 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe cognitive roots of regularization in language
Oct 18, 2018
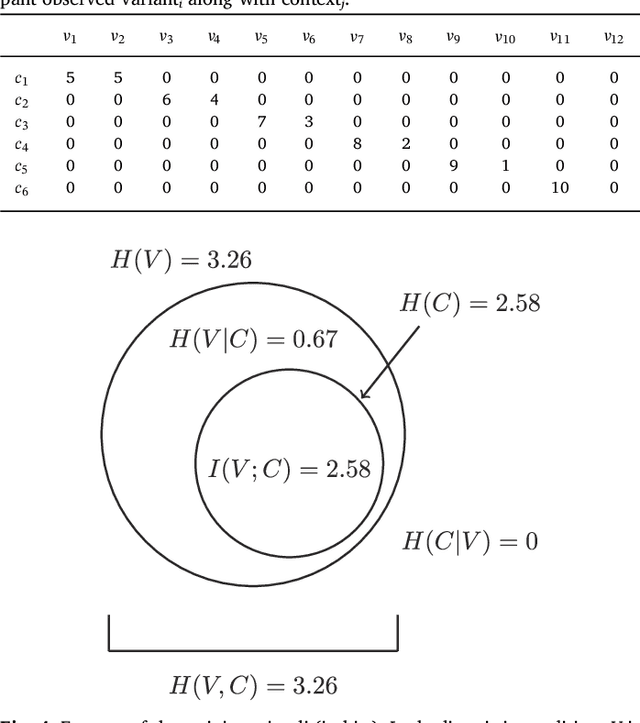
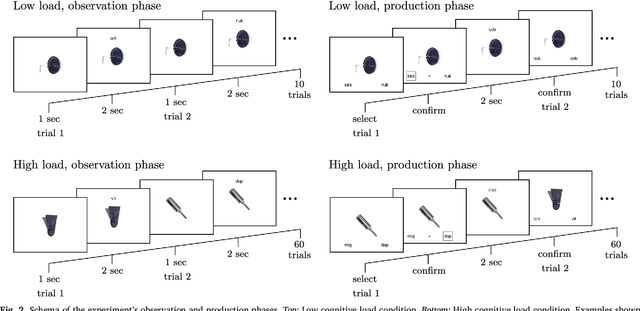
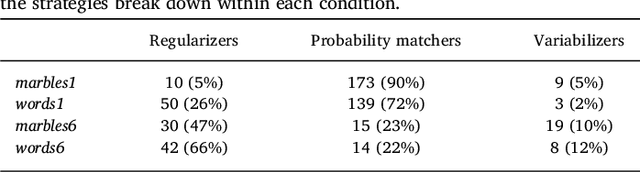
Regularization occurs when the output a learner produces is less variable than the linguistic data they observed. In an artificial language learning experiment, we show that there exist at least two independent sources of regularization bias in cognition: a domain-general source based on cognitive load and a domain-specific source triggered by linguistic stimuli. Both of these factors modulate how frequency information is encoded and produced, but only the production-side modulations result in regularization (i.e. cause learners to eliminate variation from the observed input). We formalize the definition of regularization as the reduction of entropy and find that entropy measures are better at identifying regularization behavior than frequency-based analyses. Using our experimental data and a model of cultural transmission, we generate predictions for the amount of regularity that would develop in each experimental condition if the artificial language were transmitted over several generations of learners. Here we find that the effect of cognitive constraints can become more complex when put into the context of cultural evolution: although learning biases certainly carry information about the course of language evolution, we should not expect a one-to-one correspondence between the micro-level processes that regularize linguistic datasets and the macro-level evolution of linguistic regularity.