 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting individual differences to bootstrap communication
Apr 07, 2025


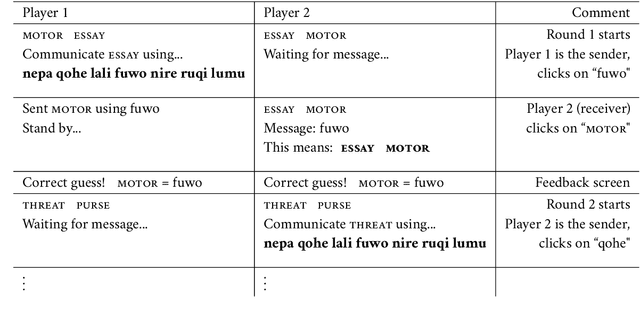
Establishing a communication system is hard because the intended meaning of a signal is unknown to its receiver when first produced, and the signaller also has no idea how that signal will be interpreted. Most theoretical accounts of the emergence of communication systems rely on feedback to reinforce behaviours that have led to successful communication in the past. However, providing such feedback requires already being able to communicate the meaning that was intended or interpreted. Therefore these accounts cannot explain how communication can be bootstrapped from non-communicative behaviours. Here we present a model that shows how a communication system, capable of expressing an unbounded number of meanings, can emerge as a result of individual behavioural differences in a large population without any pre-existing means to determine communicative success. The two key cognitive capabilities responsible for this outcome are behaving predictably in a given situation, and an alignment of psychological states ahead of signal production that derives from shared intentionality. Since both capabilities can exist independently of communication, our results are compatible with theories in which large flexible socially-learned communication systems like language are the product of a general but well-developed capacity for social cognition.
Learning spatio-temporal patterns with Neural Cellular Automata
Oct 23, 2023

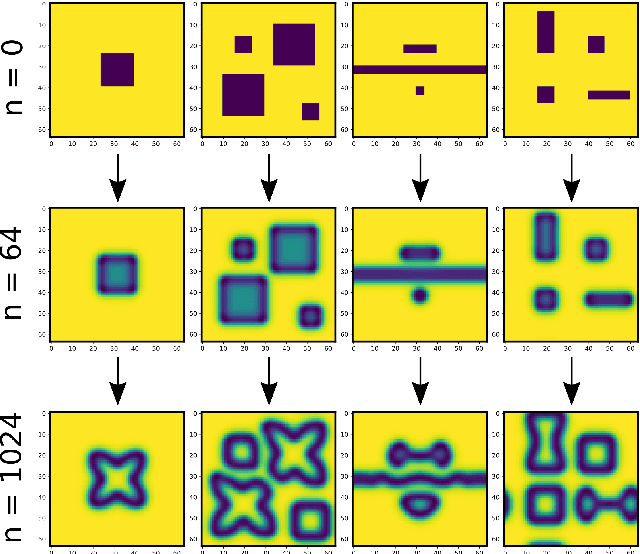

Neural Cellular Automata (NCA) are a powerful combination of machine learning and mechanistic modelling. We train NCA to learn complex dynamics from time series of images and PDE trajectories. Our method is designed to identify underlying local rules that govern large scale dynamic emergent behaviours. Previous work on NCA focuses on learning rules that give stationary emergent structures. We extend NCA to capture both transient and stable structures within the same system, as well as learning rules that capture the dynamics of Turing pattern formation in nonlinear Partial Differential Equations (PDEs). We demonstrate that NCA can generalise very well beyond their PDE training data, we show how to constrain NCA to respect given symmetries, and we explore the effects of associated hyperparameters on model performance and stability. Being able to learn arbitrary dynamics gives NCA great potential as a data driven modelling framework, especially for modelling biological pattern formation.
Reliable identification of selection mechanisms in language change
May 25, 2023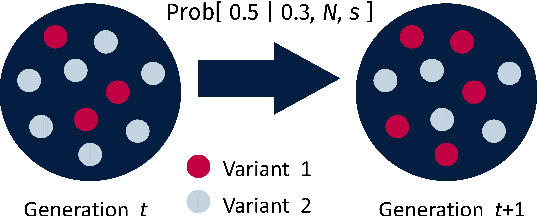

Language change is a cultural evolutionary process in which variants of linguistic variables change in frequency through processes analogous to mutation, selection and genetic drift. In this work, we apply a recently-introduced method to corpus data to quantify the strength of selection in specific instances of historical language change. We first demonstrate, in the context of English irregular verbs, that this method is more reliable and interpretable than similar methods that have previously been applied. We further extend this study to demonstrate that a bias towards phonological simplicity overrides that favouring grammatical simplicity when these are in conflict. Finally, with reference to Spanish spelling reforms, we show that the method can also detect points in time at which selection strengths change, a feature that is generically expected for socially-motivated language change. Together, these results indicate how hypotheses for mechanisms of language change can be tested quantitatively using historical corpus data.
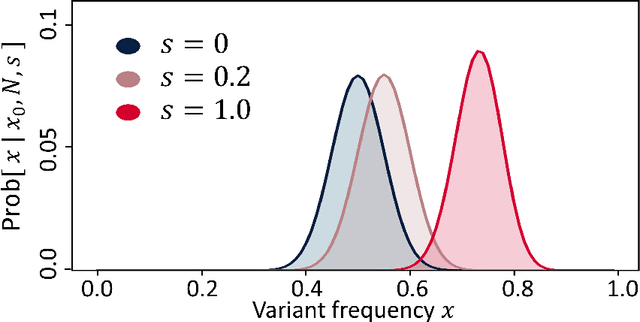
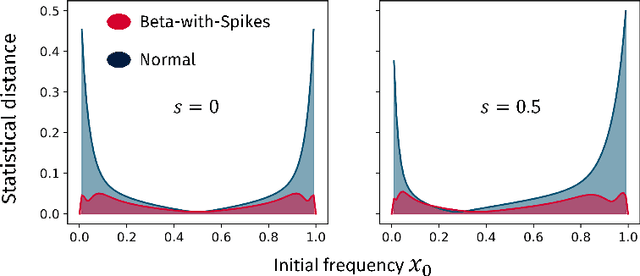
Self-contained Beta-with-Spikes Approximation for Inference Under a Wright-Fisher Model
Mar 08, 2023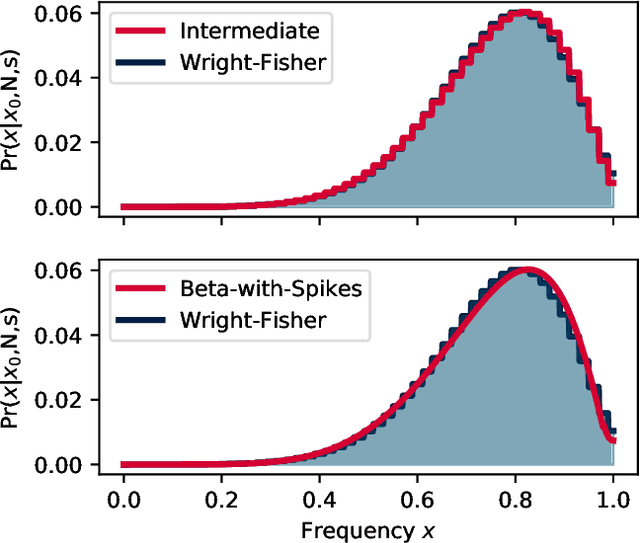
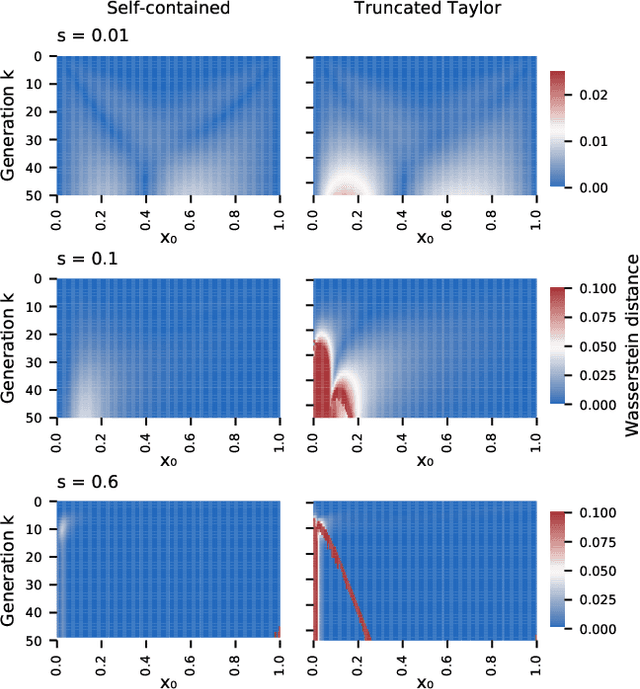
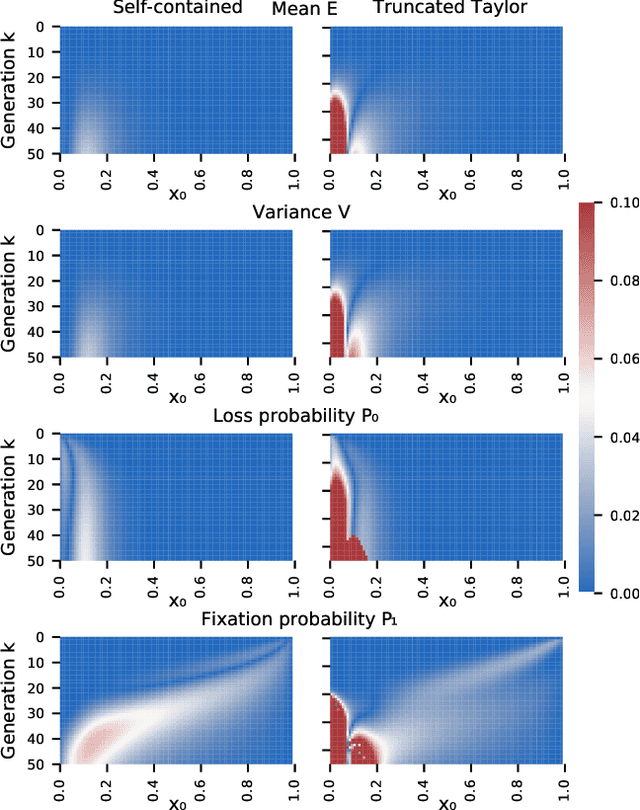
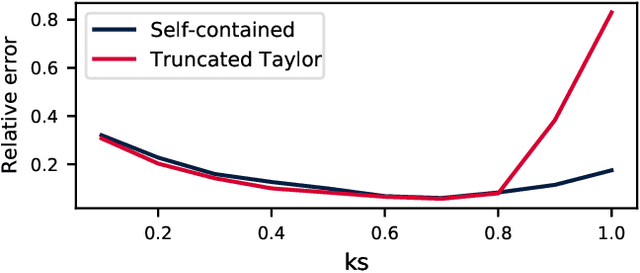
We construct a reliable estimation of evolutionary parameters within the Wright-Fisher model, which describes changes in allele frequencies due to selection and genetic drift, from time-series data. Such data exists for biological populations, for example via artificial evolution experiments, and for the cultural evolution of behavior, such as linguistic corpora that document historical usage of different words with similar meanings. Our method of analysis builds on a Beta-with-Spikes approximation to the distribution of allele frequencies predicted by the Wright-Fisher model. We introduce a self-contained scheme for estimating the parameters in the approximation, and demonstrate its robustness with synthetic data, especially in the strong-selection and near-extinction regimes where previous approaches fail. We further apply to allele frequency data for baker's yeast (Saccharomyces cerevisiae), finding a significant signal of selection in cases where independent evidence supports such a conclusion. We further demonstrate the possibility of detecting time-points at which evolutionary parameters change in the context of a historical spelling reform in the Spanish language.
Conceptual similarity and communicative need shape colexification: an experimental study
Mar 19, 2021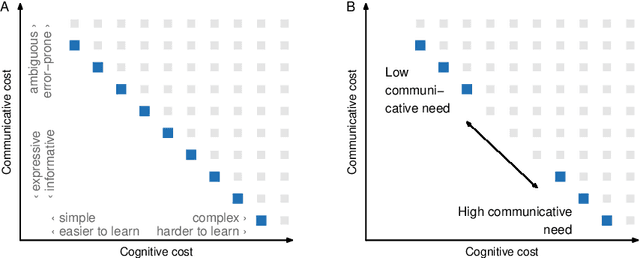
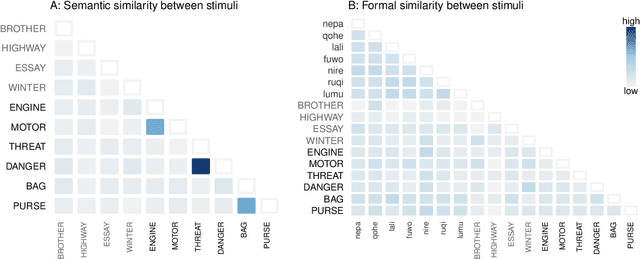

Colexification refers to the phenomenon of multiple meanings sharing one word in a language. Cross-linguistic lexification patterns have been shown to be largely predictable, as similar concepts are often colexified. We test a recent claim that, beyond this general tendency, communicative needs play an important role in shaping colexification patterns. We approach this question by means of a series of human experiments, using an artificial language communication game paradigm. Our results across four experiments match the previous cross-linguistic findings: all other things being equal, speakers do prefer to colexify similar concepts. However, we also find evidence supporting the communicative need hypothesis: when faced with a frequent need to distinguish similar pairs of meanings, speakers adjust their colexification preferences to maintain communicative efficiency, and avoid colexifying those similar meanings which need to be distinguished in communication. This research provides further evidence to support the argument that languages are shaped by the needs and preferences of their speakers.
Communicative need modulates competition in language change
Jun 16, 2020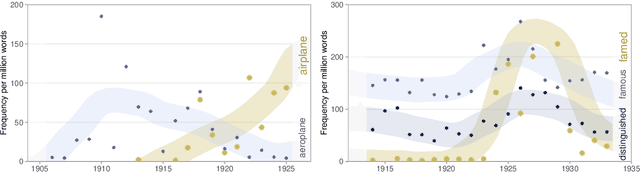
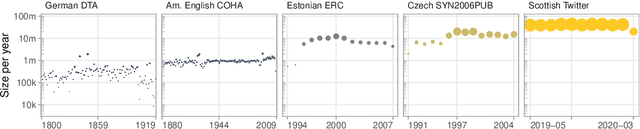
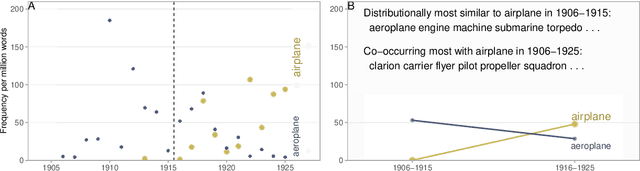
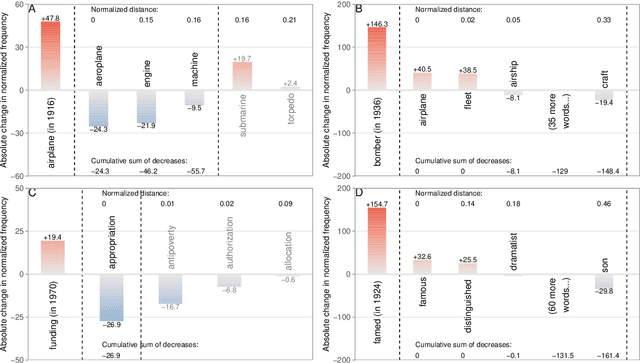
All living languages change over time. The causes for this are many, one being the emergence and borrowing of new linguistic elements. Competition between the new elements and older ones with a similar semantic or grammatical function may lead to speakers preferring one of them, and leaving the other to go out of use. We introduce a general method for quantifying competition between linguistic elements in diachronic corpora which does not require language-specific resources other than a sufficiently large corpus. This approach is readily applicable to a wide range of languages and linguistic subsystems. Here, we apply it to lexical data in five corpora differing in language, type, genre, and time span. We find that changes in communicative need are consistently predictive of lexical competition dynamics. Near-synonymous words are more likely to directly compete if they belong to a topic of conversation whose importance to language users is constant over time, possibly leading to the extinction of one of the competing words. By contrast, in topics which are increasing in importance for language users, near-synonymous words tend not to compete directly and can coexist. This suggests that, in addition to direct competition between words, language change can be driven by competition between topics or semantic subspaces.
Challenges in detecting evolutionary forces in language change using diachronic corpora
Nov 03, 2018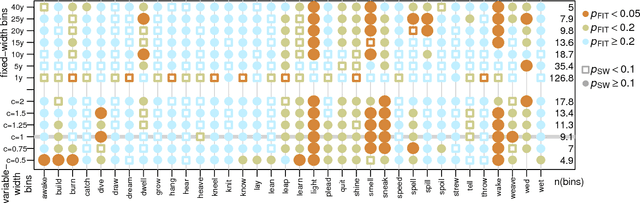
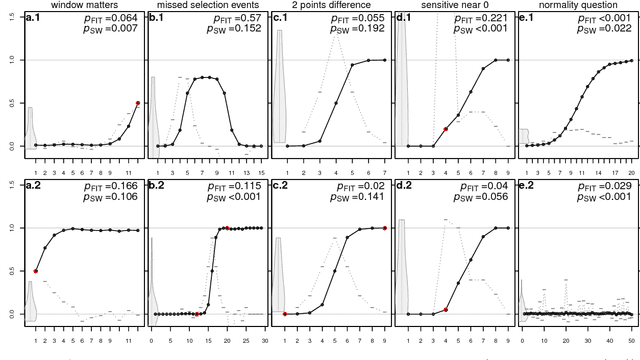

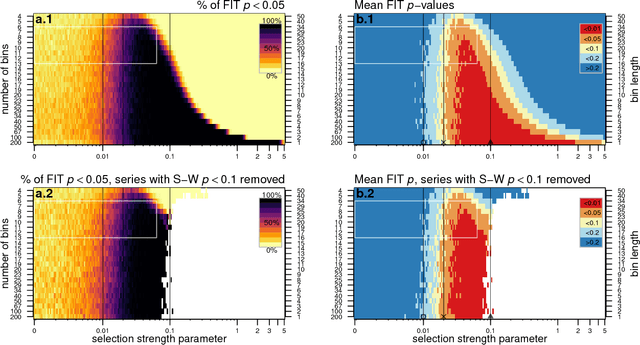
Newberry et al. (Detecting evolutionary forces in language change, Nature 551, 2017) tackle an important but difficult problem in linguistics, the testing of selective theories of language change against a null model of drift. Having applied a test from population genetics (the Frequency Increment Test) to a number of relevant examples, they suggest stochasticity has a previously under-appreciated role in language evolution. We replicate their results and find that while the overall observation holds, results produced by this approach on individual time series are highly sensitive to how the corpus is organized into temporal segments (binning). Furthermore, we use a large set of simulations in conjunction with binning to systematically explore the range of applicability of the FIT. The approach proposed by Newberry et al. provides a systematic way of generating hypotheses about language change, marking another step forward in big-data driven linguistic research. However, along with the possibilities, the limitations of the approach need to be appreciated. Caution should be exercised with interpreting results of the FIT (and similar tests) on individual series, given the demonstrable limitations, and fundamental differences between genetic and linguistic data. Our findings also have implications for selection testing and temporal binning in general.
Cross-situational learning of large lexicons with finite memory
Sep 28, 2018



Cross-situational word learning, wherein a learner combines information about possible meanings of a word across multiple exposures, has previously been shown to be a very powerful strategy to acquire a large lexicon in a short time. However, this success may derive from idealizations that are made when modeling the word-learning process. In particular, an earlier model assumed that a learner could perfectly recall all previous instances of a word's use and the inferences that were drawn about its meaning. In this work, we relax this assumption and determine the performance of a model cross-situational learner who forgets word-meaning associations over time. Our main finding is that it is possible for this learner to acquire a human-scale lexicon by adulthood with word-exposure and memory-decay rates that are consistent with empirical research on childhood word learning, as long as the degree of referential uncertainty is not too high or the learner employs a mutual exclusivity constraint. Our findings therefore suggest that successful word learning does not necessarily demand either highly accurate long-term tracking of word and meaning statistics or hypothesis-testing strategies.
Quantifying the dynamics of topical fluctuations in language
Jun 13, 2018
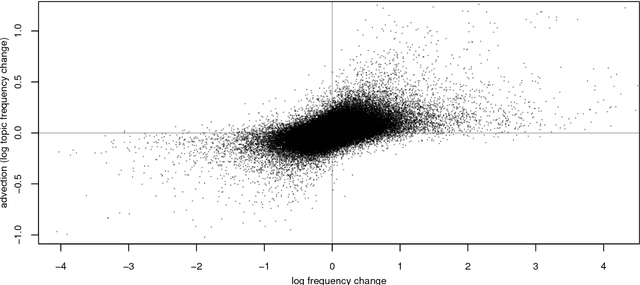
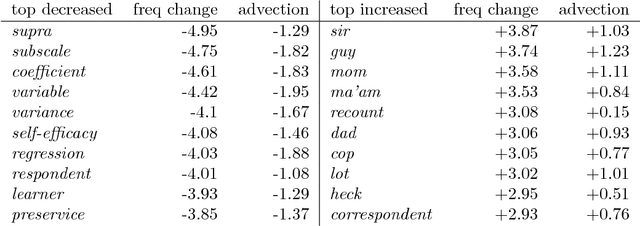
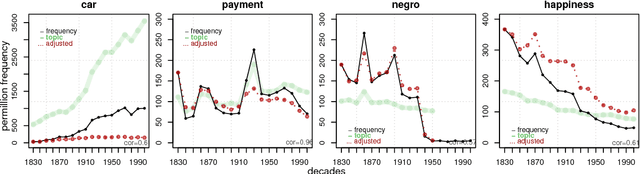
The availability of large diachronic corpora has provided the impetus for a growing body of quantitative research on language evolution and meaning change. The central quantities in this research are token frequencies of linguistic elements in the texts, with changes in frequency taken to reflect the popularity or selective fitness of an element. However, corpus frequencies may change for a wide variety of reasons, including purely random sampling effects, or because corpora are composed of contemporary media and fiction texts within which the underlying topics ebb and flow with cultural and socio-political trends. In this work, we introduce a computationally simple model for controlling for topical fluctuations in corpora - the topical-cultural advection model - and demonstrate how it provides a robust baseline of variability in word frequency changes over time. We validate the model on a diachronic corpus spanning two centuries, and a carefully-controlled artificial language change scenario, and then use it to correct for topical fluctuations in historical time series. Finally, we show that the model can be used to show that emergence of new words typically corresponds with the rise of a trending topic. This suggests that some lexical innovations occur due to growing communicative need in a subspace of the lexicon, and that the topical-cultural advection model can be used to quantify this.
Word learning under infinite uncertainty
Feb 10, 2016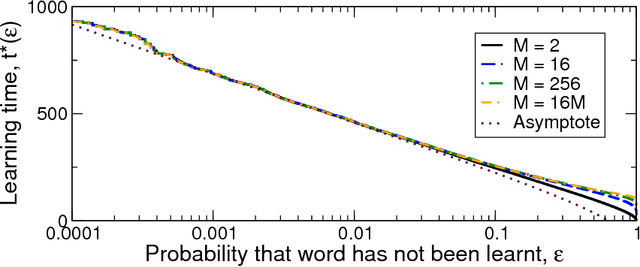
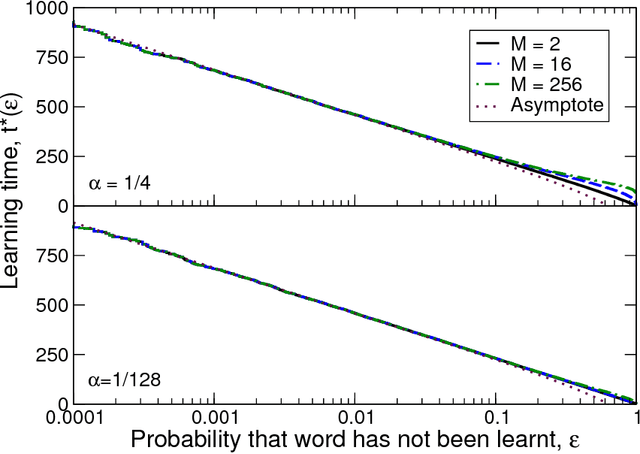
Language learners must learn the meanings of many thousands of words, despite those words occurring in complex environments in which infinitely many meanings might be inferred by the learner as a word's true meaning. This problem of infinite referential uncertainty is often attributed to Willard Van Orman Quine. We provide a mathematical formalisation of an ideal cross-situational learner attempting to learn under infinite referential uncertainty, and identify conditions under which word learning is possible. As Quine's intuitions suggest, learning under infinite uncertainty is in fact possible, provided that learners have some means of ranking candidate word meanings in terms of their plausibility; furthermore, our analysis shows that this ranking could in fact be exceedingly weak, implying that constraints which allow learners to infer the plausibility of candidate word meanings could themselves be weak. This approach lifts the burden of explanation from `smart' word learning constraints in learners, and suggests a programme of research into weak, unreliable, probabilistic constraints on the inference of word meaning in real word learners.
* 30 pages, 4 figures, contains considerable extra discussion and relaxation of original model assumptions. Version to appear in Cognition