 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Evolutionary Molecular Design: Adding Reinforcement Learning for Mutation Selection
Oct 01, 2025The efficient exploration of chemical space remains a central challenge, as many generative models still produce unstable or non-synthesizable compounds. To address these limitations, we present EvoMol-RL, a significant extension of the EvoMol evolutionary algorithm that integrates reinforcement learning to guide molecular mutations based on local structural context. By leveraging Extended Connectivity Fingerprints (ECFPs), EvoMol-RL learns context-aware mutation policies that prioritize chemically plausible transformations. This approach significantly improves the generation of valid and realistic molecules, reducing the frequency of structural artifacts and enhancing optimization performance. The results demonstrate that EvoMol-RL consistently outperforms its baseline in molecular pre-filtering realism. These results emphasize the effectiveness of combining reinforcement learning with molecular fingerprints to generate chemically relevant molecular structures.
miditok: A Python package for MIDI file tokenization
Oct 26, 2023
Recent progress in natural language processing has been adapted to the symbolic music modality. Language models, such as Transformers, have been used with symbolic music for a variety of tasks among which music generation, modeling or transcription, with state-of-the-art performances. These models are beginning to be used in production products. To encode and decode music for the backbone model, they need to rely on tokenizers, whose role is to serialize music into sequences of distinct elements called tokens. MidiTok is an open-source library allowing to tokenize symbolic music with great flexibility and extended features. It features the most popular music tokenizations, under a unified API. It is made to be easily used and extensible for everyone.
Impact of time and note duration tokenizations on deep learning symbolic music modeling
Oct 12, 2023



Symbolic music is widely used in various deep learning tasks, including generation, transcription, synthesis, and Music Information Retrieval (MIR). It is mostly employed with discrete models like Transformers, which require music to be tokenized, i.e., formatted into sequences of distinct elements called tokens. Tokenization can be performed in different ways. As Transformer can struggle at reasoning, but capture more easily explicit information, it is important to study how the way the information is represented for such model impact their performances. In this work, we analyze the common tokenization methods and experiment with time and note duration representations. We compare the performances of these two impactful criteria on several tasks, including composer and emotion classification, music generation, and sequence representation learning. We demonstrate that explicit information leads to better results depending on the task.
Byte Pair Encoding for Symbolic Music
Jan 27, 2023



The symbolic music modality is nowadays mostly represented as discrete and used with sequential models such as Transformers, for deep learning tasks. Recent research put efforts on the tokenization, i.e. the conversion of data into sequences of integers intelligible to such models. This can be achieved by many ways as music can be composed of simultaneous tracks, of simultaneous notes with several attributes. Until now, the proposed tokenizations are based on small vocabularies describing the note attributes and time events, resulting in fairly long token sequences. In this paper, we show how Byte Pair Encoding (BPE) can improve the results of deep learning models while improving its performances. We experiment on music generation and composer classification, and study the impact of BPE on how models learn the embeddings, and show that it can help to increase their isotropy, i.e., the uniformity of the variance of their positions in the space.
Partial Bandit and Semi-Bandit: Making the Most Out of Scarce Users' Feedback
Sep 16, 2020
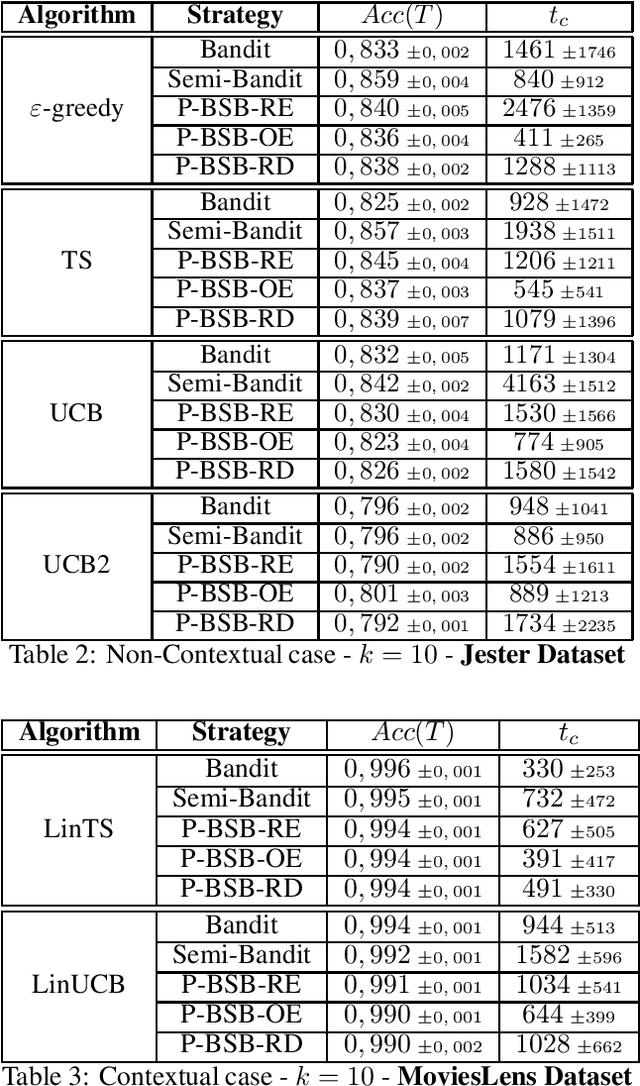
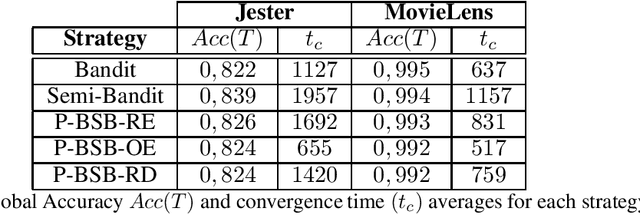
Recent works on Multi-Armed Bandits (MAB) and Combinatorial Multi-Armed Bandits (COM-MAB) show good results on a global accuracy metric. This can be achieved, in the case of recommender systems, with personalization. However, with a combinatorial online learning approach, personalization implies a large amount of user feedbacks. Such feedbacks can be hard to acquire when users need to be directly and frequently solicited. For a number of fields of activities undergoing the digitization of their business, online learning is unavoidable. Thus, a number of approaches allowing implicit user feedback retrieval have been implemented. Nevertheless, this implicit feedback can be misleading or inefficient for the agent's learning. Herein, we propose a novel approach reducing the number of explicit feedbacks required by Combinatorial Multi Armed bandit (COM-MAB) algorithms while providing similar levels of global accuracy and learning efficiency to classical competitive methods. In this paper we present a novel approach for considering user feedback and evaluate it using three distinct strategies. Despite a limited number of feedbacks returned by users (as low as 20% of the total), our approach obtains similar results to those of state of the art approaches.