 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIEVE: General Purpose Data Filtering System Matching GPT-4o Accuracy at 1% the Cost
Paper and Code
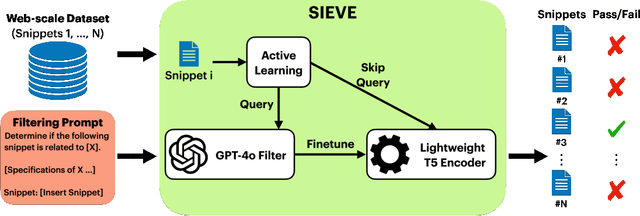
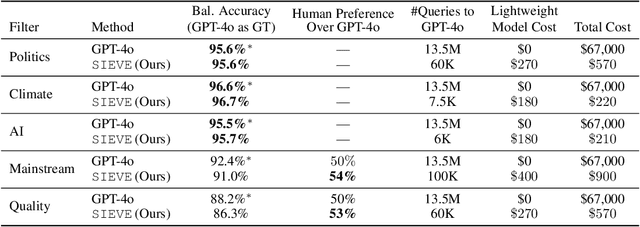
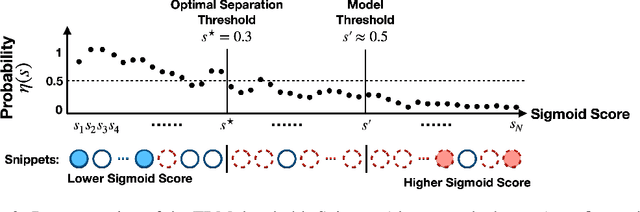
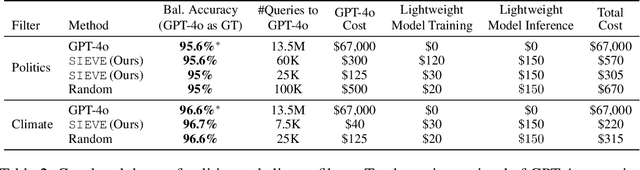
Creating specialized large language models requires vast amounts of clean, special purpose data for training and fine-tuning. With only a handful of existing large-scale, domain-specific datasets, creation of new datasets is required in most applications. This requires the development of new application-specific filtering of web-scale data. Filtering with a high-performance, general-purpose LLM such as GPT-4o can be highly effective, but this is extremely expensive at web-scale. This paper proposes SIEVE, a lightweight alternative that matches GPT-4o accuracy at a fraction of the cost. SIEVE can perform up to 500 filtering operations for the cost of one GPT-4o filtering call. The key to SIEVE is a seamless integration of GPT-4o and lightweight T5 models, using active learning to fine-tune T5 in the background with a small number of calls to GPT-4o. Once trained, it performs as well as GPT-4o at a tiny fraction of the cost. We experimentally validate SIEVE on the OpenWebText dataset, using five highly customized filter tasks targeting high quality and domain-specific content. Our results demonstrate the effectiveness and efficiency of our method in curating large, high-quality datasets for language model training at a substantially lower cost (1%) than existing techniques. To further validate SIEVE, experiments show that SIEVE and GPT-4o achieve similar accuracy, with human evaluators preferring SIEVE's filtering results to those of GPT-4o.