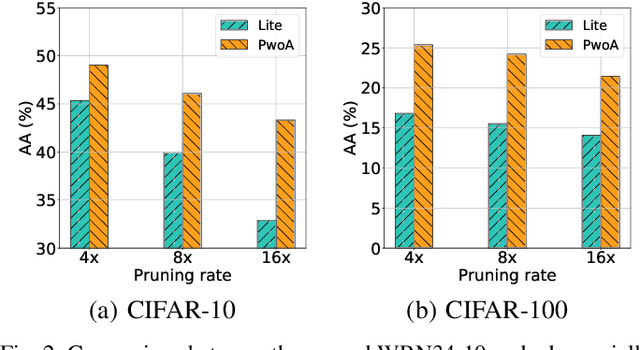
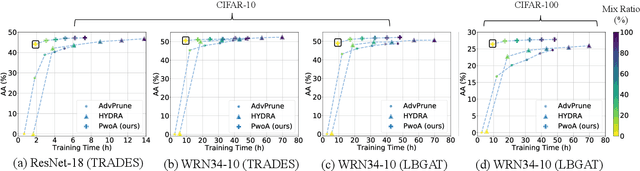
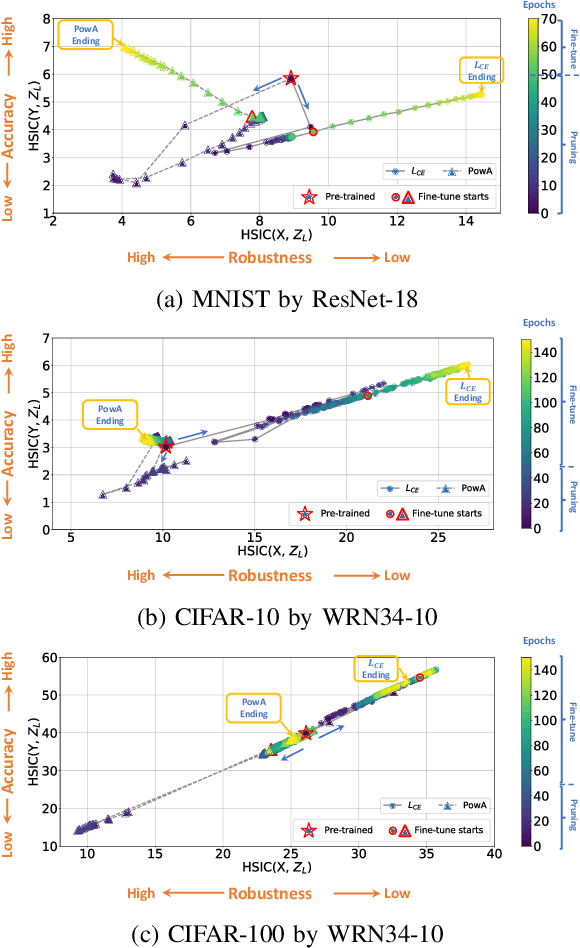
Adversarial pruning compresses models while preserving robustness. Current methods require access to adversarial examples during pruning. This significantly hampers training efficiency. Moreover, as new adversarial attacks and training methods develop at a rapid rate, adversarial pruning methods need to be modified accordingly to keep up. In this work, we propose a novel framework to prune a previously trained robust neural network while maintaining adversarial robustness, without further generating adversarial examples. We leverage concurrent self-distillation and pruning to preserve knowledge in the original model as well as regularizing the pruned model via the Hilbert-Schmidt Information Bottleneck. We comprehensively evaluate our proposed framework and show its superior performance in terms of both adversarial robustness and efficiency when pruning architectures trained on the MNIST, CIFAR-10, and CIFAR-100 datasets against five state-of-the-art attacks. Code is available at https://github.com/neu-spiral/PwoA/.
SparCL: Sparse Continual Learning on the Edge
Sep 20, 2022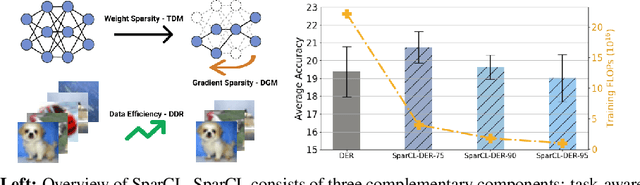
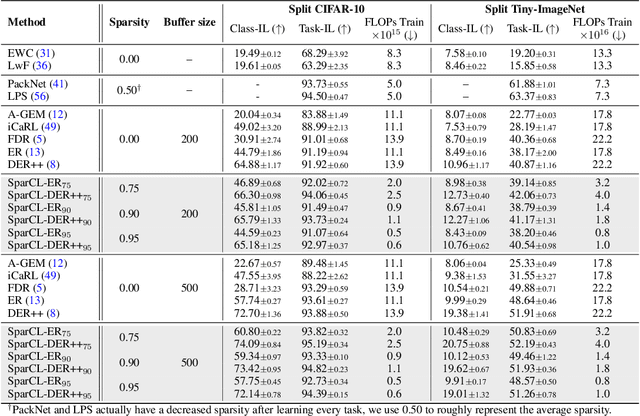
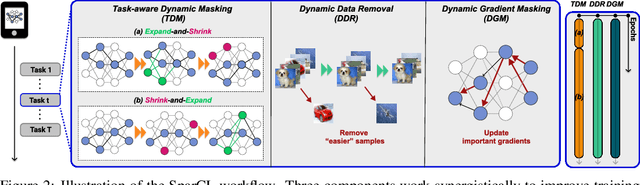
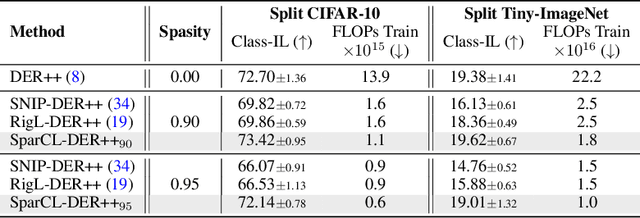
Existing work in continual learning (CL) focuses on mitigating catastrophic forgetting, i.e., model performance deterioration on past tasks when learning a new task. However, the training efficiency of a CL system is under-investigated, which limits the real-world application of CL systems under resource-limited scenarios. In this work, we propose a novel framework called Sparse Continual Learning(SparCL), which is the first study that leverages sparsity to enable cost-effective continual learning on edge devices. SparCL achieves both training acceleration and accuracy preservation through the synergy of three aspects: weight sparsity, data efficiency, and gradient sparsity. Specifically, we propose task-aware dynamic masking (TDM) to learn a sparse network throughout the entire CL process, dynamic data removal (DDR) to remove less informative training data, and dynamic gradient masking (DGM) to sparsify the gradient updates. Each of them not only improves efficiency, but also further mitigates catastrophic forgetting. SparCL consistently improves the training efficiency of existing state-of-the-art (SOTA) CL methods by at most 23X less training FLOPs, and, surprisingly, further improves the SOTA accuracy by at most 1.7%. SparCL also outperforms competitive baselines obtained from adapting SOTA sparse training methods to the CL setting in both efficiency and accuracy. We also evaluate the effectiveness of SparCL on a real mobile phone, further indicating the practical potential of our method.
Deep Learning on Multimodal Sensor Data at the Wireless Edge for Vehicular Network
Jan 12, 2022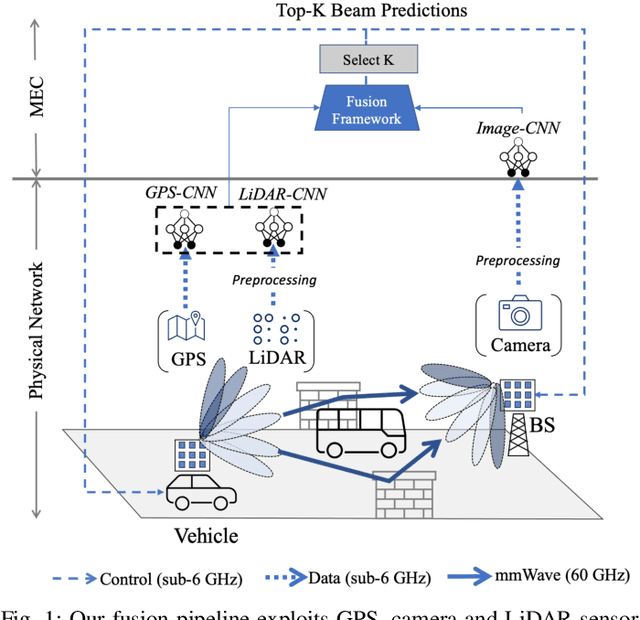

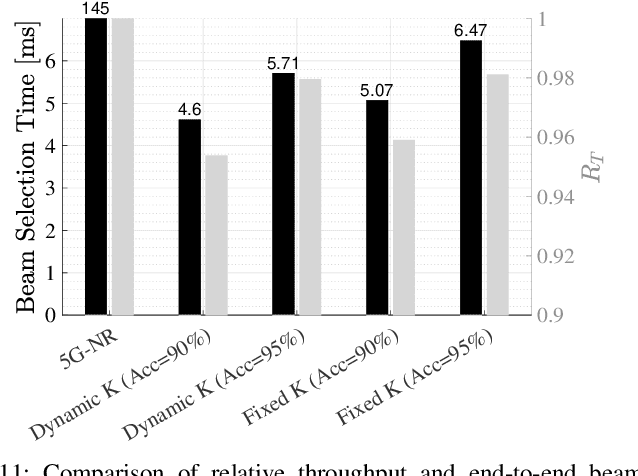
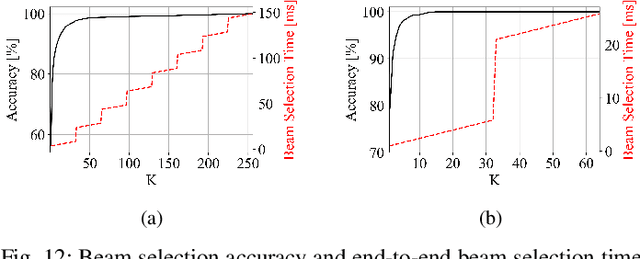
Beam selection for millimeter-wave links in a vehicular scenario is a challenging problem, as an exhaustive search among all candidate beam pairs cannot be assuredly completed within short contact times. We solve this problem via a novel expediting beam selection by leveraging multimodal data collected from sensors like LiDAR, camera images, and GPS. We propose individual modality and distributed fusion-based deep learning (F-DL) architectures that can execute locally as well as at a mobile edge computing center (MEC), with a study on associated tradeoffs. We also formulate and solve an optimization problem that considers practical beam-searching, MEC processing and sensor-to-MEC data delivery latency overheads for determining the output dimensions of the above F-DL architectures. Results from extensive evaluations conducted on publicly available synthetic and home-grown real-world datasets reveal 95% and 96% improvement in beam selection speed over classical RF-only beam sweeping, respectively. F-DL also outperforms the state-of-the-art techniques by 20-22% in predicting top-10 best beam pairs.
Revisiting Hilbert-Schmidt Information Bottleneck for Adversarial Robustness
Jun 04, 2021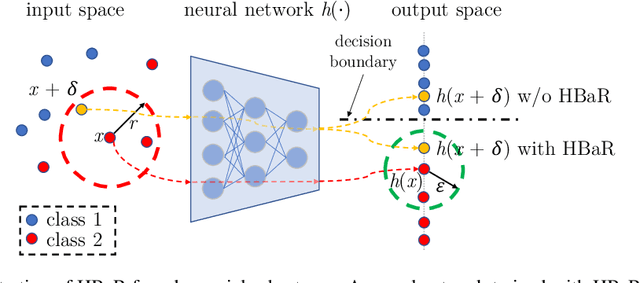
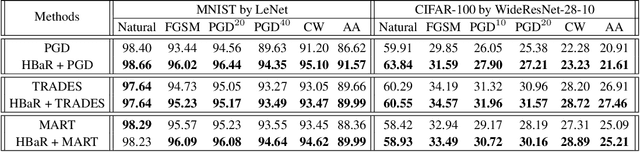
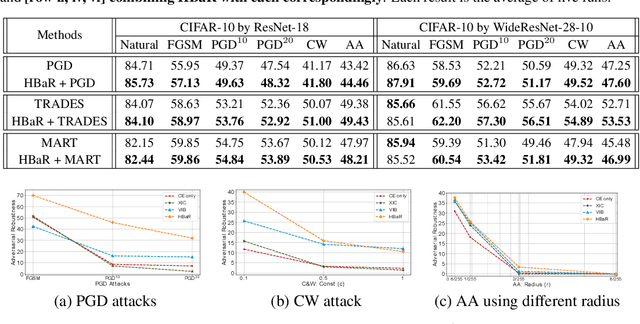
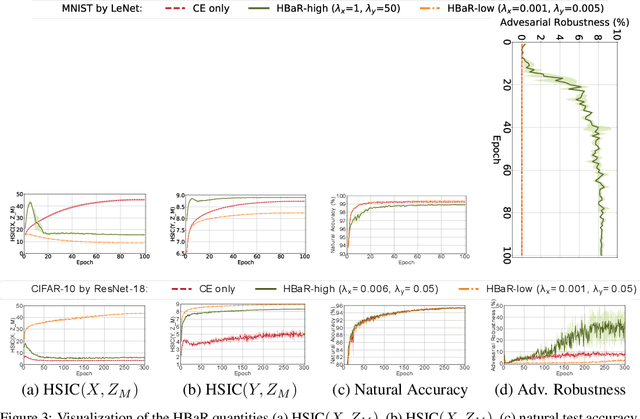
We investigate the HSIC (Hilbert-Schmidt independence criterion) bottleneck as a regularizer for learning an adversarially robust deep neural network classifier. We show that the HSIC bottleneck enhances robustness to adversarial attacks both theoretically and experimentally. Our experiments on multiple benchmark datasets and architectures demonstrate that incorporating an HSIC bottleneck regularizer attains competitive natural accuracy and improves adversarial robustness, both with and without adversarial examples during training.
Learn-Prune-Share for Lifelong Learning
Dec 13, 2020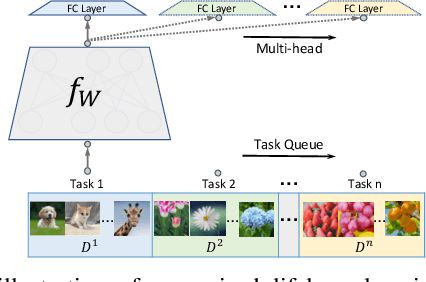
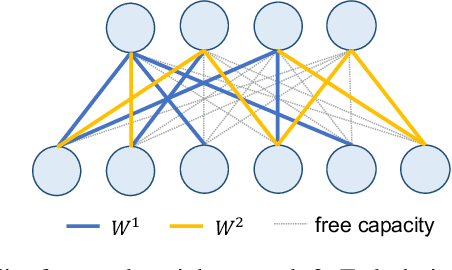
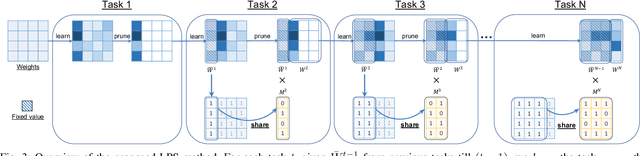
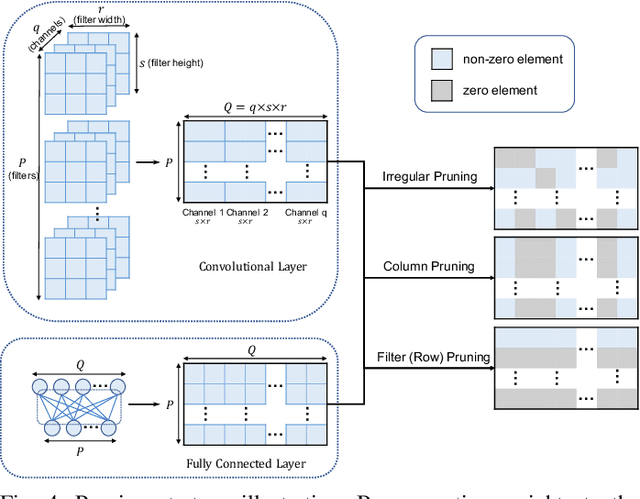
In lifelong learning, we wish to maintain and update a model (e.g., a neural network classifier) in the presence of new classification tasks that arrive sequentially. In this paper, we propose a learn-prune-share (LPS) algorithm which addresses the challenges of catastrophic forgetting, parsimony, and knowledge reuse simultaneously. LPS splits the network into task-specific partitions via an ADMM-based pruning strategy. This leads to no forgetting, while maintaining parsimony. Moreover, LPS integrates a novel selective knowledge sharing scheme into this ADMM optimization framework. This enables adaptive knowledge sharing in an end-to-end fashion. Comprehensive experimental results on two lifelong learning benchmark datasets and a challenging real-world radio frequency fingerprinting dataset are provided to demonstrate the effectiveness of our approach. Our experiments show that LPS consistently outperforms multiple state-of-the-art competitors.