 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Creativity Understanding Gap: Small-Scale Human Alignment Enables Expert-Level Humor Ranking in LLMs
Feb 27, 2025Large Language Models (LLMs) have shown significant limitations in understanding creative content, as demonstrated by Hessel et al. (2023)'s influential work on the New Yorker Cartoon Caption Contest (NYCCC). Their study exposed a substantial gap between LLMs and humans in humor comprehension, establishing that understanding and evaluating creative content is key challenge in AI development. We revisit this challenge by decomposing humor understanding into three components and systematically improve each: enhancing visual understanding through improved annotation, utilizing LLM-generated humor reasoning and explanations, and implementing targeted alignment with human preference data. Our refined approach achieves 82.4% accuracy in caption ranking, singificantly improving upon the previous 67% benchmark and matching the performance of world-renowned human experts in this domain. Notably, while attempts to mimic subgroup preferences through various persona prompts showed minimal impact, model finetuning with crowd preferences proved remarkably effective. These findings reveal that LLM limitations in creative judgment can be effectively addressed through focused alignment to specific subgroups and individuals. Lastly, we propose the position that achieving artificial general intelligence necessitates systematic collection of human preference data across creative domains. We advocate that just as human creativity is deeply influenced by individual and cultural preferences, training LLMs with diverse human preference data may be essential for developing true creative understanding.
Humor in Collective Discourse: Unsupervised Funniness Detection in the New Yorker Cartoon Caption Contest
Jun 26, 2015
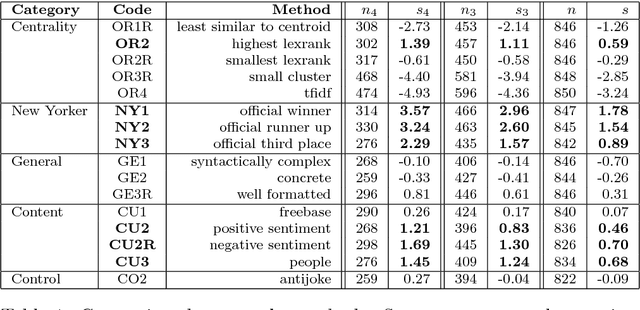


The New Yorker publishes a weekly captionless cartoon. More than 5,000 readers submit captions for it. The editors select three of them and ask the readers to pick the funniest one. We describe an experiment that compares a dozen automatic methods for selecting the funniest caption. We show that negative sentiment, human-centeredness, and lexical centrality most strongly match the funniest captions, followed by positive sentiment. These results are useful for understanding humor and also in the design of more engaging conversational agents in text and multimodal (vision+text) systems. As part of this work, a large set of cartoons and captions is being made available to the community.