 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Branching Policies for MILPs with Proximal Policy Optimization
Nov 17, 2025Branch-and-Bound (B\&B) is the dominant exact solution method for Mixed Integer Linear Programs (MILP), yet its exponential time complexity poses significant challenges for large-scale instances. The growing capabilities of machine learning have spurred efforts to improve B\&B by learning data-driven branching policies. However, most existing approaches rely on Imitation Learning (IL), which tends to overfit to expert demonstrations and struggles to generalize to structurally diverse or unseen instances. In this work, we propose Tree-Gate Proximal Policy Optimization (TGPPO), a novel framework that employs Proximal Policy Optimization (PPO), a Reinforcement Learning (RL) algorithm, to train a branching policy aimed at improving generalization across heterogeneous MILP instances. Our approach builds on a parameterized state space representation that dynamically captures the evolving context of the search tree. Empirical evaluations show that TGPPO often outperforms existing learning-based policies in terms of reducing the number of nodes explored and improving p-Primal-Dual Integrals (PDI), particularly in out-of-distribution instances. These results highlight the potential of RL to develop robust and adaptable branching strategies for MILP solvers.
Strategic Deflection: Defending LLMs from Logit Manipulation
Jul 29, 2025With the growing adoption of Large Language Models (LLMs) in critical areas, ensuring their security against jailbreaking attacks is paramount. While traditional defenses primarily rely on refusing malicious prompts, recent logit-level attacks have demonstrated the ability to bypass these safeguards by directly manipulating the token-selection process during generation. We introduce Strategic Deflection (SDeflection), a defense that redefines the LLM's response to such advanced attacks. Instead of outright refusal, the model produces an answer that is semantically adjacent to the user's request yet strips away the harmful intent, thereby neutralizing the attacker's harmful intent. Our experiments demonstrate that SDeflection significantly lowers Attack Success Rate (ASR) while maintaining model performance on benign queries. This work presents a critical shift in defensive strategies, moving from simple refusal to strategic content redirection to neutralize advanced threats.
A multimodal LLM for the non-invasive decoding of spoken text from brain recordings
Sep 29, 2024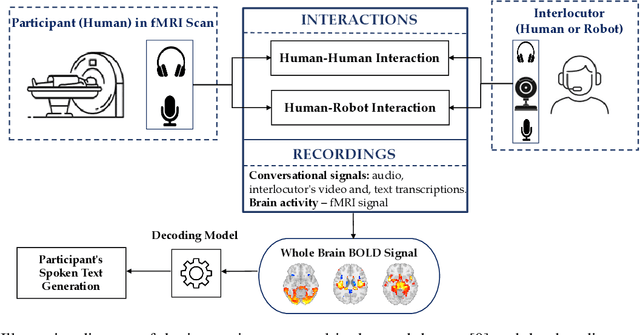



Brain-related research topics in artificial intelligence have recently gained popularity, particularly due to the expansion of what multimodal architectures can do from computer vision to natural language processing. Our main goal in this work is to explore the possibilities and limitations of these architectures in spoken text decoding from non-invasive fMRI recordings. Contrary to vision and textual data, fMRI data represent a complex modality due to the variety of brain scanners, which implies (i) the variety of the recorded signal formats, (ii) the low resolution and noise of the raw signals, and (iii) the scarcity of pretrained models that can be leveraged as foundation models for generative learning. These points make the problem of the non-invasive decoding of text from fMRI recordings very challenging. In this paper, we propose and end-to-end multimodal LLM for decoding spoken text from fMRI signals. The proposed architecture is founded on (i) an encoder derived from a specific transformer incorporating an augmented embedding layer for the encoder and a better-adjusted attention mechanism than that present in the state of the art, and (ii) a frozen large language model adapted to align the embedding of the input text and the encoded embedding of brain activity to decode the output text. A benchmark in performed on a corpus consisting of a set of interactions human-human and human-robot interactions where fMRI and conversational signals are recorded synchronously. The obtained results are very promising, as our proposal outperforms the evaluated models, and is able to generate text capturing more accurate semantics present in the ground truth. The implementation code is provided in https://github.com/Hmamouche/brain_decode.
miditok: A Python package for MIDI file tokenization
Oct 26, 2023
Recent progress in natural language processing has been adapted to the symbolic music modality. Language models, such as Transformers, have been used with symbolic music for a variety of tasks among which music generation, modeling or transcription, with state-of-the-art performances. These models are beginning to be used in production products. To encode and decode music for the backbone model, they need to rely on tokenizers, whose role is to serialize music into sequences of distinct elements called tokens. MidiTok is an open-source library allowing to tokenize symbolic music with great flexibility and extended features. It features the most popular music tokenizations, under a unified API. It is made to be easily used and extensible for everyone.
Sliding Window Neural Generated Tracking Based on Measurement Model
Jun 10, 2023
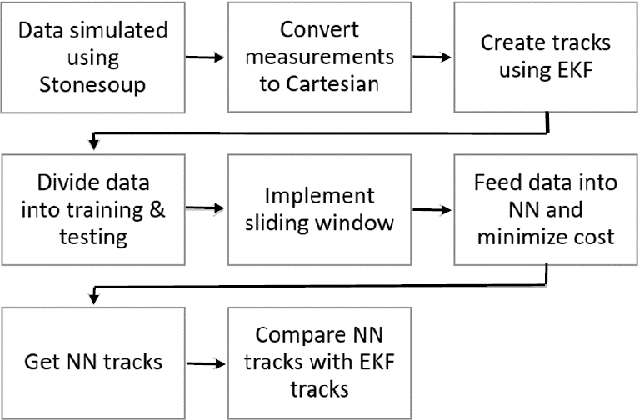
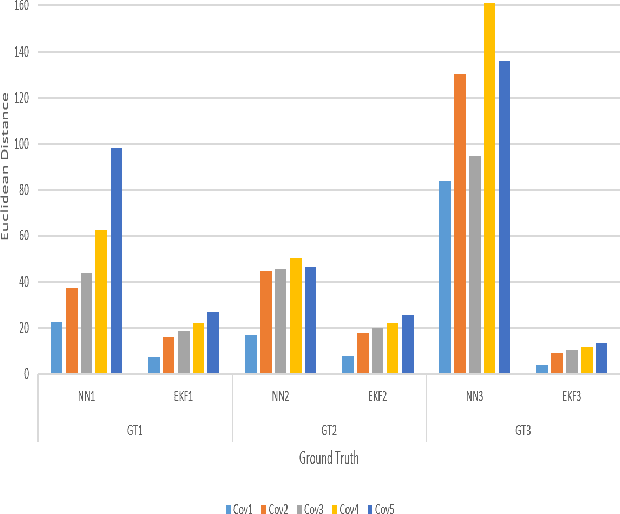

In the pursuit of further advancement in the field of target tracking, this paper explores the efficacy of a feedforward neural network in predicting drones tracks, aiming to eventually, compare the tracks created by the well-known Kalman filter and the ones created by our proposed neural network. The unique feature of our proposed neural network tracker is that it is using only a measurement model to estimate the next states of the track. Object model selection and linearization is one of the challenges that always face in the tracking process. The neural network uses a sliding window to incorporate the history of measurements when applying estimations of the track values. The testing results are comparable to the ones generated by the Kalman filter, especially for the cases where there is low measurement covariance. The complexity of linearization is avoided when using this proposed model.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023



The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
An optimized fuzzy logic model for proactive maintenance
Dec 24, 2022

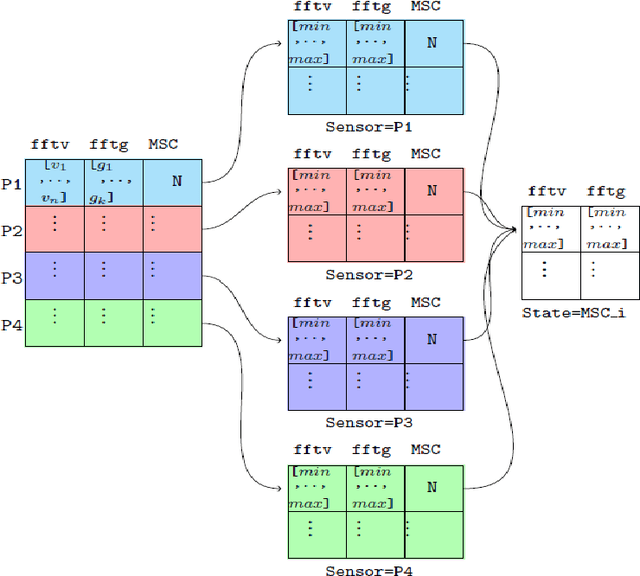

Fuzzy logic has been proposed in previous studies for machine diagnosis, to overcome different drawbacks of the traditional diagnostic approaches used. Among these approaches Failure Mode and Effect Critical Analysis method(FMECA) attempts to identify potential modes and treat failures before they occur based on subjective expert judgments. Although several versions of fuzzy logic are used to improve FMECA or to replace it, since it is an extremely cost-intensive approach in terms of failure modes because it evaluates each one of them separately, these propositions have not explicitly focused on the combinatorial complexity nor justified the choice of membership functions in Fuzzy logic modeling. Within this context, we develop an optimization-based approach referred to Integrated Truth Table and Fuzzy Logic Model (ITTFLM) that smartly generates fuzzy logic rules using Truth Tables. The ITTFLM was tested on fan data collected in real-time from a plant machine. In the experiment, three types of membership functions (Triangular, Trapezoidal, and Gaussian) were used. The ITTFLM can generate outputs in 5ms, the results demonstrate that this model based on the Trapezoidal membership functions identifies the failure states with high accuracy, and its capability of dealing with large numbers of rules and thus meets the real-time constraints that usually impact user experience.