 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Sequences and Complexity Measures
Jan 25, 2006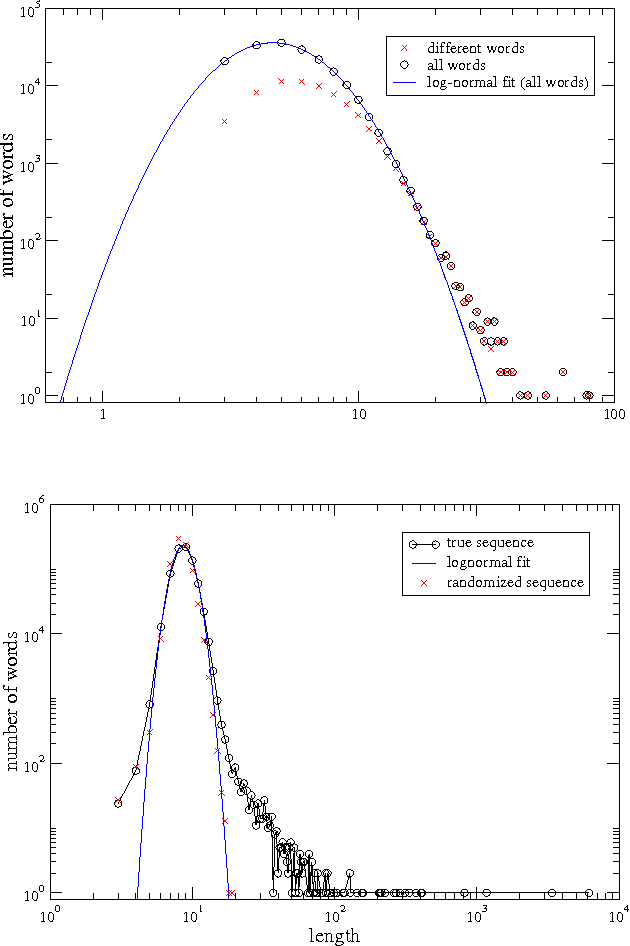
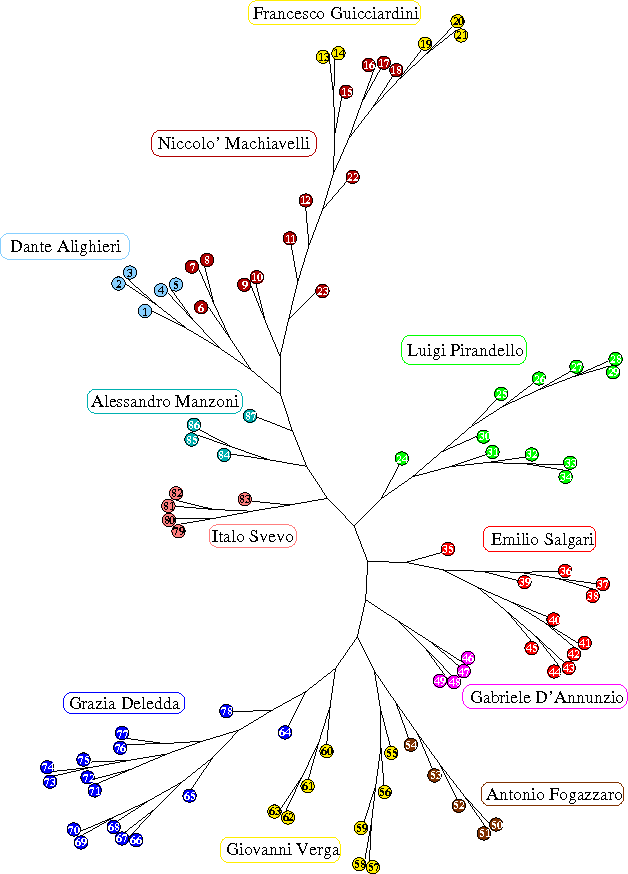
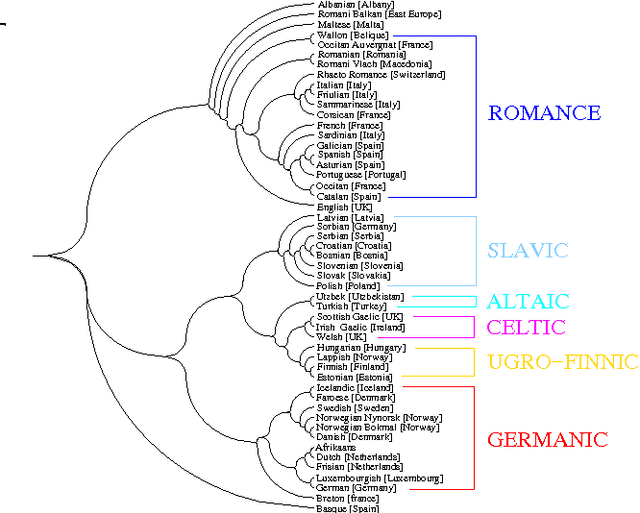

In this paper we exploit concepts of information theory to address the fundamental problem of identifying and defining the most suitable tools to extract, in a automatic and agnostic way, information from a generic string of characters. We introduce in particular a class of methods which use in a crucial way data compression techniques in order to define a measure of remoteness and distance between pairs of sequences of characters (e.g. texts) based on their relative information content. We also discuss in detail how specific features of data compression techniques could be used to introduce the notion of dictionary of a given sequence and of Artificial Text and we show how these new tools can be used for information extraction purposes. We point out the versatility and generality of our method that applies to any kind of corpora of character strings independently of the type of coding behind them. We consider as a case study linguistic motivated problems and we present results for automatic language recognition, authorship attribution and self consistent-classification.
* Revised version, with major changes, of previous "Data Compression approach to Information Extraction and Classification" by A. Baronchelli and V. Loreto. 15 pages; 5 figures