 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressivity of Emergent Language is a Trade-off between Contextual Complexity and Unpredictability
Jun 07, 2021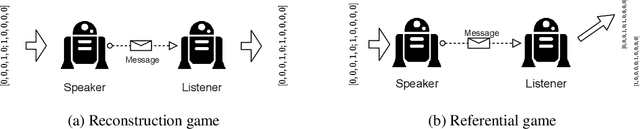

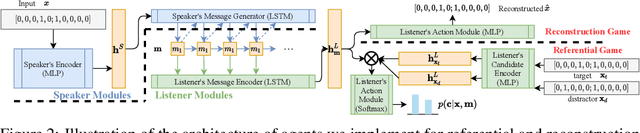

Researchers are now using deep learning models to explore the emergence of language in various language games, where simulated agents interact and develop an emergent language to solve a task. Although it is quite intuitive that different types of language games posing different communicative challenges might require emergent languages which encode different levels of information, there is no existing work exploring the expressivity of the emergent languages. In this work, we propose a definition of partial order between expressivity based on the generalisation performance across different language games. We also validate the hypothesis that expressivity of emergent languages is a trade-off between the complexity and unpredictability of the context those languages are used in. Our second novel contribution is introducing contrastive loss into the implementation of referential games. We show that using our contrastive loss alleviates the collapse of message types seen using standard referential loss functions.
Conceptual similarity and communicative need shape colexification: an experimental study
Mar 19, 2021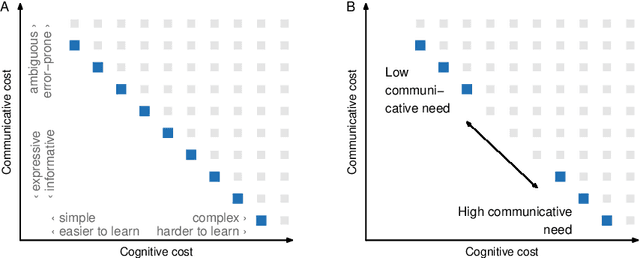
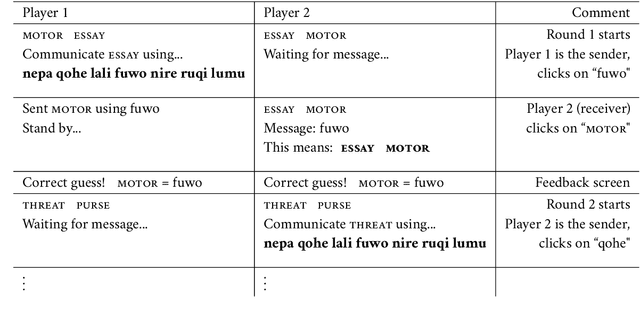
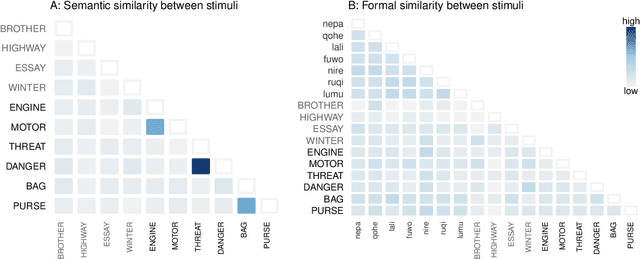

Colexification refers to the phenomenon of multiple meanings sharing one word in a language. Cross-linguistic lexification patterns have been shown to be largely predictable, as similar concepts are often colexified. We test a recent claim that, beyond this general tendency, communicative needs play an important role in shaping colexification patterns. We approach this question by means of a series of human experiments, using an artificial language communication game paradigm. Our results across four experiments match the previous cross-linguistic findings: all other things being equal, speakers do prefer to colexify similar concepts. However, we also find evidence supporting the communicative need hypothesis: when faced with a frequent need to distinguish similar pairs of meanings, speakers adjust their colexification preferences to maintain communicative efficiency, and avoid colexifying those similar meanings which need to be distinguished in communication. This research provides further evidence to support the argument that languages are shaped by the needs and preferences of their speakers.
Communicative need modulates competition in language change
Jun 16, 2020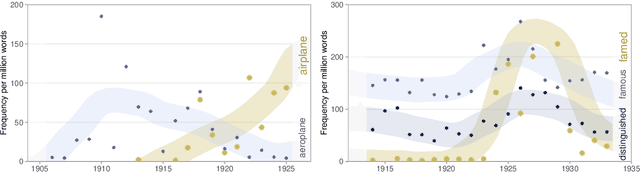
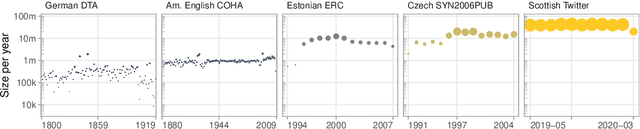
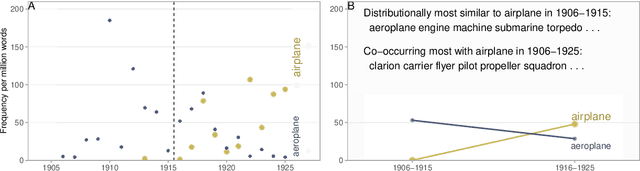
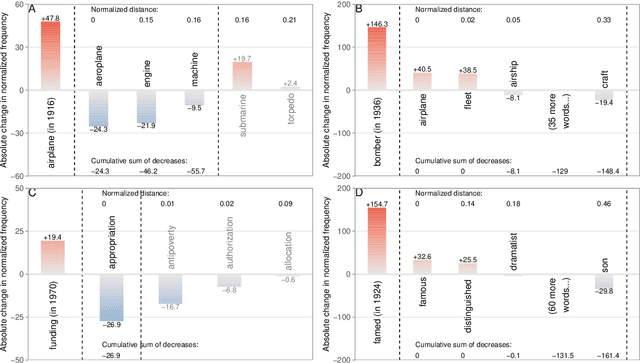
All living languages change over time. The causes for this are many, one being the emergence and borrowing of new linguistic elements. Competition between the new elements and older ones with a similar semantic or grammatical function may lead to speakers preferring one of them, and leaving the other to go out of use. We introduce a general method for quantifying competition between linguistic elements in diachronic corpora which does not require language-specific resources other than a sufficiently large corpus. This approach is readily applicable to a wide range of languages and linguistic subsystems. Here, we apply it to lexical data in five corpora differing in language, type, genre, and time span. We find that changes in communicative need are consistently predictive of lexical competition dynamics. Near-synonymous words are more likely to directly compete if they belong to a topic of conversation whose importance to language users is constant over time, possibly leading to the extinction of one of the competing words. By contrast, in topics which are increasing in importance for language users, near-synonymous words tend not to compete directly and can coexist. This suggests that, in addition to direct competition between words, language change can be driven by competition between topics or semantic subspaces.
Compositional Languages Emerge in a Neural Iterated Learning Model
Feb 17, 2020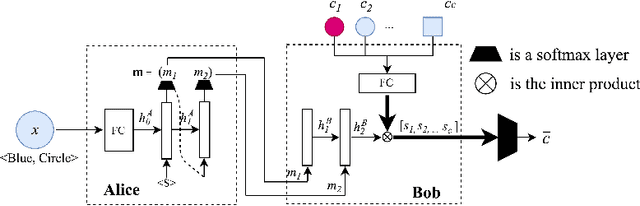
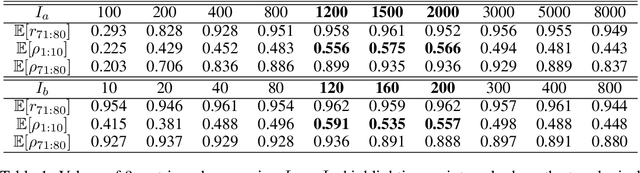
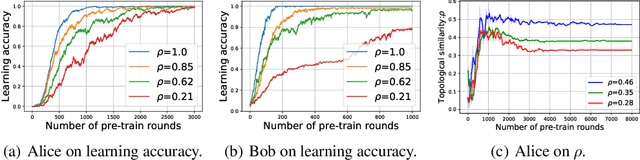
The principle of compositionality, which enables natural language to represent complex concepts via a structured combination of simpler ones, allows us to convey an open-ended set of messages using a limited vocabulary. If compositionality is indeed a natural property of language, we may expect it to appear in communication protocols that are created by neural agents in language games. In this paper, we propose an effective neural iterated learning (NIL) algorithm that, when applied to interacting neural agents, facilitates the emergence of a more structured type of language. Indeed, these languages provide learning speed advantages to neural agents during training, which can be incrementally amplified via NIL. We provide a probabilistic model of NIL and an explanation of why the advantage of compositional language exist. Our experiments confirm our analysis, and also demonstrate that the emerged languages largely improve the generalizing power of the neural agent communication.
* accepted by ICLR-2020
Challenges in detecting evolutionary forces in language change using diachronic corpora
Nov 03, 2018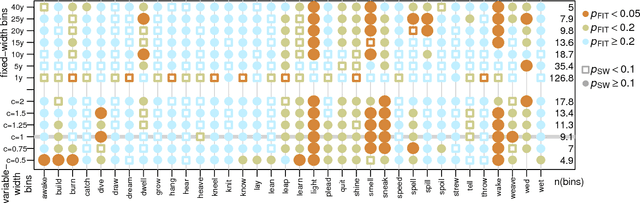
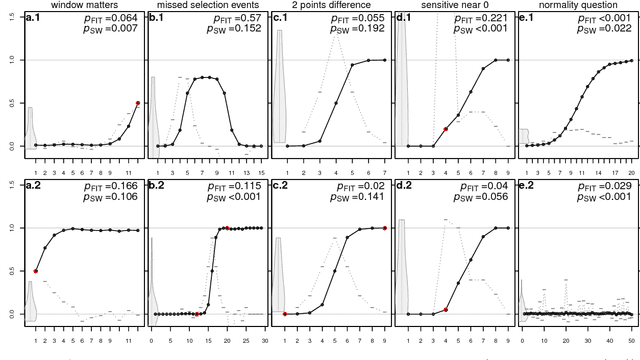

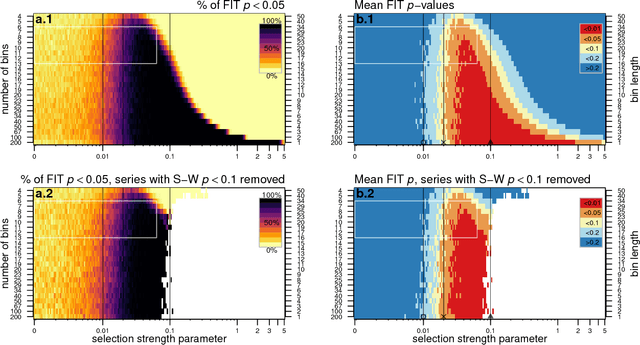
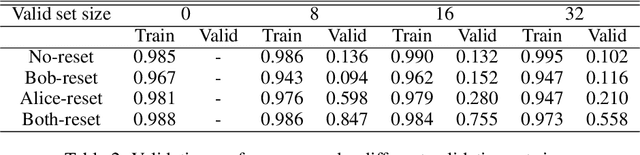
Newberry et al. (Detecting evolutionary forces in language change, Nature 551, 2017) tackle an important but difficult problem in linguistics, the testing of selective theories of language change against a null model of drift. Having applied a test from population genetics (the Frequency Increment Test) to a number of relevant examples, they suggest stochasticity has a previously under-appreciated role in language evolution. We replicate their results and find that while the overall observation holds, results produced by this approach on individual time series are highly sensitive to how the corpus is organized into temporal segments (binning). Furthermore, we use a large set of simulations in conjunction with binning to systematically explore the range of applicability of the FIT. The approach proposed by Newberry et al. provides a systematic way of generating hypotheses about language change, marking another step forward in big-data driven linguistic research. However, along with the possibilities, the limitations of the approach need to be appreciated. Caution should be exercised with interpreting results of the FIT (and similar tests) on individual series, given the demonstrable limitations, and fundamental differences between genetic and linguistic data. Our findings also have implications for selection testing and temporal binning in general.
The cognitive roots of regularization in language
Oct 18, 2018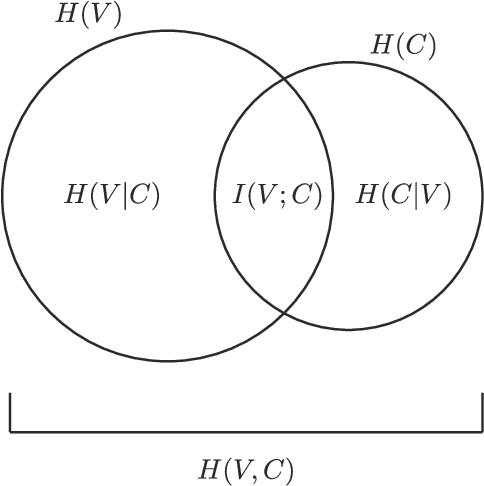
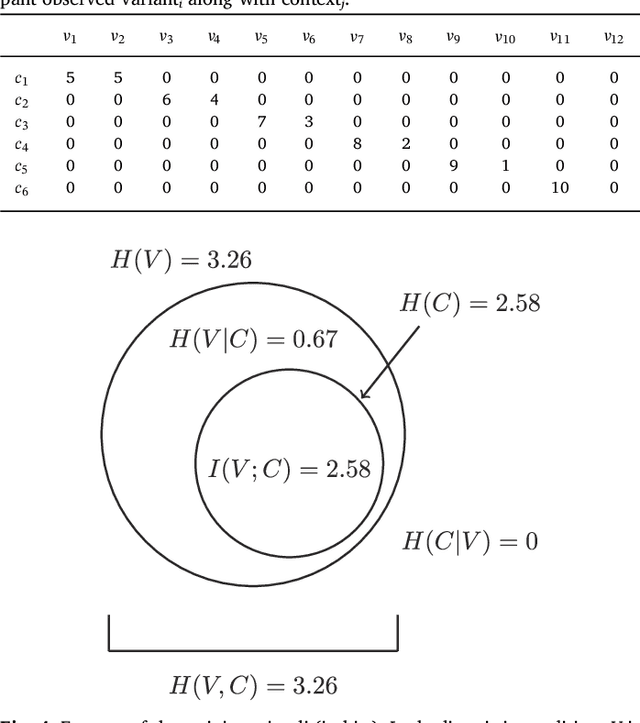
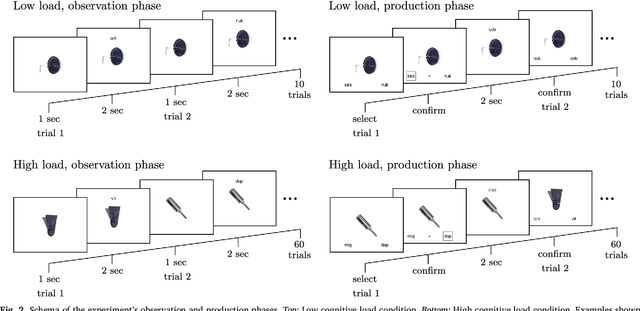
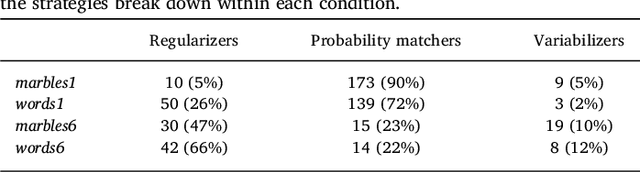
Regularization occurs when the output a learner produces is less variable than the linguistic data they observed. In an artificial language learning experiment, we show that there exist at least two independent sources of regularization bias in cognition: a domain-general source based on cognitive load and a domain-specific source triggered by linguistic stimuli. Both of these factors modulate how frequency information is encoded and produced, but only the production-side modulations result in regularization (i.e. cause learners to eliminate variation from the observed input). We formalize the definition of regularization as the reduction of entropy and find that entropy measures are better at identifying regularization behavior than frequency-based analyses. Using our experimental data and a model of cultural transmission, we generate predictions for the amount of regularity that would develop in each experimental condition if the artificial language were transmitted over several generations of learners. Here we find that the effect of cognitive constraints can become more complex when put into the context of cultural evolution: although learning biases certainly carry information about the course of language evolution, we should not expect a one-to-one correspondence between the micro-level processes that regularize linguistic datasets and the macro-level evolution of linguistic regularity.
Quantifying the dynamics of topical fluctuations in language
Jun 13, 2018
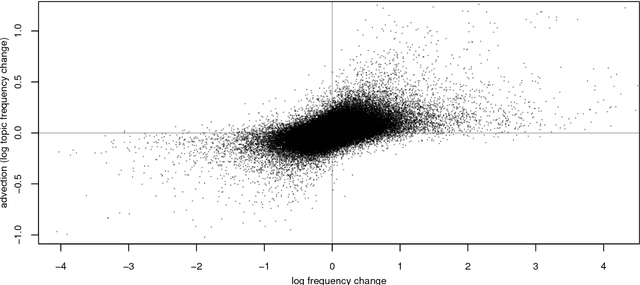
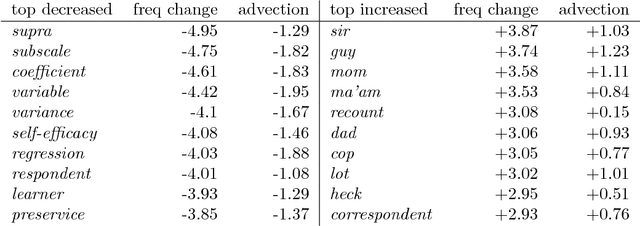
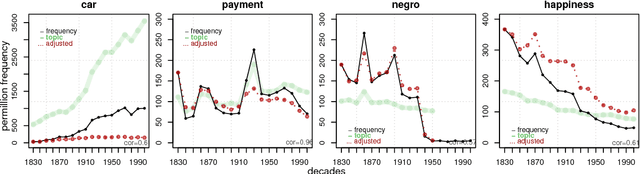
The availability of large diachronic corpora has provided the impetus for a growing body of quantitative research on language evolution and meaning change. The central quantities in this research are token frequencies of linguistic elements in the texts, with changes in frequency taken to reflect the popularity or selective fitness of an element. However, corpus frequencies may change for a wide variety of reasons, including purely random sampling effects, or because corpora are composed of contemporary media and fiction texts within which the underlying topics ebb and flow with cultural and socio-political trends. In this work, we introduce a computationally simple model for controlling for topical fluctuations in corpora - the topical-cultural advection model - and demonstrate how it provides a robust baseline of variability in word frequency changes over time. We validate the model on a diachronic corpus spanning two centuries, and a carefully-controlled artificial language change scenario, and then use it to correct for topical fluctuations in historical time series. Finally, we show that the model can be used to show that emergence of new words typically corresponds with the rise of a trending topic. This suggests that some lexical innovations occur due to growing communicative need in a subspace of the lexicon, and that the topical-cultural advection model can be used to quantify this.