 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI collective behavior needs an interactionist paradigm
Jan 15, 2026In this article, we argue that understanding the collective behavior of agents based on large language models (LLMs) is an essential area of inquiry, with important implications in terms of risks and benefits, impacting us as a society at many levels. We claim that the distinctive nature of LLMs--namely, their initialization with extensive pre-trained knowledge and implicit social priors, together with their capability of adaptation through in-context learning--motivates the need for an interactionist paradigm consisting of alternative theoretical foundations, methodologies, and analytical tools, in order to systematically examine how prior knowledge and embedded values interact with social context to shape emergent phenomena in multi-agent generative AI systems. We propose and discuss four directions that we consider crucial for the development and deployment of LLM-based collectives, focusing on theory, methods, and trans-disciplinary dialogue.
Group size effects and collective misalignment in LLM multi-agent systems
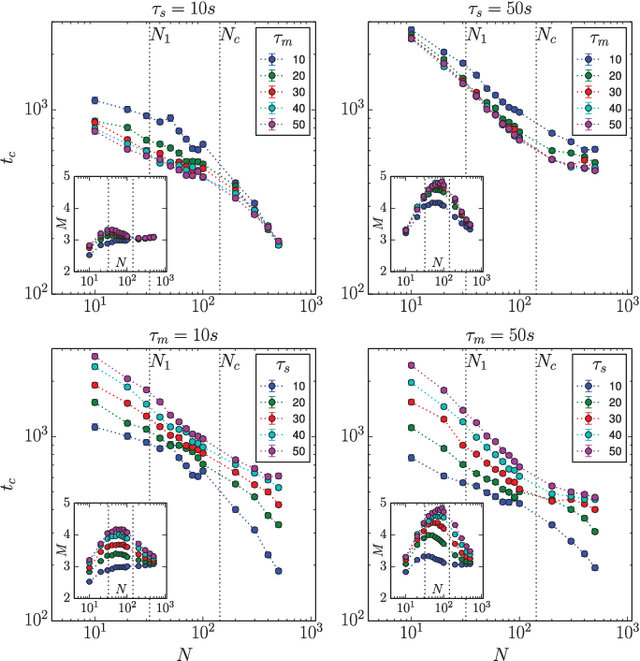
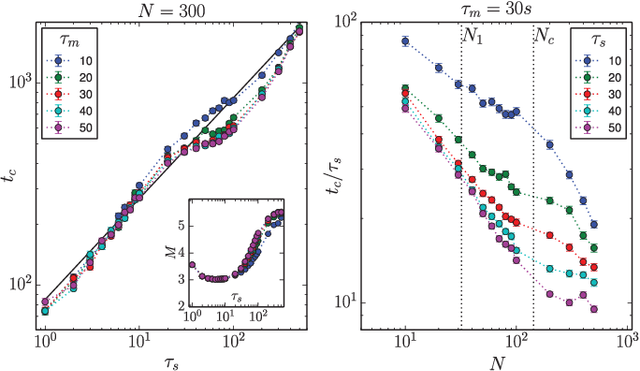
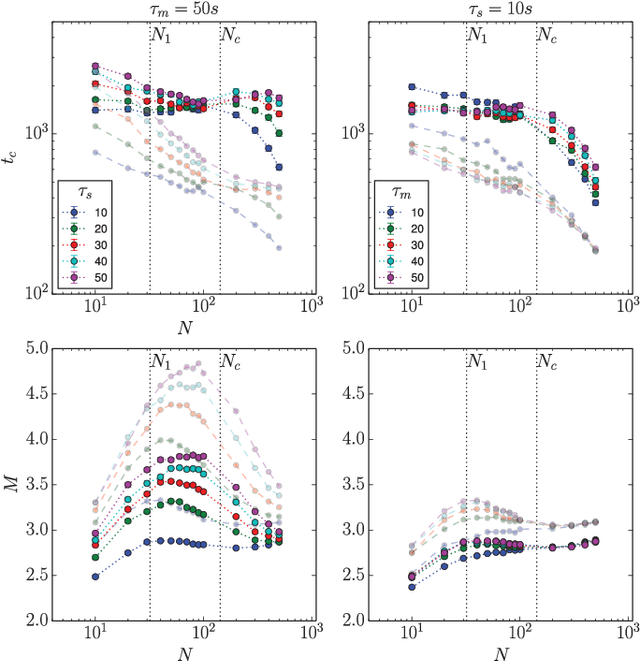
Oct 25, 2025Multi-agent systems of large language models (LLMs) are rapidly expanding across domains, introducing dynamics not captured by single-agent evaluations. Yet, existing work has mostly contrasted the behavior of a single agent with that of a collective of fixed size, leaving open a central question: how does group size shape dynamics? Here, we move beyond this dichotomy and systematically explore outcomes across the full range of group sizes. We focus on multi-agent misalignment, building on recent evidence that interacting LLMs playing a simple coordination game can generate collective biases absent in individual models. First, we show that collective bias is a deeper phenomenon than previously assessed: interaction can amplify individual biases, introduce new ones, or override model-level preferences. Second, we demonstrate that group size affects the dynamics in a non-linear way, revealing model-dependent dynamical regimes. Finally, we develop a mean-field analytical approach and show that, above a critical population size, simulations converge to deterministic predictions that expose the basins of attraction of competing equilibria. These findings establish group size as a key driver of multi-agent dynamics and highlight the need to consider population-level effects when deploying LLM-based systems at scale.
The Dynamics of Social Conventions in LLM populations: Spontaneous Emergence, Collective Biases and Tipping Points
Oct 11, 2024Social conventions are the foundation for social and economic life. As legions of AI agents increasingly interact with each other and with humans, their ability to form shared conventions will determine how effectively they will coordinate behaviors, integrate into society and influence it. Here, we investigate the dynamics of conventions within populations of Large Language Model (LLM) agents using simulated interactions. First, we show that globally accepted social conventions can spontaneously arise from local interactions between communicating LLMs. Second, we demonstrate how strong collective biases can emerge during this process, even when individual agents appear to be unbiased. Third, we examine how minority groups of committed LLMs can drive social change by establishing new social conventions. We show that once these minority groups reach a critical size, they can consistently overturn established behaviors. In all cases, contrasting the experimental results with predictions from a minimal multi-agent model allows us to isolate the specific role of LLM agents. Our results clarify how AI systems can autonomously develop norms without explicit programming and have implications for designing AI systems that align with human values and societal goals.
Machine Learning meets Number Theory: The Data Science of Birch-Swinnerton-Dyer
Nov 04, 2019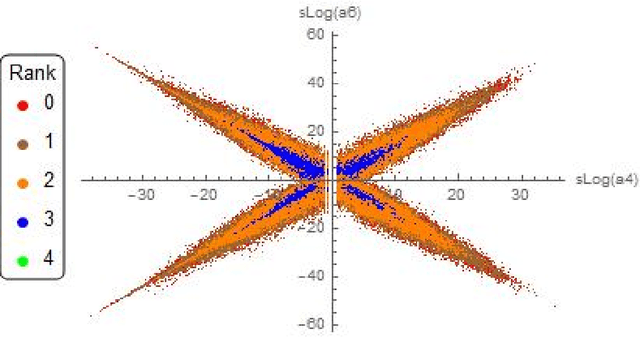
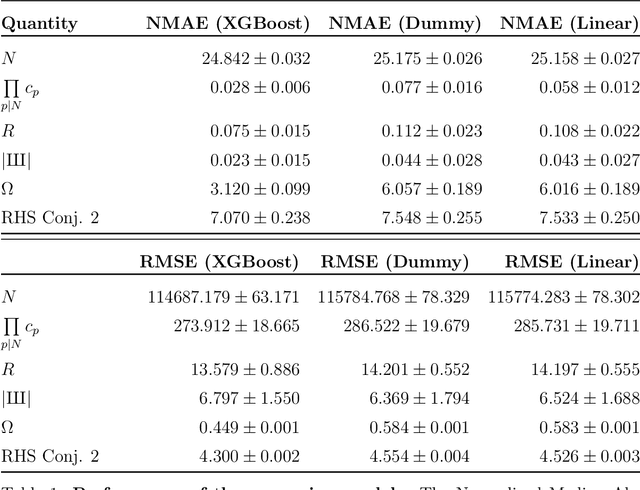
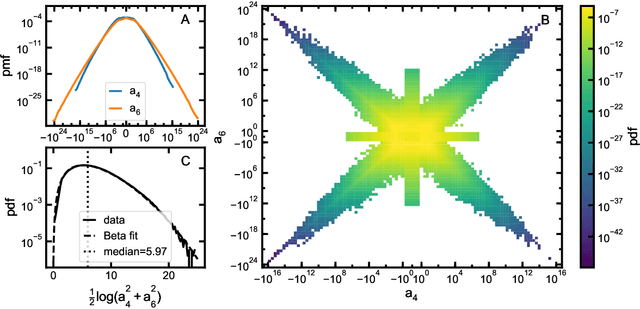
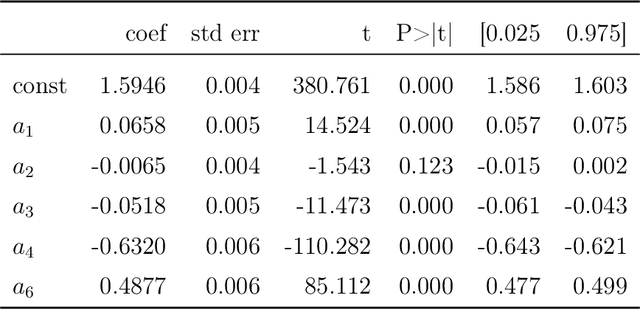
Empirical analysis is often the first step towards the birth of a conjecture. This is the case of the Birch-Swinnerton-Dyer (BSD) Conjecture describing the rational points on an elliptic curve, one of the most celebrated unsolved problems in mathematics. Here we extend the original empirical approach, to the analysis of the Cremona database of quantities relevant to BSD, inspecting more than 2.5 million elliptic curves by means of the latest techniques in data science, machine-learning and topological data analysis. Key quantities such as rank, Weierstrass coefficients, period, conductor, Tamagawa number, regulator and order of the Tate-Shafarevich group give rise to a high-dimensional point-cloud whose statistical properties we investigate. We reveal patterns and distributions in the rank versus Weierstrass coefficients, as well as the Beta distribution of the BSD ratio of the quantities. Via gradient boosted trees, machine learning is applied in finding inter-correlation amongst the various quantities. We anticipate that our approach will spark further research on the statistical properties of large datasets in Number Theory and more in general in pure Mathematics.
Emergence of Consensus in a Multi-Robot Network: from Abstract Models to Empirical Validation
Jan 19, 2016
Consensus dynamics in decentralised multiagent systems are subject to intense studies, and several different models have been proposed and analysed. Among these, the naming game stands out for its simplicity and applicability to a wide range of phenomena and applications, from semiotics to engineering. Despite the wide range of studies available, the implementation of theoretical models in real distributed systems is not always straightforward, as the physical platform imposes several constraints that may have a bearing on the consensus dynamics. In this paper, we investigate the effects of an implementation of the naming game for the kilobot robotic platform, in which we consider concurrent execution of games and physical interferences. Consensus dynamics are analysed in the light of the continuously evolving communication network created by the robots, highlighting how the different regimes crucially depend on the robot density and on their ability to spread widely in the experimental arena. We find that physical interferences reduce the benefits resulting from robot mobility in terms of consensus time, but also result in lower cognitive load for individual agents.
* A supporting video is available here: https://mail.google.com/mail/u/0/#search/vito.trianni%40istc.cnr.it/15244cd6f27f0e99?projector=1
Individual Biases, Cultural Evolution, and the Statistical Nature of Language Universals: The Case of Colour Naming Systems
Jun 23, 2015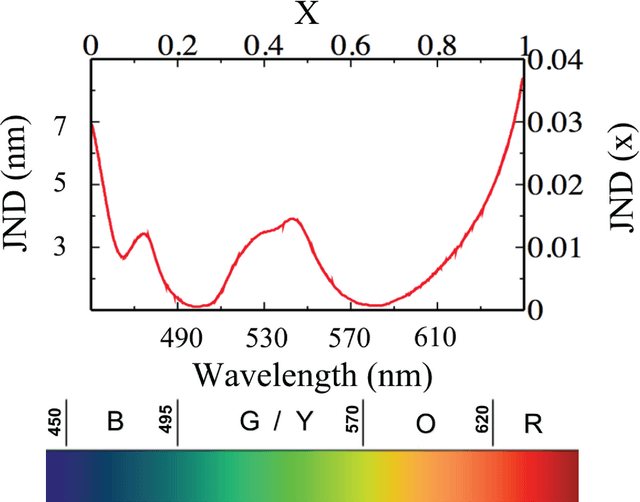



Language universals have long been attributed to an innate Universal Grammar. An alternative explanation states that linguistic universals emerged independently in every language in response to shared cognitive or perceptual biases. A computational model has recently shown how this could be the case, focusing on the paradigmatic example of the universal properties of colour naming patterns, and producing results in quantitative agreement with the experimental data. Here we investigate the role of an individual perceptual bias in the framework of the model. We study how, and to what extent, the structure of the bias influences the corresponding linguistic universal patterns. We show that the cultural history of a group of speakers introduces population-specific constraints that act against the pressure for uniformity arising from the individual bias, and we clarify the interplay between these two forces.
The Twitter of Babel: Mapping World Languages through Microblogging Platforms
Dec 20, 2012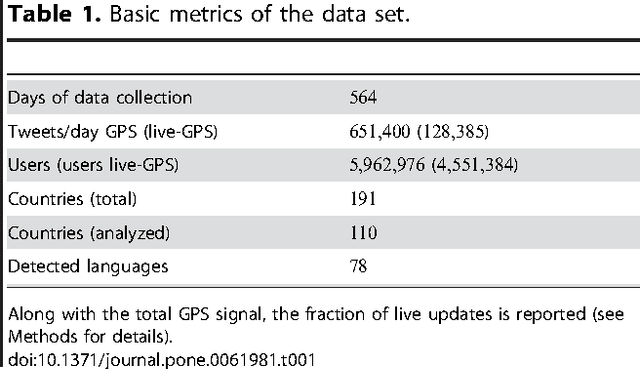
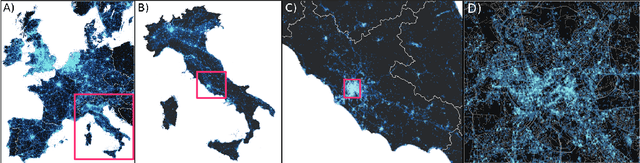
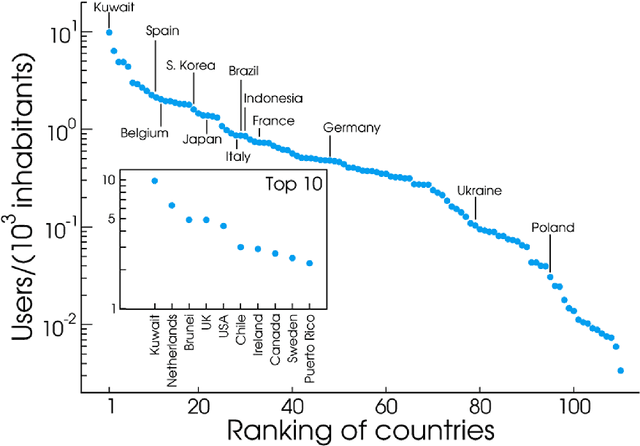
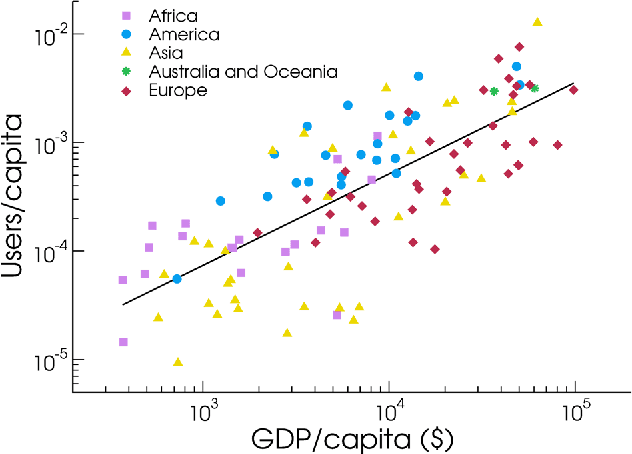
Large scale analysis and statistics of socio-technical systems that just a few short years ago would have required the use of consistent economic and human resources can nowadays be conveniently performed by mining the enormous amount of digital data produced by human activities. Although a characterization of several aspects of our societies is emerging from the data revolution, a number of questions concerning the reliability and the biases inherent to the big data "proxies" of social life are still open. Here, we survey worldwide linguistic indicators and trends through the analysis of a large-scale dataset of microblogging posts. We show that available data allow for the study of language geography at scales ranging from country-level aggregation to specific city neighborhoods. The high resolution and coverage of the data allows us to investigate different indicators such as the linguistic homogeneity of different countries, the touristic seasonal patterns within countries and the geographical distribution of different languages in multilingual regions. This work highlights the potential of geolocalized studies of open data sources to improve current analysis and develop indicators for major social phenomena in specific communities.
Aging in language dynamics
Jan 14, 2011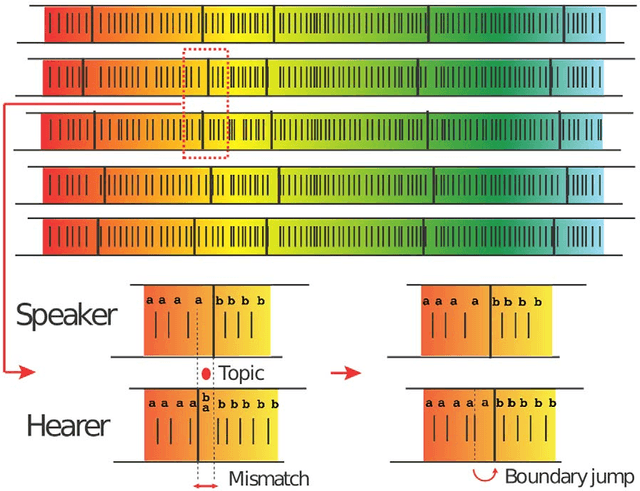
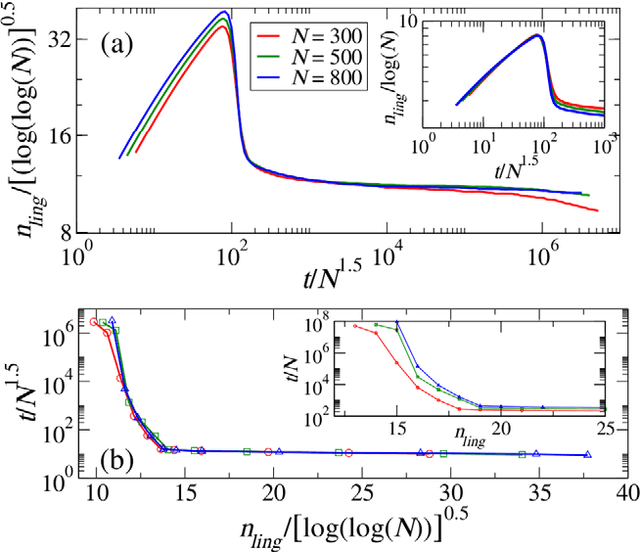
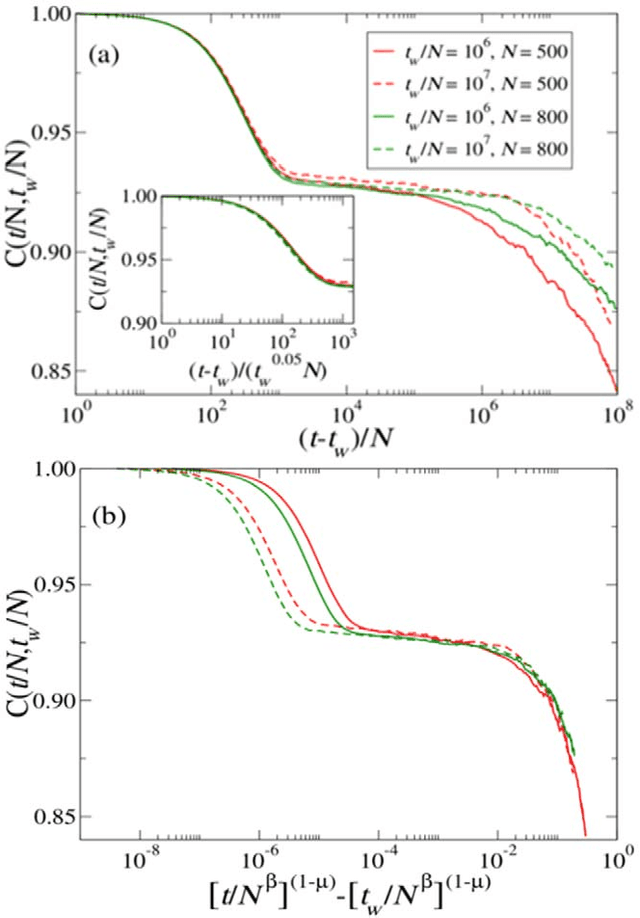

Human languages evolve continuously, and a puzzling problem is how to reconcile the apparent robustness of most of the deep linguistic structures we use with the evidence that they undergo possibly slow, yet ceaseless, changes. Is the state in which we observe languages today closer to what would be a dynamical attractor with statistically stationary properties or rather closer to a non-steady state slowly evolving in time? Here we address this question in the framework of the emergence of shared linguistic categories in a population of individuals interacting through language games. The observed emerging asymptotic categorization, which has been previously tested - with success - against experimental data from human languages, corresponds to a metastable state where global shifts are always possible but progressively more unlikely and the response properties depend on the age of the system. This aging mechanism exhibits striking quantitative analogies to what is observed in the statistical mechanics of glassy systems. We argue that this can be a general scenario in language dynamics where shared linguistic conventions would not emerge as attractors, but rather as metastable states.
* 15 pages, 6 figures. Accepted for publication in PLoS ONE
Artificial Sequences and Complexity Measures
Jan 25, 2006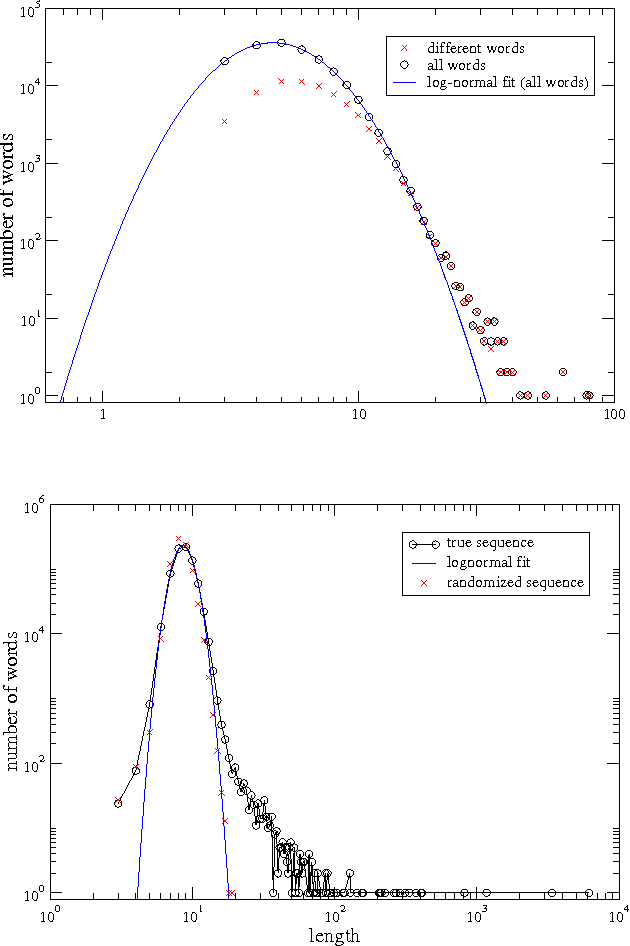
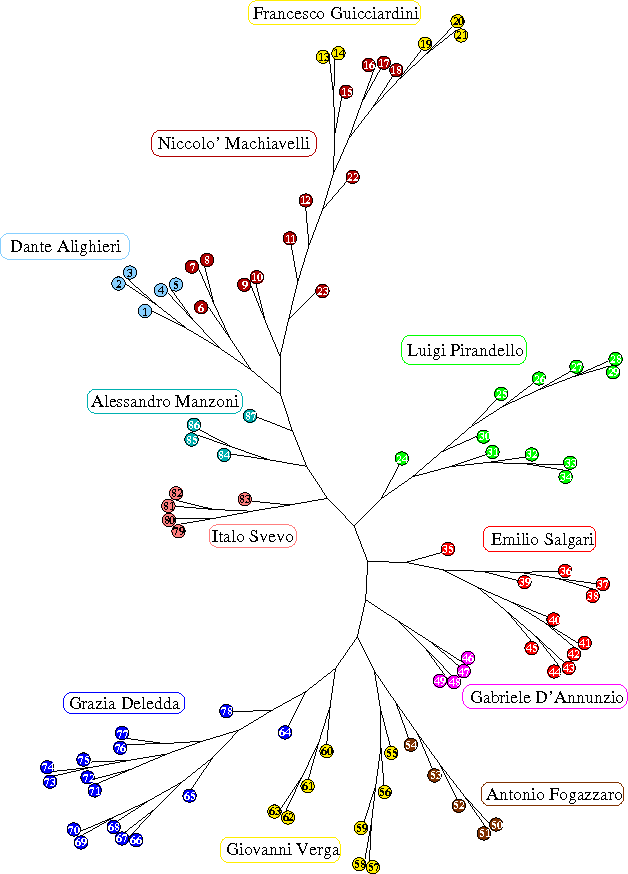
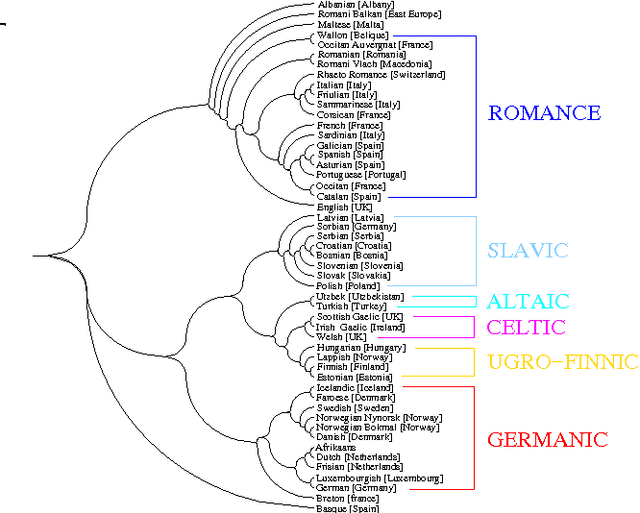

In this paper we exploit concepts of information theory to address the fundamental problem of identifying and defining the most suitable tools to extract, in a automatic and agnostic way, information from a generic string of characters. We introduce in particular a class of methods which use in a crucial way data compression techniques in order to define a measure of remoteness and distance between pairs of sequences of characters (e.g. texts) based on their relative information content. We also discuss in detail how specific features of data compression techniques could be used to introduce the notion of dictionary of a given sequence and of Artificial Text and we show how these new tools can be used for information extraction purposes. We point out the versatility and generality of our method that applies to any kind of corpora of character strings independently of the type of coding behind them. We consider as a case study linguistic motivated problems and we present results for automatic language recognition, authorship attribution and self consistent-classification.
* Revised version, with major changes, of previous "Data Compression approach to Information Extraction and Classification" by A. Baronchelli and V. Loreto. 15 pages; 5 figures