 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAHA: Human-Assisted Out-of-Distribution Generalization and Detection
Paper and Code

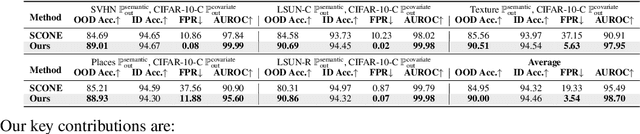

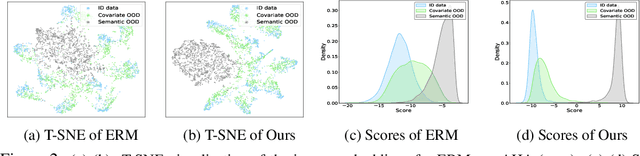
Modern machine learning models deployed often encounter distribution shifts in real-world applications, manifesting as covariate or semantic out-of-distribution (OOD) shifts. These shifts give rise to challenges in OOD generalization and OOD detection. This paper introduces a novel, integrated approach AHA (Adaptive Human-Assisted OOD learning) to simultaneously address both OOD generalization and detection through a human-assisted framework by labeling data in the wild. Our approach strategically labels examples within a novel maximum disambiguation region, where the number of semantic and covariate OOD data roughly equalizes. By labeling within this region, we can maximally disambiguate the two types of OOD data, thereby maximizing the utility of the fixed labeling budget. Our algorithm first utilizes a noisy binary search algorithm that identifies the maximal disambiguation region with high probability. The algorithm then continues with annotating inside the identified labeling region, reaping the full benefit of human feedback. Extensive experiments validate the efficacy of our framework. We observed that with only a few hundred human annotations, our method significantly outperforms existing state-of-the-art methods that do not involve human assistance, in both OOD generalization and OOD detection. Code is publicly available at \url{https://github.com/HaoyueBaiZJU/aha}.