 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multimodal LLM for the non-invasive decoding of spoken text from brain recordings
Sep 29, 2024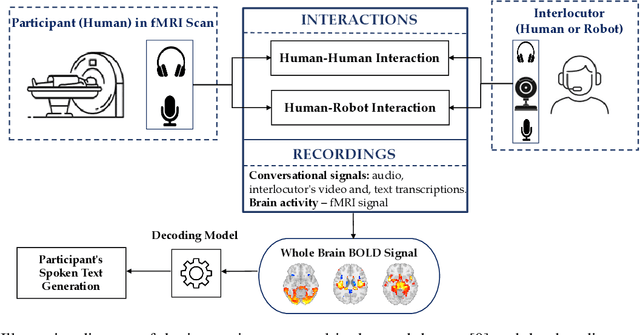



Brain-related research topics in artificial intelligence have recently gained popularity, particularly due to the expansion of what multimodal architectures can do from computer vision to natural language processing. Our main goal in this work is to explore the possibilities and limitations of these architectures in spoken text decoding from non-invasive fMRI recordings. Contrary to vision and textual data, fMRI data represent a complex modality due to the variety of brain scanners, which implies (i) the variety of the recorded signal formats, (ii) the low resolution and noise of the raw signals, and (iii) the scarcity of pretrained models that can be leveraged as foundation models for generative learning. These points make the problem of the non-invasive decoding of text from fMRI recordings very challenging. In this paper, we propose and end-to-end multimodal LLM for decoding spoken text from fMRI signals. The proposed architecture is founded on (i) an encoder derived from a specific transformer incorporating an augmented embedding layer for the encoder and a better-adjusted attention mechanism than that present in the state of the art, and (ii) a frozen large language model adapted to align the embedding of the input text and the encoded embedding of brain activity to decode the output text. A benchmark in performed on a corpus consisting of a set of interactions human-human and human-robot interactions where fMRI and conversational signals are recorded synchronously. The obtained results are very promising, as our proposal outperforms the evaluated models, and is able to generate text capturing more accurate semantics present in the ground truth. The implementation code is provided in https://github.com/Hmamouche/brain_decode.